
Balancing elasticity and data consistency in multi-region systems is a challenge that requires careful planning. Here's what you need to know:
Elasticity Defined: Multi-region elasticity allows systems to scale resources like compute, storage, and networking across various locations. This improves response times by placing workloads closer to users, but it complicates data synchronisation.
Data Consistency Trade-offs: The CAP theorem highlights that during network partitions, you must choose between availability and strict data consistency:
- **Strong consistency** ensures synchronised data but increases latency.
- **Eventual consistency** prioritises availability and low latency but risks serving outdated data temporarily.
- Replication Challenges:
- **Synchronous replication** guarantees consistency but adds latency.
- **Asynchronous replication** reduces delays but risks data lag.
Compliance Considerations: UK and EU data residency rules, such as GDPR, influence replication strategies. Keeping sensitive data local while replicating non-sensitive data globally can help meet these requirements.
Cost vs. Performance:
- Active-active setups provide instant failover but are expensive.
- Warm standby or pilot light configurations offer cost-effective alternatives with varying recovery times.
- Monitoring and Testing: Tracking replication lag and conducting regular failover tests ensures resilience and aligns with recovery objectives.
Key takeaway: To design an effective multi-region system, balance elasticity, consistency, and compliance while managing costs. Strategies like regional sharding, read local, write global
, and hybrid replication can help meet these goals. For UK businesses, aligning with GDPR while optimising cloud expenses is crucial.
Multi-Region Elasticity and Data Consistency: Core Concepts
What is Multi-Region Elasticity?
Multi-region elasticity describes a system's ability to dynamically scale compute, storage, and networking resources across multiple, geographically distinct cloud regions [3][6]. This ensures applications remain responsive and available, no matter where users are or what disruptions occur.
By placing workloads closer to users, you reduce latency and improve response times [5][4]. For example, a UK-based company serving customers in London, Frankfurt, and Singapore can scale each region independently based on local demand. This setup also isolates faults - if one region experiences a failure, it won't affect the others [5][6].
Modern tools like Kubernetes clusters, managed through services such as Amazon EKS, help coordinate compute resources across regions. Global load balancers intelligently direct traffic, ensuring efficient distribution [6]. Serverless platforms like AWS Lambda take care of scaling and availability automatically, but developers still need to manage how data is replicated between regions [6][7]. While cloud providers excel at scaling compute resources, the real challenge lies in synchronising data across regions without compromising consistency. Let’s explore how these scaling capabilities align with different data consistency models.
Data Consistency Models Explained
When distributing data across regions, the CAP theorem comes into play: network partitions force a choice between availability and consistency [3][2].
Strong consistency ensures that data writes are synchronised across multiple regions before they are confirmed. This approach prevents data loss but increases latency significantly, as data must travel vast distances. For instance, if a write operation in London waits for confirmation from Frankfurt, users will experience delays [3].
In contrast, eventual consistency uses asynchronous replication. Writes are first committed in the primary region and then propagated to others. This model prioritises low latency and high availability but risks returning out-of-date data in secondary regions until replication completes [3][2]. Amazon S3 Replication Time Control illustrates this trade-off, achieving 99.99% replication within 15 minutes, though most objects replicate in seconds [2].
Distributed systems often favour availability over strict consistency, resulting in eventual consistency models.- AWS Architecture Blog [2]
A common strategy here is the read local, write global
pattern, where writes occur in a central region and propagate asynchronously to others [3]. Another option is quorum-based writes, which require a majority (e.g., 2 out of 3 regions) to confirm before committing. This approach balances strong consistency with resilience, avoiding a single point of failure [3]. These consistency challenges become even more complex when considering regional compliance requirements.
UK and EU Data Residency Requirements
While GDPR doesn’t explicitly demand data localisation, it restricts cross-border data transfers, effectively encouraging localisation [8]. Many organisations opt to store and process data within the European Economic Area (EEA) to simplify compliance rather than navigate complex transfer mechanisms.
GDPR doesn't directly require data localisation, but it does impose limitations on data transfers that create localisation effects and could lead organisations to keep data within the EEA.- Louis DeNicola, Content Marketing Manager, Persona [8]
Post-Brexit, the UK Data Protection Act mirrors GDPR standards but applies them within the UK, recognising EEA countries as offering adequate protection [8]. Data transfers outside the EU or UK require an adequacy
decision from the European Commission. Additionally, a specific data bridge
exists between the UK and the U.S. to facilitate transfers [8].
These regulations influence replication strategies. For write-heavy workloads, regional sharding can ensure that EU users remain tied to EU regions, while UK users stay within UK regions [3]. Sensitive personal data can remain within its jurisdiction, while non-sensitive metadata might replicate globally. Tools like Amazon S3 Multi-Region Access Points or Azure Front Door automatically route traffic to the nearest compliant region while maintaining a single global endpoint [2][7].
Understanding the distinction between data residency and data sovereignty is crucial. Residency focuses on where data is physically stored, while sovereignty determines which country's laws govern the data, regardless of your company’s origin [9]. This distinction shapes how you design failover systems and decide which regions can serve as backups for regulated data.
How Elastic Scaling Affects Data Replication and Consistency
Synchronous vs Asynchronous Replication
When scaling your system across multiple regions, the choice between synchronous and asynchronous replication plays a crucial role in performance and consistency. With synchronous replication, the system ensures strong consistency by waiting for writes to be committed across all regions. However, this comes with a major drawback - write latency increases significantly compared to single-region operations [3].
When writes involve synchronous replication across multiple Regions to meet strong consistency requirements, write latency increases by an order of magnitude.- AWS Prescriptive Guidance [3]
On the other hand, asynchronous replication commits writes locally first and then propagates the changes to other regions. This approach keeps latency low and supports elastic scaling, even when dealing with long-distance delays. For example, Amazon Aurora Global Database achieves a replication lag of under one second using dedicated storage-based replication [2], while Amazon S3 Replication Time Control replicates 99.99% of objects within 15 minutes [2]. The downside? This method provides eventual consistency, meaning secondary regions might temporarily serve outdated data, and in-flight transactions could be lost during regional failures [3].
For high-performance workloads, strategies like read local, write global
can be further refined by separating compute scaling from replication constraints. However, this requires applications to handle temporary inconsistencies.
These replication approaches introduce challenges such as replication lag and write amplification, especially during elastic scaling.
Replication Lag and Write Amplification
As systems scale elastically, replication methods can become a bottleneck. The rapid expansion of compute resources - like Lambda functions, containers, or virtual machines - can outpace the replication capacity [6][11]. When the volume of writes exceeds what the replication setup can handle, replication lag grows, causing secondary regions to fall further behind the primary.
Another challenge is write amplification in multi-region setups. A single write to the primary database must be replicated to all secondary regions. In systems requiring strong consistency through quorum-based models (e.g., acknowledgements from two out of three regions), each write must traverse multiple geographic links simultaneously [3]. During traffic surges, this amplification can overwhelm network bandwidth and I/O capacity, leading to performance degradation.
Monitoring replication lag is critical. Native service metrics, such as those provided by Amazon CloudWatch, can help track lag [3][10]. If replication lag exceeds your Recovery Point Objective (RPO) during scaling events, consider throttling at the application layer or leveraging managed features like Aurora PostgreSQL's managed RPO
, which temporarily blocks writes until replication catches up [2].
Multi-Region Caches and Global Datastores
Multi-region caching solutions, like ElastiCache for Redis Global Datastore, can reduce database load but come with their own consistency challenges. Asynchronous replication in high-load scenarios can delay cache updates, leading to stale data [2][10].
For workloads requiring strict consistency, global caching might not be ideal during periods of high traffic. These solutions are better suited for read-heavy workloads that can tolerate eventual consistency, such as product catalogues or content delivery networks.
Some managed services address multi-region write complexity with write forwarding. For instance, Amazon Aurora MySQL allows secondary regions to accept write requests and automatically forward them to the primary writer [2]. This simplifies application logic and maintains a single source of truth, though it doesn’t eliminate the replication lag that arises during elastic scaling.
Balancing elasticity with consistency demands careful planning. Understanding how these factors impact performance is key to designing architectures that can handle both scalability and consistency requirements effectively.
Read and Write Data patterns for Multi-Region architectures
Designing Multi-Region Architectures for Elasticity and Consistency
After examining the challenges of replication, let’s dive into strategies for designing systems that balance elasticity with data consistency across multiple regions.
Selecting Data Models and Replication Strategies
The replication strategy you choose should align with your workload's tolerance for latency and potential inconsistency. Single-primary architectures, where one region processes all writes and other regions serve as read-only replicas, simplify consistency by using write-forwarding [2]. This setup is ideal for read-heavy workloads such as content management systems or product catalogues, where writes are relatively infrequent.
For applications that need global write capabilities, multi-active (multi-primary) architectures allow multiple regions to handle writes simultaneously. However, this approach introduces challenges like conflict resolution, which requires designing idempotent applications [3].
Another option is sharding users across regions, where each region operates as an independent cell.
This limits the impact of failures and reduces the need for global synchronisation [3]. For instance, data for European customers could be stored exclusively in EU regions, while US-based infrastructure handles North American customers. This method also aligns with data residency regulations like GDPR.
| Strategy | Consistency Model | Best For | Complexity |
|---|---|---|---|
| Single-Primary | Strong (primary) / Eventual (replicas) | Read-heavy workloads, content delivery | Low |
| Multi-Active | Eventual with conflict resolution | Global apps requiring local writes | High |
| Region-Sharded | Strong within region | Compliance-driven, isolated customer bases | Medium |
Each of these strategies provides a foundation for managing consistency, depending on your specific needs.
Eventual vs Strong Consistency: When to Use Each
With replication strategies in mind, choosing between eventual and strong consistency becomes critical for balancing performance and reliability. Eventual consistency prioritises availability and low latency, allowing local writes to commit quickly while replicating changes in the background. Services like Amazon Aurora and DynamoDB (in Multi-Region Eventual Consistency mode) use this model to scale efficiently [3]. This approach works well for read-heavy applications where slight delays in data updates are acceptable, such as social media feeds or recommendation engines.
On the other hand, strong consistency ensures no data loss by synchronising writes across regions, though this increases latency [3]. Applications like financial systems, inventory management, or booking platforms often demand this level of consistency to avoid issues like double-spending or overselling.
Since June 2025, some managed services have introduced native multi-region strong consistency. For example, DynamoDB's Multi-Region Strong Consistency (MRSC) mode offers a Recovery Point Objective (RPO) of zero, meaning no data loss during regional failures [12]. However, achieving this requires deploying across at least three regions (or two regions plus a witness) to maintain quorum during disruptions [12].
For many workloads, a hybrid approach strikes the right balance. Synchronous replication can be used within a region for high availability, while asynchronous replication across regions ensures disaster recovery [13]. This way, local operations remain fast, and geographic redundancy is maintained.
Implementing Idempotency and Compensating Transactions
To handle conflicts in multi-region systems, idempotency and compensating transactions are crucial. In architectures with asynchronous replication or multi-active writes, idempotency ensures that processing the same request multiple times yields the same outcome. This prevents issues like duplicate charges or inventory errors during replication delays [3].
One way to achieve idempotency is by designing APIs that use unique request IDs. This ensures that retries or duplicate requests are safely ignored or retried without unintended consequences.
For more complex workflows involving multiple services, compensating transactions and saga patterns can help maintain consistency. If a multi-step process fails - such as a payment succeeding but an inventory reservation failing - compensating transactions can roll back completed steps. This approach acknowledges the limitations of achieving ACID properties across regions and instead focuses on resilience through explicit rollback mechanisms.
When designing these architectures, it’s essential to define your Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO). As Tej Nagabhatla, Senior Solutions Architect at AWS, explains:
If a workload cannot withstand the loss of a single Availability Zone (AZ), replicating it to another region will simply replicate its vulnerabilities[4].
Ultimately, your architecture should be tailored to meet specific workload requirements rather than over-engineering for hypothetical scenarios.
For additional support, organisations can consult experts like Hokstad Consulting, who specialise in optimising cloud infrastructure and DevOps processes to improve data consistency and system elasticity.
Monitoring, Testing, and Optimising Consistency in Multi-Region Systems
::: @figure 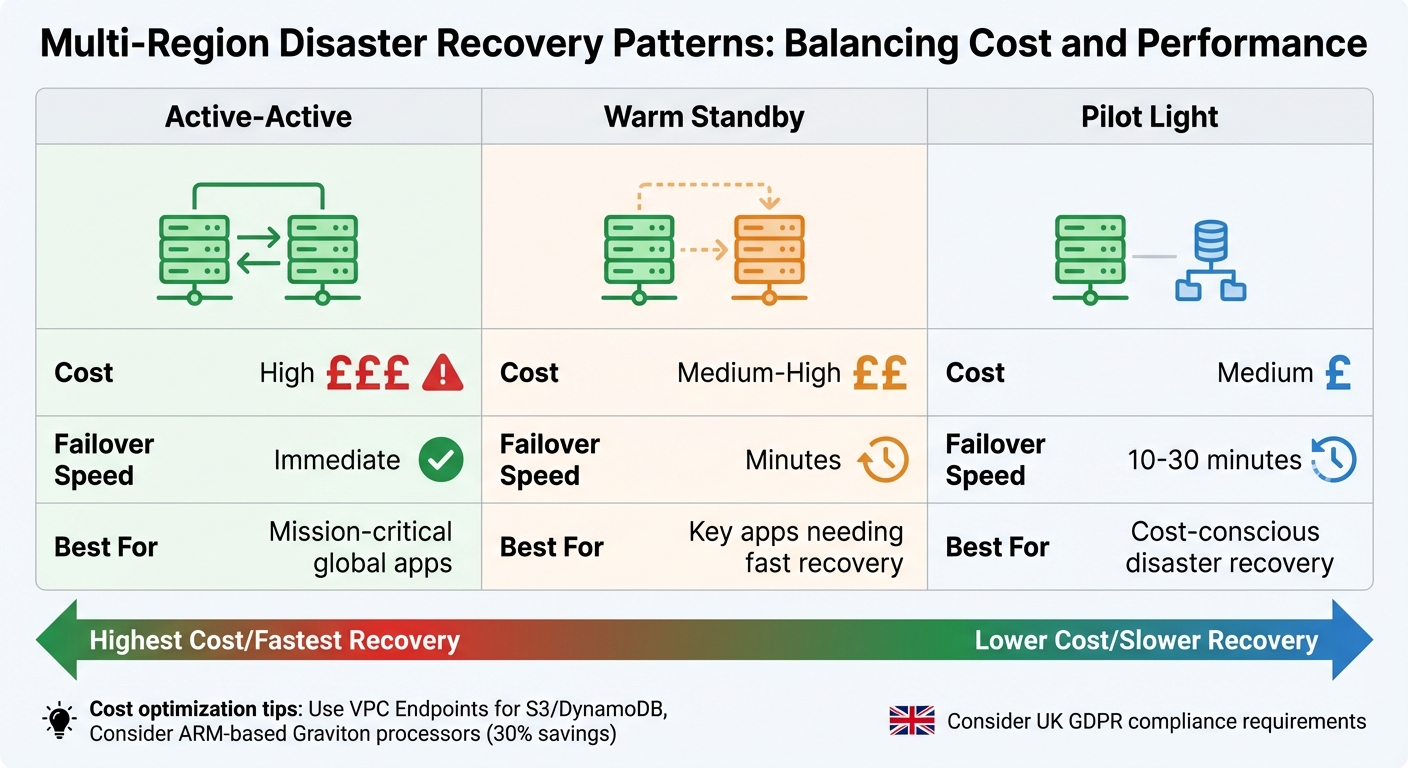 {Multi-Region Architecture Patterns: Cost vs Performance Comparison}
:::
{Multi-Region Architecture Patterns: Cost vs Performance Comparison}
:::
Building on earlier discussions about replication and consistency, this section explores how to keep tabs on, test, and fine-tune multi-region systems. Maintaining visibility into your architecture is key to addressing potential issues before they impact users.
Tracking Consistency Metrics
In multi-region systems, replication lag is the most critical metric to monitor. For MySQL, keep an eye on Seconds_Behind_Master, while PostgreSQL users should track replica_byte_lag to understand the potential for data loss during failover [16]. If you're using Amazon Aurora or DynamoDB, CloudWatch metrics can help you quickly detect anomalies in replication lag [3].
Amazon S3’s Replication Time Control (RTC) aims to replicate 99.99% of objects within 15 minutes, with most completed in seconds [2]. If your usual replication lag is around 2 seconds but suddenly jumps to 30 seconds, it's a clear signal to investigate.
Centralised monitoring tools are invaluable. Dashboards like Amazon EC2 Global View allow you to consolidate resources - VPCs, instances, subnets - across regions into a single interface [14]. This unified view helps you pinpoint whether an issue is isolated to one region or part of a larger, systemic problem. Additionally, when keeping an eye on costs, remember to monitor cross-region data transfer fees in pounds sterling, as these can climb rapidly with high replication volumes.
These metrics provide the foundation for the resilience tests covered next.
Chaos Engineering and Failover Testing
Failover testing is essential for ensuring recovery readiness. As AWS Prescriptive Guidance warns:
Having an untested recovery approach is equal to not having a recovery approach[17].
Resilience testing involves simulating failure scenarios - like region outages or increased latency - to assess how your application and recovery processes respond [17]. A stark reminder of the importance of robust failover mechanisms came during the AWS US-East-1 outage on 20th October 2025. A fault in the Elastic Load Balancer monitoring system caused incorrect health updates, triggering DNS failures for DynamoDB API endpoints and disrupting EC2, Lambda, and SQS for 15 hours. This incident underscored the value of Route 53 DNS failover policies for regional resilience [15].
Regularly rotating the active operating region, known as application rotation, ensures your recovery processes remain functional [17]. Failover testing under varying loads - during both peak and non-peak times - can reveal how the standby instance handles production traffic [16]. While the failover process itself should be fully automated, the decision to trigger it is often best left to humans, who can weigh the risks of data loss and consider the broader context [17].
Thorough testing not only improves resilience but also helps refine cost-performance trade-offs in disaster recovery plans.
Balancing Cost and Consistency Trade-Offs
For UK businesses aiming to reduce cloud expenses, choosing the right disaster recovery strategy is vital. The balance between cost and consistency often depends on the deployment pattern:
- Active-active setups offer instant failover but require running full capacity in multiple regions, making them expensive.
- Warm standby keeps a scaled-down secondary region that can be quickly scaled up during failures, reducing costs while maintaining relatively quick recovery.
- Pilot light keeps only the essential components running, offering the lowest cost but longer recovery times.
| Pattern | Cost | Failover Speed | Best For |
|---|---|---|---|
| Active-Active | High | Immediate | Mission-critical global apps [1] |
| Warm Standby | Medium-High | Minutes | Key apps needing fast recovery [1] |
| Pilot Light | Medium | 10–30 minutes | Cost-conscious disaster recovery [1] |
To further manage costs, consider using VPC Endpoints for S3 and DynamoDB to lower data transfer fees [1]. Switching to ARM-based processors like Graviton can also reduce compute costs by up to 30% [1]. As Fedir Kompaniiets, a DevOps and Cloud Architecture expert, explains:
AWS cost optimisation is not a one-time activity but a continuous process requiring diligence, strategic planning, and adaptability[1].
For UK businesses, Hokstad Consulting offers expertise in optimising multi-region architectures. They can help balance consistency, cost efficiency, and compliance with UK GDPR and data residency requirements.
Conclusion
Multi-region elasticity offers the ability to scale dynamically, maintain resilience, and achieve a global presence. However, it comes with its own set of challenges. The CAP theorem highlights the unavoidable compromise between availability and consistency during network partitions.
To avoid unnecessary complexity and costs, it’s crucial to define your Recovery Time Objective (RTO) and Recovery Point Objective (RPO). Not all workloads demand high-consistency models, and over-engineering can lead to inefficiencies. For systems that are read-heavy, adopting a read local, write global
strategy can enhance performance, while write-heavy systems often benefit from a primary-standby setup with well-thought-out failover processes. Additionally, sharding data across regions can minimise the impact of regional disruptions, effectively reducing the blast radius.
Regulatory compliance adds another layer of complexity to these architectural decisions. For example, UK GDPR and data residency requirements can significantly influence system design. Striking a balance between adhering to these regulations, maintaining performance, and controlling costs requires meticulous planning. This includes keeping a close eye on replication lag, ensuring failover readiness, and managing cross-region data transfer expenses.
FAQs
How does multi-region elasticity influence data latency and system availability?
Multi-region elasticity enables workloads to adjust dynamically across different cloud regions, ensuring systems can tackle sudden demand increases and recover from regional disruptions. However, synchronising data between regions comes with challenges, primarily due to the physical distance involved. Synchronous replication guarantees consistent data across regions but introduces noticeable delays in write operations. On the other hand, asynchronous replication minimises latency but can lead to brief moments of inconsistency.
From an availability perspective, multi-region elasticity enhances system resilience by directing traffic to the closest operational region and supporting automated failover during outages. This design removes single points of failure and delivers exceptional uptime, often achieving the coveted five-nines
(99.999%) availability. Additionally, elasticity optimises infrastructure spending by scaling resources as needed, making it a cost-effective and dependable choice for businesses operating both across the UK and internationally.
How can organisations balance compliance and data consistency in multi-region systems?
Balancing compliance and maintaining data consistency across multi-region systems starts with thoroughly understanding the legal requirements specific to each region. For UK organisations, this often involves adhering to GDPR data-residency rules alongside any relevant industry standards. Establishing recovery-point objectives (RPO) and recovery-time objectives (RTO) early in the planning phase can provide a solid foundation for designing your infrastructure.
Selecting the right replication model is key to meeting compliance needs while managing latency. For sensitive data like financial records, synchronous replication is a strong choice as it ensures consistent data across regions. On the other hand, asynchronous replication can be a cost-effective option for less critical workloads, as it reduces latency. A hybrid model - using synchronous replication for critical data and asynchronous for less sensitive information - offers a practical way to strike a balance between performance and compliance.
Operationally, automating failover processes and maintaining immutable audit logs are essential for ensuring smooth transitions during regional outages. Encryption plays a crucial role in safeguarding data and ensuring traceability. Regular disaster recovery drills, combined with real-time monitoring of replication lag and compliance metrics, can further enhance system resilience. By adopting these strategies, UK organisations can meet regulatory requirements while delivering reliable and efficient multi-region systems.
How can businesses reduce costs while ensuring reliable data consistency across regions?
Businesses can keep costs in check while ensuring reliable multi-region data consistency by focusing on three practical strategies.
First, adopt elastic scaling to adjust computing and storage resources dynamically based on demand. This ensures you have enough capacity during busy periods while cutting infrastructure costs by as much as 30%–50% during quieter times. Pairing this with automated failover systems can further trim expenses by keeping standby resources to only what's absolutely necessary.
Second, choose the right replication model for your data. Synchronous replication provides strong consistency but can come with higher latency and network costs. On the other hand, asynchronous replication is more budget-friendly but may lead to short-term data inconsistencies. A smart solution? Use synchronous replication for critical data and asynchronous for less sensitive information, striking a balance between cost and consistency.
Finally, leverage managed global data services to simplify replication and reduce operational headaches. These services efficiently handle cross-region replication, allowing you to maintain consistency for essential data without needing separate clusters everywhere. By keeping an eye on usage patterns and using measures like reserved capacity for predictable workloads, businesses can build a cost-efficient, reliable multi-region setup that aligns with UK-specific needs.