
Service discovery and load balancing are essential for managing microservices, where network locations constantly change due to scaling, failures, or updates. Here's how they work together:
- Service Discovery: Automatically tracks service instances and their locations, eliminating manual configurations.
- Load Balancing: Distributes traffic evenly across instances, ensuring no single node is overwhelmed.
Together, they handle dynamic environments, improve resilience, and ensure smooth communication between services. Whether using client-side discovery, server-side discovery, or service meshes, these systems automate traffic management and health monitoring, keeping microservices efficient and reliable.
Key Benefits:
- Dynamic scaling with automated instance registration.
- Improved availability through health checks and failover mechanisms.
- Resilience with real-time traffic rerouting to healthy nodes.
For deeper integration, service meshes combine both systems into a single layer, offering advanced traffic control and security features. Whether you're using Kubernetes, Consul, or a service mesh like Istio, these tools are critical for modern cloud-based architectures.
Service Discovery: How It Works
What Is Service Discovery?
Service discovery simplifies the process of locating services by automating their registration and discovery. Instead of manually configuring IP addresses and ports, services announce their endpoints to a central directory when they start. Other services can then query this directory whenever they need to communicate. This approach is particularly useful in dynamic environments, where services frequently scale or shift across platforms such as virtual machines, containers, or serverless setups. It ensures that dependent applications don't require constant reconfiguration.
At the heart of this process lies the service registry, which plays a key role in managing and storing the constantly changing details of service locations.
A service registry acts as the single source of truth for all service locations. It ensures that any service needing to communicate with another can always query a reliable, up-to-date directory to find a healthy target.- OpsMoon [8]
Service Registries: How They Store and Manage Service Information
A service registry keeps track of essential details like the name, address, health status, and metadata of each service instance. When a service starts, it registers itself in the registry. The registry then monitors the service's health through regular checks and removes it upon shutdown or failure.
How a registry behaves during network disruptions depends on its design. Some tools, like Consul and etcd, focus on strong consistency, ensuring all clients access the same data. However, this can result in temporary unavailability during network partitions. Others, like Eureka, prioritise availability, allowing access to cached data even if it's slightly outdated. For instance, Netflix uses Eureka to ensure that services can still communicate during network issues by relying on cached information [8].
Kubernetes initially used a single Endpoints object for service discovery. However, this approach struggled with scalability in large clusters. To address this, Kubernetes introduced EndpointSlice objects, which break endpoints into smaller, more manageable groups, improving performance at scale [8].
Despite their benefits, service registries face challenges that can affect their reliability.
Common Challenges in Service Discovery
One major issue is stale data. If a service crashes and its registry entry hasn't yet expired, clients might try to connect to a non-functional instance [8]. Similarly, DNS caching can cause clients to hold onto outdated IP addresses.
Another problem is registration churn, where services repeatedly register and deregister in a short time. This often points to underlying issues like misconfigured health checks or resource problems. Security is also a concern, as unsecured registries can allow unauthorised services to register or expose sensitive network details. To mitigate these risks, techniques like Mutual TLS (mTLS) for secure communication and Access Control Lists (ACLs) to limit service interactions are commonly used [8].
Airbnb tackled these challenges by creating SmartStack, a system that combines service registration with transparent load balancing. SmartStack uses Nerve for service registration and health checks and Synapse as a proxy for discovery and load balancing. This setup enables automatic failovers and allows services to scale independently without manual intervention [1][9].
Addressing these challenges is crucial as we delve into how load balancing works alongside service discovery to ensure smooth performance in microservices environments.
How Do Microservices Handle Service Discovery And Load Balancing? - Cloud Stack Studio
Load Balancing: How It Distributes Traffic
After addressing the challenges of service discovery, load balancing steps in as a critical method to efficiently distribute network traffic.
What Is Load Balancing?
Load balancing ensures that incoming network traffic is evenly distributed across multiple service instances. This prevents any single instance from being overwhelmed, improving system reliability by redirecting traffic away from unhealthy instances to those that are functioning properly. The result? High availability and seamless user experiences.
In microservices, load balancers work hand-in-hand with service discovery to handle the constant churn of containers. They make sure traffic only reaches healthy, active endpoints. Beyond simple traffic distribution, load balancers also optimise resource use by routing requests based on the system's real-time state.
Load balancing a service allows clients to be decoupled from the scalability of those other services. All clients have a single URL to interact with.- Software Engineering StackExchange
The impact of effective load balancing can be game-changing. For instance, Terminix saw a 300% increase in throughput by leveraging Gateway Load Balancers to manage third-party virtual appliances [10]. Similarly, Code.org handled a 400% surge in traffic during global online coding events using Application Load Balancers [10].
Layer 4 vs Layer 7 Load Balancing
Load balancers operate at different layers of the OSI model, each designed to meet specific needs.
Layer 4 (Transport Layer) load balancing makes decisions based on IP addresses and ports from TCP/UDP headers. This method is fast, lightweight, and avoids inspecting the actual data, making it ideal for high-throughput tasks like database queries or DNS services. It operates with minimal CPU usage and achieves latency in the microsecond range.
Layer 7 (Application Layer) load balancing, on the other hand, acts as a reverse proxy. It inspects the full payload, including HTTP headers, URLs, cookies, and gRPC methods. This deeper inspection allows for intelligent routing, such as directing requests to specific endpoints based on content. However, this comes with higher CPU usage and latency measured in milliseconds.
Layer 4 is fast and simple for TCP/UDP-based workloads; use Layer 7 when protocols and security requirements demand content inspection.- Kay James, Gravitee
Layer 7 is indispensable for microservices requiring path-based routing (e.g., directing /orders
to one service and /users
to another) or for handling modern protocols like HTTP/2. However, for high-throughput services, switching from Layer 7 to Layer 4 can cut cloud compute costs by up to 20% due to reduced processing demands [12]. Many large-scale systems use a hybrid model: Layer 4 for speed and initial protection, followed by Layer 7 for advanced routing through components like API gateways.
| Feature | Layer 4 (Transport) | Layer 7 (Application) |
|---|---|---|
| OSI Layer | TCP/UDP | HTTP/HTTPS/gRPC |
| Routing Basis | IP Address and Port | URL, Headers, Cookies |
| Latency | Microseconds | Milliseconds |
| CPU Cost | Lower | Higher |
| Best For | High-speed streams, databases | Content-based routing, microservices |
Understanding these differences is key to designing systems that balance performance and functionality.
Load Balancing Algorithms Explained
The way traffic is distributed depends on the algorithm used by the load balancer.
Round-robin: Requests are distributed sequentially across servers, ensuring each one gets an equal share. This static approach works well for stateless APIs where all servers have similar capabilities.
Least Connections: This dynamic algorithm routes requests to the server with the fewest active connections. It's particularly useful for services with long-lasting or variable-duration connections, like chat apps or streaming platforms.
IP Hash: By hashing the client’s IP, this method consistently maps users to specific servers. This is ideal for stateful applications, such as e-commerce platforms that require session persistence.
Weighted versions of round-robin and least connections allow servers with greater capacity to handle a larger share of the traffic. For resource-heavy workloads, algorithms that consider real-time CPU and memory usage can deliver even more efficient routing. The choice of algorithm plays a critical role in shaping how load-balancing solutions are implemented, setting the stage for further optimisation.
How Service Discovery and Load Balancing Work Together
::: @figure 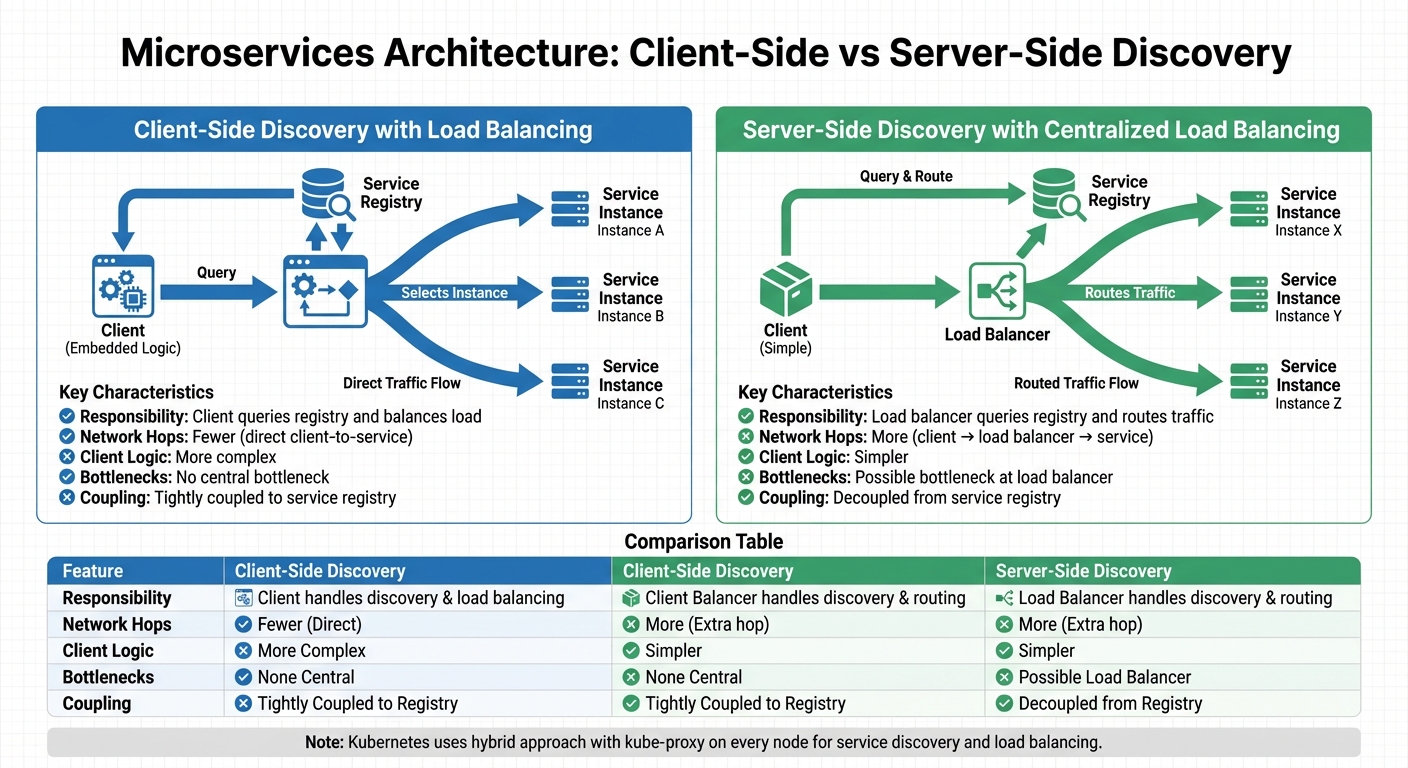 {Client-Side vs Server-Side Service Discovery Architecture Comparison}
:::
{Client-Side vs Server-Side Service Discovery Architecture Comparison}
:::
Service discovery and load balancing are like two sides of the same coin when it comes to building scalable, resilient microservices. The way they work together depends on the load balancing approach - whether it's handled by the client, a centralised intermediary, or through a service mesh. Each option comes with its own set of challenges and benefits, influencing complexity, performance, and fault tolerance.
Client-Side Discovery with Load Balancing
In client-side discovery, the service consumer (the client) directly queries the service registry to get a list of available, healthy service instances. The client then applies its own load-balancing logic - using methods like round-robin, random selection, or consistent hashing - to pick an instance to connect to.
This setup eliminates the need for a central load balancer, which means there's no single point of failure or system bottleneck. It also allows clients to cache registry data, ensuring they can still function temporarily if the registry becomes unavailable.
The benefits of the client-side approach mostly come from the absence of the load balancer. There is neither a single point of failure nor a potential throughput bottleneck in the system design.- Ivan Velichko, Software Engineer
However, this approach isn't without its downsides. It makes the client more complex, as it needs to handle service discovery logic for every programming language used. Frameworks like Spring Cloud can help simplify this, but clients still remain tightly connected to the service registry's API. For languages that don't natively support this, tools like Netflix's Prana - a sidecar proxy - can bridge the gap.
Server-Side Discovery with Centralised Load Balancing
In server-side discovery, the client doesn't interact with the service registry directly. Instead, it sends requests to a central load balancer (like AWS ELB, NGINX, or HAProxy). The load balancer handles querying the registry and routes traffic to a healthy service instance. This makes the client logic much simpler, as the discovery process is hidden from the client.
Compared to client-side discovery, the client code is simpler since it does not have to deal with discovery.- Chris Richardson, Author of Microservices Patterns
But there are trade-offs. Maintaining a highly available load balancer adds operational overhead, and the additional network hop (client → load balancer → service) can increase latency.
Here’s a quick comparison of the two approaches:
| Feature | Client-Side Discovery | Server-Side Discovery |
|---|---|---|
| Responsibility | Client queries the registry and balances load | Load balancer queries the registry and routes traffic |
| Network Hops | Fewer (direct client-to-service) | More (client → load balancer → service) |
| Client Logic | More complex | Simpler |
| Bottlenecks | No central bottleneck | Possible bottleneck at the load balancer |
| Coupling | Tightly coupled to the service registry | Decoupled from the service registry |
Kubernetes takes a hybrid approach by running a kube-proxy on every node, essentially making each node a local service proxy. This avoids the bottleneck of a single load balancer while keeping client logic straightforward.
Service Meshes: An Advanced Pattern
For even greater control, service meshes combine service discovery and load balancing into a dedicated infrastructure layer. They use sidecar proxies (like Envoy) deployed alongside each service. These proxies handle discovery by continuously communicating with a central control plane, which keeps them updated on available service instances. They also manage load balancing dynamically as services scale up or down.
Service meshes go beyond basic traffic distribution. They support advanced load-balancing methods like least request, Maglev, and ring hash for consistent hashing. They also improve resilience with features like active health checks and circuit breakers, which automatically remove failing instances to prevent cascading issues. Meshes even enable fine-grained traffic control, allowing for canary deployments, blue-green rollouts, and routing based on specific HTTP headers or user identities. They can distribute traffic across regions and fail over to healthy ones when needed.
Service meshes play a pivotal role in service discovery and traffic management within microservices architectures. By abstracting and automating the complexities of inter-service communication, they enhance reliability, security, and scalability.- Kevin Edward, Royal Melbourne Institute of Technology
Service meshes also bolster observability by collecting logs, metrics, and traces, while improving security with mutual TLS (mTLS) between services. However, this added functionality comes with increased operational complexity. Starting small with a pilot implementation on a subset of services is often the best way to test the waters before scaling up. This advanced integration highlights how tightly service discovery and load balancing are intertwined in keeping microservices efficient and reliable.
How to Implement Service Discovery and Load Balancing
Getting service discovery and load balancing right is all about using the proper tools and maintaining strong monitoring systems. This ensures your microservices run smoothly, even in complex, ever-changing environments.
Selecting the Right Tools for Your Architecture
Start by evaluating your hosting setup. If you're using container orchestration platforms like Kubernetes or Mesos, you're in luck - they come with built-in discovery features. For environments that rely on virtual machines or a mix of systems, tools like Consul or ZooKeeper are excellent options. They offer flexibility and adaptability for dynamic microservices.
When it comes to load balancing, your choice depends on your needs:
- Layer 4 load balancing: Ideal for speed, routing traffic based on IP addresses and ports.
- Layer 7 load balancing: Perfect for advanced use cases like A/B testing or canary deployments, as it uses HTTP attributes for routing.
Security also plays a big role. If encrypted communication between services is a must, look for tools that support Mutual TLS (mTLS) and offer detailed authorisation controls. Additionally, tools that work well with observability platforms and use consensus protocols like Raft (used in Consul and etcd) are worth considering - they ensure data consistency and system resilience.
Once you've chosen your tools, the next challenge is to implement effective monitoring and automation.
Monitoring, Observability, and Automation
Keeping an eye on system health is non-negotiable. Modern load balancers use real-time feedback to make smart routing decisions, relying on metrics like request latency, error rates, and resource usage. As Muhammad Raza from Splunk puts it:
Load balancing in microservices... receives dynamic updates from the service discovery tools and can route traffic using real-time information such as paths, headers, metadata and request versions[6].
Health checks should go beyond simple up or down
tests. Distributed health checks that monitor CPU and memory usage give a more detailed view. Load balancers should also query DNS SRV records from service registries to keep track of healthy endpoints. Automating these updates ensures new instances are added immediately. Circuit breakers are another must-have, as they remove failing nodes when error rates rise. Services can also signal overload by returning HTTP 503 during health checks, prompting their removal from the pool [4].
These practices provide the foundation for efficient service discovery and load balancing.
Example: A Successful Integration
Many companies are turning to service meshes like Istio or Linkerd for a unified approach to service discovery, load balancing, and security. These meshes use sidecar proxies to handle traffic dynamically, gather observability data automatically, and enforce mTLS between services.
For more tailored advice on implementing these strategies in your microservices setup, you can explore resources from Hokstad Consulting (https://hokstadconsulting.com).
Conclusion
Key Takeaways
Service discovery and load balancing play a crucial role in modern microservices architectures. They allow for dynamic scaling, boost resilience through automated health checks, and improve performance by avoiding bottlenecks [2][3][1][7][11]. These capabilities streamline operations, particularly in dynamic cloud environments [5].
This approach brings three main benefits: greater resilience by routing traffic only to healthy instances via automated checks [1][7], service independence that supports the evolution of individual components [1][5], and performance gains through intelligent traffic distribution [1][11]. As Armon Dadgar, Co-founder and CTO of HashiCorp, explains:
A more modern approach is to use a service registry... As new instances boot, they get automatically registered inside of this catalog - the central registry - that knows, what are all the services, where are they running, what's their current status? And then we drive our load-balancing against this registry[5].
Whether you choose client-side or server-side discovery, automating registration and focusing on health monitoring are key. Tools like Istio and Linkerd offer advanced solutions, combining service discovery, load balancing, and security into a unified infrastructure layer [1][7].
Next Steps for Implementation
To start reaping these benefits, take action now. Assess your current infrastructure. If you're using containers, platforms like Kubernetes already provide built-in discovery features. For virtual machine-based or hybrid environments, tools such as Consul or ZooKeeper can serve as platform-agnostic solutions [2][7]. Moving from static IPs to dynamic service registries is no longer optional - it's essential for thriving in cloud-native environments [5][1].
For organisations navigating complex migrations or seeking tailored solutions, Hokstad Consulting (https://hokstadconsulting.com) offers expert support. Their services include DevOps transformation, cloud infrastructure optimisation, and custom automation to help you fully embrace a dynamic microservices architecture.
FAQs
When should I use client-side vs server-side service discovery?
The decision between client-side and server-side service discovery hinges on the specific needs and complexity of your system.
With client-side discovery, clients handle the heavy lifting by directly querying a service registry to manage load balancing and routing. This approach is often suitable for setups where simplicity on the server side is a priority, and clients can efficiently handle these responsibilities.
On the other hand, server-side discovery shifts the responsibility to a centralised load balancer or API gateway. This setup simplifies client logic, making it particularly effective in large-scale or fast-changing environments where managing complexity at the client level would be challenging.
How do health checks stop traffic going to dead instances?
Health checks play a crucial role in ensuring smooth service operation by testing the responsiveness of instances at regular intervals. When an instance fails these checks, it is flagged as unhealthy and taken out of the load balancing pool. This ensures that only active, functioning instances manage incoming traffic, helping to maintain service reliability and minimise potential disruptions.
Do I need a service mesh, or are discovery and a load balancer enough?
When deciding between a service mesh and just service discovery with load balancing, it all comes down to the complexity of your microservices architecture. Service discovery and load balancing are great for managing dynamic service locations and distributing traffic - perfect for simpler setups. But if you need advanced features like detailed traffic routing, robust security policies, or in-depth observability, a service mesh steps in with added tools. It offers fine-tuned control, improved resilience, and stronger security options to meet those more demanding requirements.