
Multi-cluster traffic management ensures smooth and efficient distribution of network traffic across multiple Kubernetes clusters or data centres. This approach is critical for businesses operating globally, as it helps maintain performance, reduce latency, and safeguard against outages. However, it introduces challenges like configuration drift, session management, and security enforcement.
Key Takeaways:
- Scalability: Use global load balancing, automated service discovery, and traffic distribution strategies (e.g., weighted round-robin) to manage traffic effectively.
- Security: Implement mutual TLS (mTLS), zero-trust architecture, and centralised policy enforcement to secure inter-cluster communication.
- Resilience: Rely on failover mechanisms (active-active or active-standby), outlier detection, and health checks to ensure service continuity during disruptions.
Tools to Consider:
- Istio: Advanced traffic control and security for complex setups.
- Calico Cluster Mesh: Direct pod-to-pod communication with low latency.
- AWS Load Balancer Controller: Manages external ingress traffic seamlessly within AWS environments.
By starting with basic DNS routing and gradually adopting service mesh solutions, organisations can build scalable, secure, and resilient multi-cluster systems.
Demystifying Multi-Cluster Services/Gateways (Kubernetes Engine GCP)
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Core Principles for Managing Multi-Cluster Traffic
Managing traffic across multiple clusters involves addressing three key priorities: scalability, security, and resilience. These principles tackle distinct challenges, but together they form the backbone of a dependable multi-cluster setup. Getting these aspects right ensures your infrastructure can grow seamlessly, safeguard sensitive information, and stay operational even during disruptions.
Scalability and Load Balancing
Global load balancing acts as a centralised entry point, directing traffic based on factors like cluster health, capacity, and proximity [6]. This simplifies traffic management while increasing reliability by ensuring requests are routed to the most suitable cluster.
To handle both planned and unplanned events, adopt an N+1 model for scheduled maintenance or N+2 for unexpected outages. Techniques like draining and spilling help reroute traffic when other clusters have enough spare capacity [7].
Automated service discovery removes the need for manual configurations. Tools like the Multi-Cluster Services API enable parent clusters to automatically detect and route traffic to workloads advertised by child clusters [3][6]. For stateful services, HRW (Highest Random Weight) hashing maintains session affinity, ensuring consistent failovers without the need for cookies [3].
Traffic distribution strategies, such as weighted round-robin, allow teams to control how requests are split between clusters. This is particularly useful during migrations or while scaling up. For example, during gradual rollouts, traffic can be shifted incrementally using weighted round-robin, while monitoring metrics like error rates, latency, and cache performance at the cluster level [3][4].
These practices lay the groundwork for secure, compliant, and efficient multi-cluster operations.
Security and Compliance
Mutual TLS (mTLS) is a cornerstone of secure communication between clusters, encrypting traffic and verifying identities automatically [3]. For production environments, configure inter-cluster communication with RequireAndVerifyClientCert to ensure only authorised parent clusters can connect to child clusters [3]. Additionally, enforce firewall rules that limit inter-cluster traffic to specific parent cluster IP ranges.
A zero-trust architecture takes security a step further by applying strict access controls and authentication. This ensures only authorised services can communicate across the mesh. For industries like finance, fine-grained access control lists and service segmentation help contain potential breaches by limiting lateral movement.
Trust domain federation supports secure interactions between clusters while respecting regional data handling laws, including those in the UK and EU. Centralised policy enforcement ensures security configurations are consistently applied across diverse cloud environments. Tools like CI/CD pipelines and GitOps can synchronise these policies across clusters, reducing the risk of configuration drift that might introduce vulnerabilities.
This secure framework works hand in hand with resilience strategies to ensure uninterrupted service availability.
Resilience and Failover Mechanisms
Resilience strategies typically rely on either active-active or active-standby configurations [8]. In an active-active setup, traffic is distributed evenly across clusters, maximising resource use. In contrast, active-standby keeps one cluster as a backup, only routing traffic to it if the primary cluster fails. Locality-aware load balancing prioritises nearby clusters to lower latency and costs, automatically switching to remote clusters when needed [8][2].
Outlier detection plays a critical role in maintaining service quality by monitoring for repeated errors. If an instance shows consistent failures, it is temporarily removed from the load-balancing pool [2]. The Multi-Cluster Service (MCS) API enhances this by sharing service discovery data - if pods in one cluster become unreachable, traffic is seamlessly redirected to healthy pods in other clusters [6].
Bidirectional failover ensures that each cluster prioritises local traffic while maintaining a remote backup for added resilience [3]. Custom health check paths, such as /health, with tailored timeout and interval settings, help load balancers detect upstream failures more accurately [3][6]. Circuit breakers at the cluster level trigger immediate failovers when error thresholds are exceeded, preventing issues from spreading [5].
Tools and Technologies for Multi-Cluster Traffic Management
Managing traffic in multi-cluster environments requires tools that align with your specific needs - whether you're dealing with north–south traffic (external requests entering your clusters), east–west traffic (service-to-service communication between clusters), or both. The tools discussed here cater to these demands, balancing scalability, security, and resilience.
Istio for Service Mesh Traffic Management
Istio uses Envoy proxies, which can be deployed as sidecars or in ambient mode, to manage traffic across complex multi-cluster setups like Multi-Primary and Primary–Remote configurations [9][11]. It supports both north–south and east–west traffic using gateways for ingress and egress, while sidecars handle internal communication between services.
Istio's features include Virtual Services and Destination Rules, which enable precise routing strategies such as:
- Weight-based canary deployments
- Path-based routing
- Header-based traffic splitting
For example, Istio's traffic mirroring allows you to test a new service version by shadowing a portion of live traffic without disrupting production responses. To further optimise performance, you can enable locality-aware routing using node labels (e.g., topology.kubernetes.io/region) and outlier detection, which prevents routing to unhealthy endpoints [10]. This ensures better latency and reduced data transfer costs while maintaining cluster health.
For secure communication across clusters, a shared Certificate Authority can streamline mutual TLS (mTLS) setup. These features make Istio a strong choice for complex routing and gradual rollouts. However, for direct and efficient east–west communication, Calico Cluster Mesh offers a different approach.
Calico Cluster Mesh for East–West Traffic
Calico Cluster Mesh focuses on direct pod-to-pod communication across clusters, reducing network hops and latency while enforcing identity-aware policies [12]. Its DaemonSet-based deployment model uses one proxy per node instead of per pod, making it more resource-efficient and cost-effective for large-scale environments [13][14].
An example of its application is Box, a multi-cloud platform managing over 1,000 nodes. In June 2025, Box adopted Calico Cluster Mesh to implement zero-trust security, reduce maintenance costs, and ensure compliance across clusters. By leveraging Calico's federated identity and policy tiers, they achieved a streamlined security posture [14].
Calico also supports federated service discovery, allowing local clusters to automatically connect to remote endpoints. For encryption, it uses WireGuard, which provides high-performance secure communication between clusters [13]. This makes Calico ideal for organisations prioritising efficient east–west traffic management.
AWS Load Balancer Controller for Multi-Cluster Support
While Istio and Calico focus on internal traffic, managing external ingress requires a different approach. The AWS Load Balancer Controller is designed for north–south traffic, managing how external requests enter Kubernetes clusters. It integrates seamlessly with AWS services and handles TLS termination at the load balancer level, simplifying the process of managing external traffic.
For organisations using AWS in multi-cluster setups, combining the AWS Load Balancer Controller with a service mesh can create a robust traffic management strategy. The controller handles external ingress, while the mesh focuses on internal routing and security.
These tools, when used in combination, address the various challenges of multi-cluster traffic management. For tailored solutions to optimise your multi-cluster environments and reduce infrastructure costs, check out Hokstad Consulting: https://hokstadconsulting.com.
Best Practices for Multi-Cluster Traffic Management
Once you've chosen the right tools, the next step is implementing effective practices for managing traffic across clusters. These practices tackle common hurdles, from internal communication between services to routing external traffic.
Designing East-West Gateways
East-West gateways are essential for internal, cross-cluster service communication without exposing services to the public internet. Typically, these gateways operate on port 15443 and secure traffic between clusters using mTLS [17].
A key concept in multi-cluster setups is namespace sameness. This means services with identical names in the same namespace across clusters are treated as a single logical service [15][17]. Locality-aware routing is crucial here - it ensures that traffic prioritises the local cluster, cutting down on latency and egress costs. Remote clusters are only used when local services fail or are overloaded [17][1][8].
For security, restrict access to East-West gateway ports. Use firewall rules or private networks to block unauthorised connections [3][17]. Additionally, check the Security and Compliance section for detailed mTLS configurations.
These internal gateway principles work hand-in-hand with the external traffic strategies discussed below.
Implementing Global Load Balancers for North-South Traffic
Global load balancers act as the main entry point for external traffic, directing requests based on factors like geographic proximity, cluster health, and capacity [16][1][18]. To maintain consistency, manage Gateway API resources centrally in a config cluster
[16][3].
Beyond infrastructure-level checks, use application-level health checks (e.g., /healthz) to avoid sending traffic to degraded pods [1]. For smoother rollouts, weighted routing can help - start by sending 10% of traffic to a new cluster and gradually increase it before a full switch [3][18].
Tools like K8GB automate DNS-based global load balancing, syncing ingress hosts across clusters [1]. If you're using DNS-based solutions, set a splitBrainThresholdSeconds to prevent unstable DNS changes during temporary network issues [1].
Using Service Mesh Integrations for Traffic Control
Service mesh integrations build on internal and external routing practices by offering unified traffic control. For topology-aware configurations, set topologyChoice to CLUSTER to keep traffic local. Alternatively, use LOCALITY to distribute traffic across zones and regions for better resilience [8].
For stateful services that need consistent backend routing, Highest Random Weight (HRW) hashing ensures session affinity [3]. You can also manage failover priorities with custom labels (e.g., failover.tetrate.io/fault-domain) to control which clusters take over during regional outages [8].
The Kubernetes Gateway API is emerging as a standard for managing traffic across clusters, both internal and external. This approach simplifies configuration and reduces reliance on vendor-specific ingress controllers [16].
Comparison of Multi-Cluster Traffic Management Tools
::: @figure 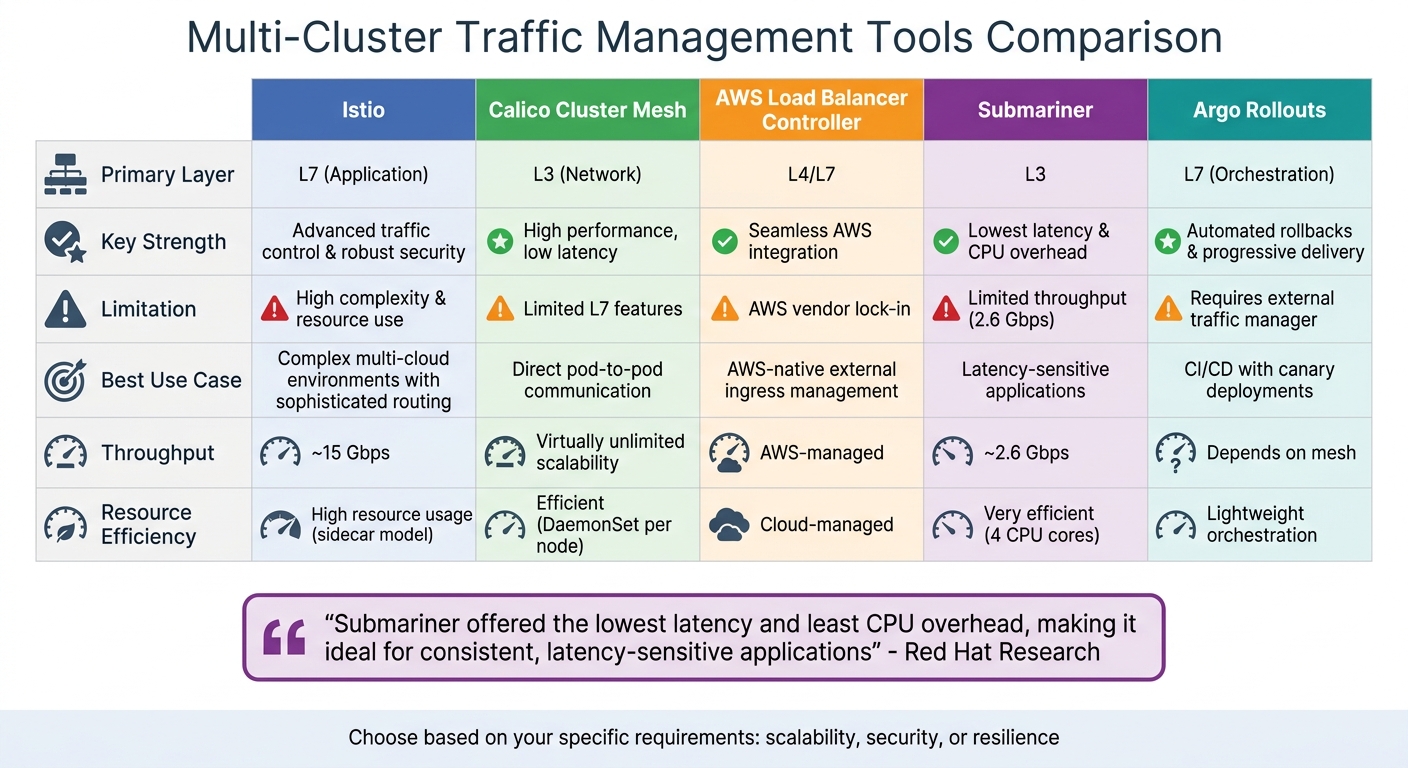 {Multi-Cluster Traffic Management Tools Comparison: Features, Performance and Use Cases}
:::
{Multi-Cluster Traffic Management Tools Comparison: Features, Performance and Use Cases}
:::
This section dives into a comparison of multi-cluster traffic management tools, helping you refine your strategy by aligning tool capabilities with your specific needs. Whether your focus is on scalability, security, or resilience, understanding the strengths and limitations of each tool ensures you make an informed choice.
The right tool for your setup often hinges on factors like throughput, latency, operational complexity, or cloud compatibility. Each tool shines in particular scenarios, so knowing the trade-offs is essential to pick the best fit.
Istio stands out for its advanced Layer 7 (L7) routing and robust security features like mTLS and RBAC. It demonstrated an impressive throughput of 15 Gbps in performance tests, making it a strong candidate for high-traffic applications [20]. That said, its capabilities come at the cost of higher operational complexity and greater resource demands, especially when using traditional sidecar deployments.
Calico Cluster Mesh focuses on efficient Layer 3 (L3) connectivity, offering virtually unlimited scalability as long as clusters use unique private CIDRs [19]. It also supports unified network policy enforcement across clusters, leveraging Kubernetes labels for consistency [19].
Submariner excels in environments where low latency is critical. It operates with minimal CPU overhead, using only 4 CPU cores compared to the 11 cores required by some alternatives. However, its IPSec encryption limits throughput to around 2.6 Gbps [20]. According to Red Hat Research:
Submariner offered the lowest latency and least CPU overhead, making it ideal for consistent, latency-sensitive applications [20].
Tool Comparison Table
The table below summarises the key strengths, limitations, and ideal use cases for each tool discussed:
| Tool | Primary Layer | Key Strength | Limitation | Best Use Case | Throughput |
|---|---|---|---|---|---|
| Istio | L7 (Application) | Advanced traffic control & robust security | High complexity & resource use | Complex multi-cloud environments with sophisticated routing | ~15 Gbps [20] |
| Calico Cluster Mesh | L3 (Network) | High performance, low latency | Limited L7 features | Direct pod-to-pod communication | Virtually unlimited scalability [19] |
| AWS Load Balancer Controller | L4/L7 | Seamless AWS integration | AWS vendor lock-in | AWS-native external ingress management | AWS-managed |
| Submariner | L3 | Lowest latency & CPU overhead | Limited throughput (2.6 Gbps) | Latency-sensitive applications | ~2.6 Gbps [20] |
| Argo Rollouts | L7 (Orchestration) | Automated rollbacks & progressive delivery | Requires external traffic manager | CI/CD with canary deployments | Depends on mesh |
This comparison highlights the unique strengths and trade-offs of each tool, enabling you to align your choice with the specific demands of your multi-cluster environment.
Conclusion
Effectively managing traffic in multi-cluster environments is a critical task for large-scale organisations. The strategies and tools discussed here offer a clear path to creating systems that are secure, scalable, and resilient. Whether you're balancing workloads across multiple cloud providers or gearing up for regional failovers, the core principles remain unchanged: keep things straightforward, automate wherever feasible, and make security a top priority from the beginning.
Operational consistency is more valuable than relying on overly complex tools. Using GitOps workflows and Infrastructure as Code ensures that traffic and security policies remain uniform across all clusters, helping to prevent configuration drift that could lead to outages. Maintaining consistent security policies across clusters is essential for meeting compliance requirements and reducing risk.
Improving performance through locality-aware routing and geographic load balancing can significantly enhance user experience by cutting down latency. Regular failover tests are key to uncovering hidden vulnerabilities before they escalate into major incidents. Additionally, always prepare and test explicit rollback plans before transitioning the first group of users to a new cluster.
These performance strategies naturally guide the selection of tools. The right tools should align with your specific needs. For example, DNS-based routing might be sufficient for global traffic management, while service mesh solutions can provide more detailed control for tasks like canary deployments and traffic mirroring.
FAQs
When should we move from DNS routing to a service mesh?
When working in multi-cluster environments, switching from DNS routing to a service mesh can make a big difference if you’re looking for more precise traffic control, automation, and dependability. A service mesh is particularly helpful for managing traffic smoothly, dealing with failovers effectively, and facilitating gradual rollouts in intricate microservices setups.
How do we keep session affinity during multi-cluster failovers?
To ensure session affinity during multi-cluster failovers, you can set up locality-aware routing and failover configurations. This helps keep traffic within the active cluster or redirects it smoothly to a functioning one. By using locality labels, prioritising failover settings, and applying outlier detection, you can identify unhealthy endpoints and reroute traffic to preferred zones or regions, maintaining session continuity. Platforms like Istio provide support for managing these settings effectively.
What’s the simplest way to enforce mTLS and zero-trust across clusters?
The easiest way to implement mTLS and maintain a zero-trust model across clusters is by setting traffic rules that ensure all traffic remains cluster-local. This can be achieved through specific mesh configuration settings. To further strengthen security, establish a shared trust between clusters by using common trust models or CA pools. For more details, you can refer to multi-cluster management guides for service meshes such as Istio.