How To Measure DORA Metrics
Track Deployment Frequency, Lead Time, Change Failure Rate and Time to Restore Service using SCM, CI/CD and incident data with automated baselines.
Read moreBlog posts in the Performance category

Track Deployment Frequency, Lead Time, Change Failure Rate and Time to Restore Service using SCM, CI/CD and incident data with automated baselines.
Read more
AI monitoring demands hybrid strategies to cut telemetry costs while improving detection speed and regulatory compliance.
Read more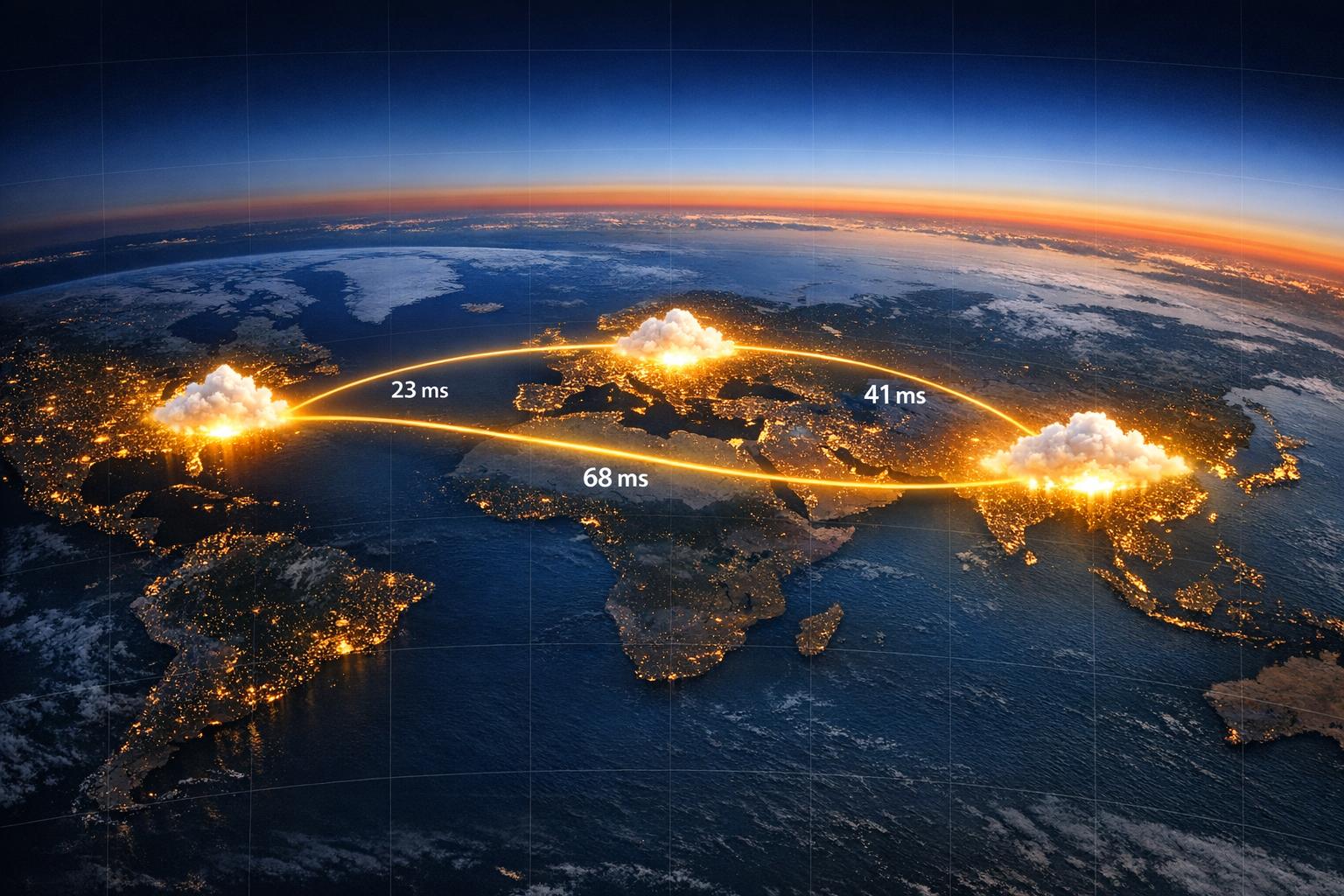
Practical strategies to reduce latency across AWS, Azure and GCP: region choice, private links, monitoring, routing and caching.
Read more
Keep core microservice functions running during failures using circuit breakers, fallbacks, timeouts, bulkheads and async workflows.
Read more
Practical checklist to reduce API gateway latency and costs: connection reuse, compression, caching, tuning, monitoring and scaling.
Read more
Embed observability, optimise queries, caching and storage, and add CI/CD checks and AI monitoring to cut latency and cloud costs in DevOps.
Read more
Kubernetes traffic splitting lowers deployment risk and cost by routing a small share to a canary, monitoring and enabling quick rollbacks.
Read more
AI predicts CI/CD failures by spotting signals in logs, tests and metrics — shifting teams from firefighting to prevention.
Read more
How CDN charges work and how to cut bills: bandwidth, request fees, cache misses, regional pricing, optimisation and monitoring.
Read more
Run fast, isolated unit tests early in CI/CD, use JUnit XML reports, parallelise suites and monitor flaky tests for reliable pipelines.
Read more
Manage service mesh configs using version control, preflight validation, staged rollouts, observability and fast rollback to avoid outages.
Read more
Troubleshoot CI/CD build failures with logs, local reproduction, linters and debug traces to reduce downtime and prevent repeats.
Read more
Practical, low-risk strategies for zero‑downtime Istio upgrades in large Kubernetes environments using canaries, parallel control planes and monitoring.
Read more
API gateways are the frontline for enforcing rate limits and throttling to protect backends and ensure fair traffic.
Read more
Retry and backoff best practices for distributed systems: exponential backoff with jitter, retry budgets, idempotency, and circuit breakers.
Read more
Automate smoke, load, stress and soak tests in your CI/CD pipeline to catch bottlenecks early and enforce p95, throughput and error gates.
Read more
Fix five common CI/CD pipeline problems—testing, complexity, environment drift, monitoring gaps and hardcoded secrets with practical fixes.
Read more
Use Terraform lifecycle rules, blue/green, rolling and canary strategies with health checks to update infrastructure without service interruptions.
Read more
Unified observability across on‑prem and public clouds with OpenTelemetry, RUM, synthetic tests and AI for proactive issue detection.
Read more
Compare AWS and Azure for multiplayer game hosting: performance, costs, GPUs, latency, scalability and UK region differences.
Read more
Narrow SLA definitions and capped credits can leave your business exposed—use this checklist to verify uptime, support and enforcement.
Read more
Unified logs, metrics and traces to cut hosting costs, reach 99.9% uptime and reduce MTTR from 45 to 8 minutes.
Read more
Low-cost distributed tracing for Kubernetes using object storage and a no‑index architecture; integrates with Prometheus and Loki.
Read more
Compare Consul and Istio on platform support, traffic control, observability, resource use and when to choose each.
Read more
GPU hourly rates in 2025 varied up to 10× by region and provider; spot pricing, egress and co-location drive 2–5× savings.
Read more
Build vendor reporting frameworks with KPIs, automation and AI to cut cloud costs, boost delivery and reduce incidents.
Read more
Latency and resource comparison of Istio, Linkerd and Consul — Linkerd leads in speed, Istio in features, Consul suits HashiCorp/hybrid setups.
Read more
Alert on four core CI/CD metrics to catch pipeline issues early and keep delivery fast and reliable.
Read more
Zero-downtime Kubernetes guide: rolling updates, readiness probes, blue‑green/canary releases, preStop hooks and Argo CD automation.
Read more
Practical guidance on forecasting, regional allocation, load balancing, multi‑CDN and real‑time monitoring to optimise CDN capacity, performance and cost.
Read more
Integrate metrics, logs and traces across CI/CD, apps and infrastructure to reduce downtime, speed incident response and lower observability costs.
Read more
Track cache hit ratio, TTFB and regional performance with edge logs, RUM and synthetic tests to detect issues, optimise delivery and cut CDN costs.
Read more
Measure and improve DORA lead time and deployment frequency with practical tips on measurement, CI/CD automation, trunk-based development and feature flags.
Read more
Compare five traffic‑shaping solutions for progressive delivery, covering routing, canary/blue‑green strategies, observability and resource trade-offs.
Read more
Compare rolling, blue‑green and canary deployments — downtime, cost, rollback speed and risk — to pick the best release strategy for your app.
Read more
Compare AWS, Azure, GCP, OCI and DigitalOcean latency, network design and optimisation tips focused on UK performance for low‑latency workloads.
Read more