
Sharding is a method of splitting large datasets into smaller, independent parts (shards) that are distributed across multiple servers or cloud nodes. This approach is essential for scaling databases horizontally, improving performance, and ensuring fault isolation. In cloud environments, sharding can reduce latency, support regional data compliance (e.g., UK GDPR), and lower infrastructure costs by using standard hardware instead of expensive, high-performance machines.
Key takeaways:
- Why use sharding? To handle high traffic, ensure fault isolation, and comply with data residency laws by placing data closer to users (e.g., UK vs EU).
- Shard key selection: Critical for balancing load and avoiding hotspots. High-cardinality keys like
user_idortenant_idare often best. - Sharding strategies: Range-based (simple but prone to hotspots), hash-based (balanced but complex for range queries), directory-based (flexible but adds latency), and geography-based (ideal for compliance and low latency).
- Cloud-native options: Managed databases (e.g., MongoDB Atlas, Azure Cosmos DB) simplify operations but may lead to vendor lock-in. Application-level sharding offers more control but requires careful management.
- Challenges: Poor shard key selection, uneven data distribution, and compliance risks can lead to performance issues and legal complications. Observability and automation are key to managing complexity.
Back to Basics: Database Sharding to Horizontally Scale Databases
Core Principles of Sharding
::: @figure 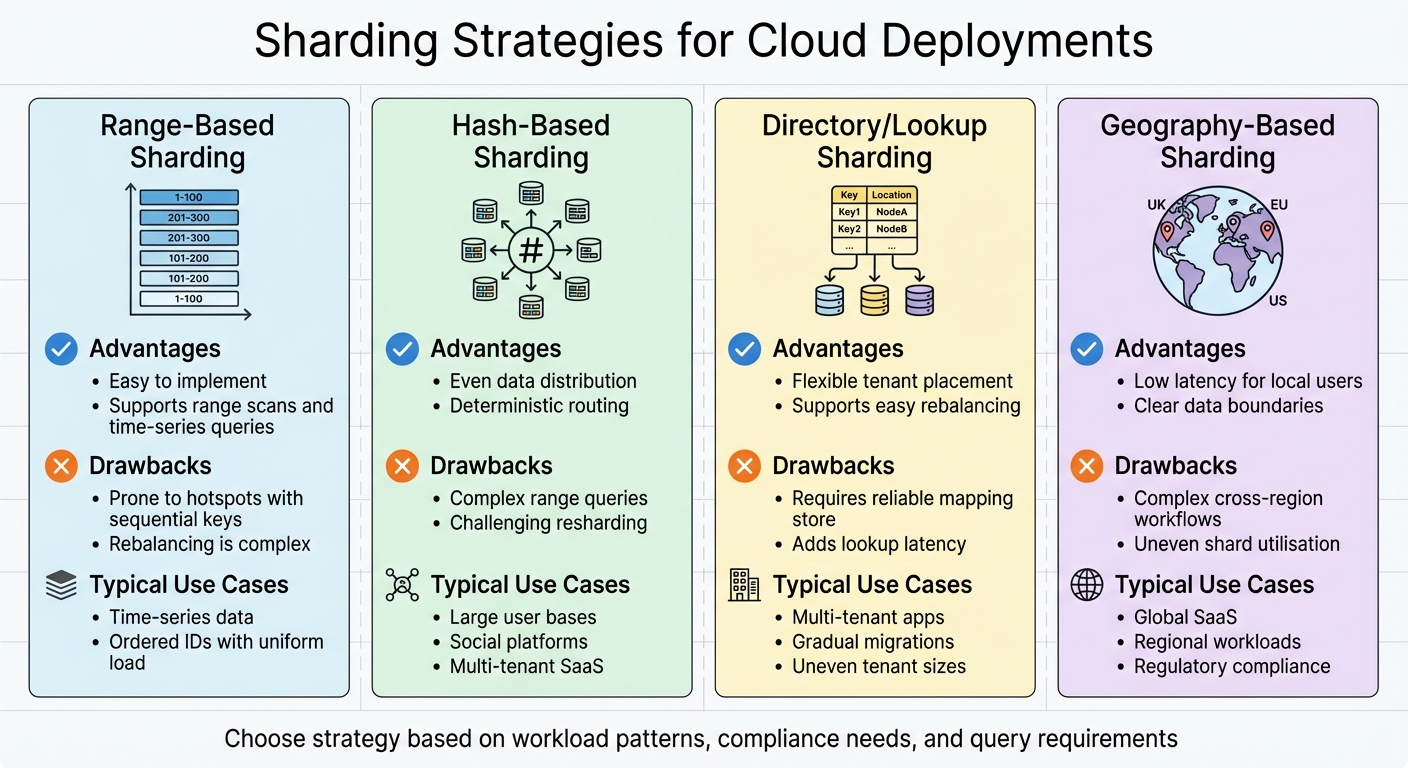 {Comparison of Database Sharding Strategies for Cloud Environments}
:::
{Comparison of Database Sharding Strategies for Cloud Environments}
:::
Sharding Terminology
Sharding involves breaking a dataset into horizontal partitions, known as shards. Each shard contains a subset of rows but follows the same schema as the others. These shards operate on separate instances or nodes. The shard key is the attribute - or combination of attributes - that decides which shard stores a particular record. A good shard key should have high cardinality, appear frequently in queries, and distribute the load evenly to avoid imbalances.
A routing layer (sometimes called a shard router or director) maps shard keys to their respective shard locations. It forwards read and write requests to the appropriate shard. Some systems manage this through a lookup map stored in a configuration service, while others rely on hash or range logic directly integrated into the application. To ensure high availability and support read scaling, shards are often part of a replica set, which includes a primary instance and one or more secondary replicas. However, issues like hotspots - where one shard handles a disproportionate amount of traffic or data - can undermine the efficiency of sharding.
Other key terms include virtual shards (logical partitions mapped to physical shards for easier rebalancing), shared-nothing architecture (where each shard operates independently), and cross-shard queries (operations spanning multiple shards that require additional coordination).
Next, we’ll explore how these concepts are applied in cloud environments to maximise their potential.
Sharding Strategies for Cloud Deployments
Range-based sharding divides data into contiguous key ranges. For example, one shard might store customer IDs from 1 to 1,000,000, while another handles IDs from 1,000,001 to 2,000,000. This method is straightforward and supports efficient range scans and data archiving. However, it can lead to hotspots if keys are sequential, such as when the newest data clusters on the latest
shard.
Hash-based sharding uses a hash function on the shard key (e.g., hash(user_id) mod N) to distribute data and load evenly. This approach is well-suited for high-traffic workloads like social media feeds or messaging systems. The downside? Range queries become more complex, and rebalancing when adding or removing shards can be tricky.
Lookup or directory-based sharding operates with a central mapping - typically stored in a configuration service or metadata table - to determine which shard holds a specific key. This strategy offers flexibility, such as relocating tenants for performance or cost reasons. However, it introduces extra latency due to lookups and requires the mapping system to be highly reliable.
Geography-based sharding partitions data based on regions (e.g., UK, EU, US), reducing latency and meeting data residency regulations like GDPR. Often, this is combined with range or hash-based approaches within each region for better balance. For instance, a UK e-commerce platform might store local customer data on shards in London for improved latency and compliance, while EU data might reside in Frankfurt.
Here’s a quick comparison of these strategies:
| Strategy | Advantages | Drawbacks | Typical Use Cases |
|---|---|---|---|
| Range-based | Easy to implement; supports range scans and time-series queries | Prone to hotspots with sequential keys; rebalancing is complex | Time-series data, ordered IDs with uniform load |
| Hash-based | Even data distribution; deterministic routing | Complex range queries; challenging resharding | Large user bases, social platforms, multi-tenant SaaS |
| Directory/lookup | Flexible tenant placement; supports easy rebalancing | Requires reliable mapping store; adds lookup latency | Multi-tenant apps, gradual migrations, uneven tenant sizes |
| Geography-based | Low latency for local users; clear data boundaries | Complex cross-region workflows; uneven shard utilisation | Global SaaS, regional workloads, regulatory compliance |
These strategies form the building blocks for designing efficient cloud-native sharded systems.
Cloud-Native Sharded Architecture Patterns
Cloud-native patterns take these strategies further, simplifying sharded deployments.
Managed sharded databases like MongoDB Atlas, Amazon Aurora (with partitioning), or Azure Cosmos DB handle tasks like partitioning, replication, balancing, and failover automatically. This frees teams to focus on shard key selection, indexing, and schema design, leaving node orchestration and resharding to the provider. These services offer reduced operational overhead, built-in monitoring, and high availability. However, they can come with trade-offs like provider lock-in, limited control over resharding, and pricing models that may be less flexible.
Application-level sharding puts the routing logic directly into the application. Here, the application decides which database or cluster to query based on the shard key, often using its own routing layer or service discovery mechanism. This approach is highly customisable and can span multi-region or multi-cloud environments to optimise for latency, cost, or resilience. For example, a UK-based SaaS provider might store UK customer data in a PostgreSQL cluster in London, while EU data is managed in Frankfurt. Some organisations even deploy separate sharded clusters across platforms like AWS and Azure for redundancy and cost savings.
While application-level sharding offers precise control over data placement and costs, it also increases complexity. Teams must manage cross-shard consistency and ensure robust observability. Specialist consultancies, such as Hokstad Consulting, can assist with designing these architectures, focusing on cloud cost efficiency and automating DevOps for sharded, multi-cloud environments.
Designing Sharded Systems
Workload Analysis and Shard Key Selection
Start by gathering production metrics over a period of 30 to 90 days to understand how your system behaves. Use database and application monitoring tools to track key metrics like queries per second (QPS), read/write ratios, latency distributions, and error rates. Pay close attention to frequent and resource-intensive queries to uncover dominant access patterns, such as user lookups, regional searches, or time-series queries [3][4].
Look at traffic peaks and regional variations. For example, UK working-day cycles, promotional events, and differences between UK and EU traffic can expose patterns of concurrency and spikes that your sharding strategy must address. Run capacity tests with skewed, realistic data to identify potential hotspots. Only after thoroughly understanding these patterns and bottlenecks should you decide whether sharding is the right solution, or if simpler approaches like vertical scaling or read replicas might suffice [2][3][8].
When selecting a shard key, test candidates using real production traces to evaluate both data distribution and query latency. Avoid sequential keys that can lead to write hotspots [3][4]. Choose a key that aligns with critical access patterns. For instance, user_id works well for user-centric workloads, while tenant_id is suitable for SaaS applications. The goal is to ensure most queries target a single shard, avoiding cross-shard joins or fan-out queries [2][4]. Hash-based sharding on a stable key like user_id can be effective for evenly distributing load, though it may increase the cost of range queries [2][6].
Keep in mind that once a shard key is chosen, it’s essentially locked in. Changing it later usually requires a large-scale data migration, which is both time-consuming and resource-intensive. These decisions directly impact how your data is modelled.
Data Modelling for Sharded Architectures
Using insights from workload analysis, structure your data model to optimise shard-local interactions [3][4]. Group related entities - like user profiles, settings, and recent activity - under the same shard key (e.g., user_id) to ensure they reside on the same shard [2][4]. To minimise cross-shard joins, consider denormalising small, static data such as product names or category labels. However, this approach requires careful management of update paths and eventual consistency [2][4].
For global reference data - like currencies, feature flags, or UK/EU tax rules - that is frequently read but rarely updated, use a dedicated non-sharded store or caching layers such as in-memory caches or CDN-backed services [2][5]. If global queries are unavoidable, such as for regulatory reporting across UK and EU tenants, implement asynchronous aggregation pipelines. These pipelines consolidate shard-local data into a central analytics store, avoiding costly synchronous cross-shard queries [2][3].
Cost-Aware Capacity Planning
With workload analysis, shard key selection, and data modelling in place, the next step is capacity planning with an eye on both cost and performance. Use the workload data to estimate peak and average shard loads, including QPS, storage requirements (in GB), and IOPS [3][8]. Match these requirements to the capabilities of cloud instances and storage options available in your target regions, such as UK and EU data centres [3][8]. For example, if your system needs to handle 200,000 QPS and each instance supports 20,000 QPS, plan for 12 to 14 shards to allow some buffer.
Compare costs for storage (per GB), IOPS, and regional pricing to optimise your workload distribution [8]. Over-sharding can lead to unnecessary overhead, while under-sharding risks degraded performance. Use simulations and cost models, factoring in reserved or savings plans and projected growth, to strike the right balance [3][8].
Examine current and anticipated data flows between services, users, and regions to identify where cross-region or cross-availability-zone traffic could lead to additional costs. Hosting shards closer to the majority of their users - for example, placing UK user shards in UK data centres - can cut down on latency and outbound data transfer fees, improving both performance and cost efficiency [8]. If your application requires cross-region replication or read access, consider batching replication or using compressed change streams instead of frequent synchronous calls. When budgeting for storage, account for not just per-GB pricing but also performance tiers (e.g., SSD vs. HDD, provisioned vs. burst IOPS) and backup or point-in-time recovery costs. Sharding allows you to use premium storage for hot
shards while assigning less active shards to more economical storage tiers [3][8].
Implementing Sharding in Cloud Environments
Routing and Discovery Mechanisms
Choosing how requests locate the right shard is a critical part of implementing sharding in cloud environments. You’ve got three main options for routing:
Client-side routing embeds sharding logic directly into the application or SDK, allowing it to target the correct shard without additional network hops [2][5]. This approach works well for teams managing microservices who want to minimise latency. However, it does mean that every client needs updating whenever shard mappings change.
Middleware or gateway-based routing introduces a routing service, API gateway, or connection proxy between clients and shards. This service identifies the correct shard by looking up the tenant or shard key in a directory, which is often stored in tools like DynamoDB, Redis, or etcd [2][11][5]. This method supports multiple services and makes it easier to update shard mappings independently. For systems based in the UK, hosting the routing service across multiple availability zones in London (eu-west-2) ensures low-latency lookups and resilience against regional disruptions.
Database-native routing takes advantage of the partitioning features built into managed cloud databases like Azure Cosmos DB or Amazon Aurora. These databases automatically handle shard assignments and rebalancing [6][7][8]. This option is particularly useful when your data model aligns well with the provider’s partitioning system and you want to reduce operational overhead. In UK-based systems, teams often combine database-native partitioning with a routing service and client-side hashing for added flexibility.
For tenant-to-shard mapping, a two-tier design is recommended. This involves mapping tenants to virtual shards, which are then mapped to physical shards [2][11]. Each tenant record links to a virtual shard ID, while a separate table maps virtual shards to physical database clusters. This setup allows virtual shards to be moved between physical nodes during resharding or failover without altering tenant records. To achieve sub-millisecond lookup times, store this mapping in a highly available key–value store deployed across multiple availability zones. This design also supports UK data residency requirements, letting you pin specific tenants to designated regions.
Connection management and failover involve health checks, service discovery, and connection pooling. Routing services can monitor each shard using periodic SQL probes or HTTP health checks, updating the virtual-to-physical mapping if a primary shard fails [2][10]. Clients refresh their connection pools when mappings change, often triggered by configuration updates or TTL-based cache invalidation. Managed DNS with low TTLs, database proxies, or service meshes like Envoy can transparently reroute traffic. Store shard discovery metadata in at least three independent nodes and regularly test failover scenarios between the UK and Europe to ensure updates propagate within your SLA window, maintaining resilience across multi-region deployments [10].
Schema Management and Distributed Migrations
Schema changes in sharded systems require a careful, multi-step approach to maintain consistency. Each shard should store its schema version in a dedicated metadata table, and migrations should be applied incrementally. The typical steps include:
- Deploying code that works with both old and new schemas.
- Executing additive migrations across shards.
- Rolling out code that uses the new schema.
- Removing deprecated columns in a later release.
A migration orchestrator, integrated into the CI/CD pipeline, tracks which migrations have been applied to each shard, ensuring consistency across UK and non-UK regions while adhering to local data protection laws.
For downtime-free changes, online schema change tools are essential. These tools replicate data in the background and swap schema elements atomically [3]. In a sharded setup, a migration controller applies changes in small batches, monitoring shard-specific metrics like latency and error rates. Changes can be paused or rolled back if thresholds are exceeded [3][5]. To minimise disruption, schedule migrations during UK off-peak hours and start with canary migrations on a small number of shards to identify potential issues before scaling up. For riskier migrations, cloud-native systems can use blue–green or shadow clusters, mirroring or gradually shifting traffic to validate the new schema.
Platforms like Apache ShardingSphere simplify sharding adoption by supporting transparent query routing, connection pooling, and online schema changes [9]. These platforms can handle read/write splitting, route queries based on shard keys, and coordinate distributed migrations across multiple shards, reducing the need for custom solutions.
Monitoring and Observability
Monitoring sharded systems requires collecting metrics at the shard level to quickly identify and resolve issues. Key metrics include request rate (QPS), read/write latency percentiles, error rates, CPU and memory usage, disk I/O, disk space, connection counts, and replication lag where applicable [2][3][11]. Each metric should include shard ID, tenant ID, and region labels, enabling side-by-side comparisons and hotspot detection. Logs should capture query patterns, slow queries, and routing decisions, ensuring that personal data is excluded to comply with UK GDPR.
Distributed tracing is another essential tool. Trace and span IDs should propagate from the edge (e.g., API gateway) through routing services to database drivers [11][6]. Tags like shard ID, tenant ID (if allowed), database operation type, and region should be included in each trace span. When a routing layer determines a shard via hash or directory lookup, that decision should be logged as a dedicated span. This approach helps diagnose routing anomalies or identify hotspots [2][11]. OpenTelemetry integration with managed tracing backends allows UK teams to view end-to-end timelines, making it easier to pinpoint slow components and shard-specific issues.
For alerting, focus on SLO-based, shard-aware alerts instead of reacting to every minor issue [3][6]. Alerts should trigger when a shard’s latency, error rate, or resource saturation (CPU, connections, replication lag) breaches user-facing SLOs for a sustained period. Group alerts by shard and severity: for example, page on-call staff if any shard’s 99th percentile latency exceeds the agreed limit for more than five minutes, but send only informational alerts for minor degradations. Aggregated alerts can highlight systemic issues, such as shared network or storage problems, while isolated alerts can flag misbehaving tenants or hotspots. On-call schedules should respect UK working patterns and holidays, with detailed runbooks outlining shard-specific remediation steps like throttling heavy tenants, triggering resharding, or temporarily upgrading compute resources in affected regions.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Operating and Scaling Sharded Systems
Runtime Monitoring and Maintenance
Managing sharded systems effectively requires a high level of shard-specific observability. Keep an eye on metrics like per-shard QPS, latency percentiles, error rates, resource usage, replication lag, and cache hit ratios. Tagging logs with shard IDs can help pinpoint issues quickly [4][2]. Setting SLOs at the shard level instead of just globally allows you to catch localised issues before they escalate into larger problems [4]. These monitoring practices lay the groundwork for improving performance and managing costs.
Shard rebalancing and hotspot mitigation are part of the ongoing maintenance of sharded systems. Over time, usage patterns can shift - situations like peak trading hours or sequential writes can overwhelm specific shards [4][2]. When metrics show uneven load distribution, investigate the root cause and apply targeted solutions. For hash-based sharding, virtual shard remapping can redistribute loads without moving large amounts of data [2]. For range-based systems, splitting hot ranges into smaller partitions and spreading them across nodes, sometimes with key randomisation (e.g., hash prefixes), can ease the pressure [4]. Rebalancing should use controlled data copy processes, limiting transfer speeds to a safe rate per shard. Avoid these operations during peak UK business hours, and use dual-write or change-data-capture mechanisms to synchronise data between locations until the process is complete [2].
Shard-level backups and disaster recovery are critical for minimising disruptions and ensuring data integrity. Each shard can be backed up, restored, and tested independently [4]. To avoid global system strain, stagger backup schedules across shards. Store incremental backups in region-specific object storage, such as UK-based buckets for data from UK residents, to comply with local regulations. Disaster recovery plans should address scenarios like single-shard failures, node or zone outages within the UK, or regional failover where data residency rules allow. Regular game days
should test the recovery of a representative shard, ensuring it can be restored to a new cluster and brought back online within the target recovery time objective (RTO). These tests should use realistic data volumes and be scheduled during off-peak hours in the UK [4][2].
Performance and Cost Improvements
Once shard-specific monitoring is in place, you can begin making targeted improvements to performance and cost. Performance benefits often come from smaller working sets and increased parallelism, which ensure hot data stays in memory and queries run efficiently [4][6]. Start by identifying the highest-QPS and slowest queries on each shard. Confirm that these queries are shard-local and supported by the necessary indexes [4][3]. However, keep in mind that every index adds storage and write latency. Teams should monitor the storage and write overhead of each index to determine whether the performance boost is worth the cost. Before rolling out new indexes widely, test them on a small subset of the system (e.g., 5–10%) using sampling profilers and A/B testing.
Distributed caches, such as managed Redis, can significantly reduce latency and costs, especially when placed near each shard to keep UK data local. For ultra-hot data like feature flags or pricing tiers, application-local in-memory caches with short TTLs can help reduce staleness. Caching also works well for expensive cross-shard operations. For example, precomputing daily or hourly summaries and storing them in a dedicated reporting store can reduce the need for multi-shard queries [4][6]. Monitor cache hit rates and compare cache-related costs (compute and memory) with the savings in database CPU, storage, and network egress. Adjust TTLs and cache sizes based on this analysis, and remove caches that add complexity without delivering clear benefits. Fine-tuned caching can have a direct impact on cloud expenses.
Key cost drivers in sharded systems include compute resources for each shard, storage, network traffic between regions or availability zones, and the operational overhead of managing complexity [2][6]. To control costs, tag resources in the cloud provider with shard IDs, environments (e.g., production or staging), and regions (e.g., uk-south
). This allows you to allocate expenses to specific workloads or business units. Optimise costs by right-sizing shard nodes, using auto-scaling where possible, and moving cold data to cheaper storage tiers. Network egress charges are often driven by cross-region replication and inter-zone traffic. Minimising cross-region calls for UK traffic and keeping UK users on local shards can significantly cut these costs. Expert partners like Hokstad Consulting can assist with strategies such as workload-aware sharding, automated right-sizing, and better routing to reduce resource usage and network expenses. For instance, a SaaS company saved £90,000 annually by implementing cloud optimisation measures, while an e-commerce platform improved performance by 50% and reduced cloud costs by 30% [1].
Resharding and System Evolution
Even with efficient operation and tuning, sharded systems must evolve over time. Resharding is unavoidable, so designs should allow for adding shards, splitting or merging existing ones, and updating shard mappings without requiring a full re-partitioning [4][2]. Safe resharding can be achieved using indirection and dual-write strategies. Instead of modifying application code, update a central shard directory [2][5]. When splitting shards, copy historical data in the background and enable dual-writes until replication is complete and validated. Then, update the shard directory atomically and disable dual-writes. Merging shards works in reverse: consolidate data and incrementally update mappings. To minimise downtime, use rolling cut-overs, feature flags for isolating specific ranges or tenants, and schema changes compatible with both old and new shard layouts.
Changing shard keys is one of the most complex operations, as it typically involves moving most or all data [4][3]. To prepare for this, keep shard-routing logic within a dedicated service and avoid exposing physical shard IDs in public APIs. Treat shard keys as internal details that can change as needed. For example, transitioning from customer-ID keys to region-aware keys to meet UK and EU data residency requirements can be done incrementally. Support both old and new keys in the routing layer, migrate data gradually, and execute cut-overs range-by-range or tenant-by-tenant.
Governance and documentation play a crucial role in managing sharded systems. Maintain clear records of shard-key decisions, routing rules, resharding procedures, and data residency mappings to support audits, compliance, and team handovers [4][2]. Comprehensive runbooks, on-call training, and clearly defined ownership for each shard group are essential for long-term success. Regular updates to the architecture ensure the system remains efficient and compliant with evolving regulations in cloud environments.
Common Pitfalls in Sharded Systems
Shard Key Selection Errors
Choosing the wrong shard key can lead to major headaches like hotspots, uneven data distribution, and costly cross-shard queries [2][4]. A well-chosen shard key should have high cardinality, appear frequently in queries, and ensure traffic is evenly spread across shards [4][6]. Unfortunately, teams often pick sequential keys, which funnel recent traffic to a single shard. Similarly, range-based sharding on ever-increasing values creates hotspots, overloading the newest shard and defeating the purpose of sharding.
Low-cardinality keys are another trap, as they trigger scatter-gather queries that slow things down. Instead, opt for high-cardinality keys tied closely to core read and write operations. Test potential keys with realistic, skewed datasets, and avoid keys that might need to change later. While hash-based or directory-based schemes using tenant or user IDs can help with range hotspots, they can complicate range queries and make future resharding trickier. Embedding a shard key that needs to change later could result in expensive global migrations and downtime.
To catch these issues early, monitor key metrics for each shard - like QPS, latency percentiles, CPU usage, IOPS, and cache hit rates. Set alerts for imbalances, such as when a shard’s QPS or storage exceeds twice the median. Query-level telemetry and realistic load testing in staging environments can also reveal clustering problems, especially when new tenants or popular entities concentrate on a few shards. Getting the shard key right from the start is crucial for building a resilient and scalable system.
Complexity and Observability Gaps
Managing sharded systems is no walk in the park. Beyond picking the right shard key, these systems bring complexities like routing, schema changes, distributed transactions, and handling failures [2][4][6]. A lack of observability - missing per-shard metrics, logs, or tracing - makes it harder to detect hotspots or troubleshoot cross-shard failures [2][4].
To stay ahead of issues, ensure you have robust per-shard metrics and distributed tracing in place. Dashboards that spotlight outlier shards and cross-shard operations, paired with detailed runbooks, can improve operational insights significantly. Many teams rely on managed observability stacks from cloud providers or build custom setups using tools like Grafana and Prometheus. Experts such as Hokstad Consulting, with their DevOps and cloud infrastructure know-how, can help define service-level objectives and alerting practices to streamline operations.
Operational challenges also stem from tightly coupling application code to shard topology, inconsistent schema management, and relying on manual scripts for migrations or rebalancing [2][5]. Simplifying these processes can make a big difference. Consider introducing a routing layer or shard directory service, standardising schema change workflows, and encapsulating sharding logic within libraries or gateways. This way, product teams can interact with a logical database rather than worrying about individual shards. Adopting cloud-native designs with infrastructure-as-code and CI/CD pipelines for automated shard creation, scaling, and failover can also reduce complexity. For instance, one startup cut deployment times from six hours to just 20 minutes by automating these processes and improving their DevOps practices [1].
Compliance and Data Residency Risks
Sharded systems don’t just pose technical challenges - regulatory compliance adds another layer of complexity. Laws like the UK and EU GDPR mandate that personal data must be processed and stored within specific regions, which directly affects where shards, replicas, and backups are located [8]. Failing to meet these data residency requirements can result in breaches of UK data protection laws [2].
One effective approach is dividing data into region-specific shard groups, such as a UK cluster
and an EU cluster
, to ensure all replicas and backups stay within approved regions. Residency attributes should be built into the routing logic so that UK users, for example, are always directed to UK-compliant shards [8]. Metadata services should track residency labels for each tenant, while routing mechanisms must enforce these boundaries, only allowing cross-border transfers through approved and audited processes. Using infrastructure-as-code, you can pin shard groups to specific cloud regions (e.g., UK South or West Europe) and configure backup and disaster recovery targets accordingly.
Regular audits and strict region-specific setups are a must. If compliance uncertainties or residency violations arise, consulting experts like Hokstad Consulting can be a cost-effective way to redesign shard architectures that meet legal requirements while optimising cloud performance and costs. These risks require ongoing audits and integration with your broader compliance monitoring efforts to ensure everything stays on track.
Conclusion
Sharding is a practical approach to horizontal scaling, enabling you to spread datasets and high request volumes across multiple independent databases. Its success hinges on a well-thought-out foundation. The shard key you select - preferably one with high-cardinality, stability, and frequent use in queries - will significantly influence your system's performance, costs, and long-term maintainability. Each sharding strategy comes with its own trade-offs, balancing load distribution against query complexity.
Operational discipline is key. Reliable metrics and automated processes turn sharded systems into manageable platforms. As discussed earlier, these elements are the backbone of a resilient sharding setup. Planning for resharding from the beginning is crucial - use logical shards over physical ones, automate data movement with safeguards, and test thoroughly with realistic traffic patterns reflective of UK usage. Cloud-native tools, such as managed databases and Infrastructure as Code, can minimise operational overhead and facilitate safer migrations, provided that routing, schema updates, and failover strategies are carefully designed.
Beyond operations, managing costs is just as important. In cloud environments with usage-based pricing, cost control must be a priority. While increasing the number of shards can improve parallelism and reduce latency, it also adds complexity - more instances, more connections, and greater operational demands. Keeping an eye on cost metrics will help you decide whether to expand sharding or consolidate. Strategies like right-sizing instances, using the right storage tiers, and applying autoscaling policies tailored to UK and EU demand patterns can help you balance costs while meeting service-level agreements (SLAs).
However, the challenges of sharding go beyond operational and financial considerations. Many teams overlook the cross-disciplinary aspects, from data modelling to compliance requirements. Hokstad Consulting can assist by validating shard key choices, designing CI/CD pipelines for sharded databases, and optimising hosting configurations. Their expertise, including the use of AI-driven tools for anomaly detection and automation, can help streamline even the most complex sharded systems, potentially cutting recurring costs by up to 50% without compromising reliability.
To get started, take a measured approach. Begin with a discovery phase, implement a small-scale prototype on a non-critical workload, and test it with real-world traffic. With careful planning, strong observability, and expert input where necessary, sharding can provide a scalable, cost-efficient, and resilient solution for your database needs.
FAQs
What should you consider when choosing a shard key in a cloud environment?
When picking a shard key, it's important to choose one that ensures data is evenly distributed across all shards. This helps avoid bottlenecks that can slow things down. Additionally, the key should reduce cross-shard queries, as these can hurt performance, and it should align with your application's workload patterns to improve scalability and efficiency. A carefully selected shard key plays a key role in boosting performance and making the most of resources in cloud-based systems.
How does sharding support compliance with regional data laws like UK GDPR?
Sharding allows organisations to meet regional data laws, like the UK GDPR, by ensuring data is stored and processed within designated geographic areas. This approach helps satisfy data residency rules and reduces the legal challenges associated with transferring data across borders.
By dividing data into location-based shards, businesses can better control where sensitive information resides. This not only aligns with regulatory requirements but also strengthens data management practices overall.
What challenges can arise when implementing sharding in cloud-native systems?
Implementing sharding in cloud-native systems isn’t without its hurdles. One major challenge is maintaining data consistency across shards, which becomes increasingly intricate as your system grows. As the scale expands, efficiently distributing and rebalancing data also requires meticulous planning to prevent performance slowdowns.
On top of that, sharding adds a layer of operational complexity. Managing and monitoring multiple shards demands additional resources and a higher level of expertise. Striking the right balance between scalability and performance is essential, as poor planning can result in higher maintenance demands for your infrastructure.