
Self-healing pipelines are transforming how enterprises handle software deployments. These pipelines automatically detect, diagnose, and fix issues without human intervention, making them ideal for managing complex, distributed systems. Unlike traditional CI/CD processes, which rely on manual troubleshooting, self-healing pipelines use tools like observability platforms, anomaly detection, policy engines, and auto-remediation mechanisms to maintain system health.
Key Takeaways:
- Automation: Reduces Mean Time to Recovery (MTTR) by over 50%.
- Efficiency: Handles deployment issues in under 5 minutes, compared to 20+ minutes manually.
- Scalability: Designed for environments with thousands of microservices and hybrid clouds.
- Resilience: Uses features like circuit breakers, bulkhead patterns, and event-driven architectures to prevent cascading failures.
Benefits for Enterprises:
- Faster recovery from failures.
- Reduced reliance on engineers for repetitive tasks.
- Improved uptime and system stability.
- AI-driven anomaly detection with up to 96% accuracy.
To implement self-healing pipelines, enterprises must evaluate their current pipeline maturity, address gaps in automation, and design scalable, resilient architectures. Techniques like chaos engineering, shift-left testing, and distributed pipeline models ensure readiness for large-scale operations. Observability, auto-remediation as code, and AI further enhance reliability and scalability.
Self-healing pipelines are no longer optional - they are essential for enterprises aiming to maintain uptime, reduce costs, and stay competitive in today's fast-paced tech landscape.
::: @figure 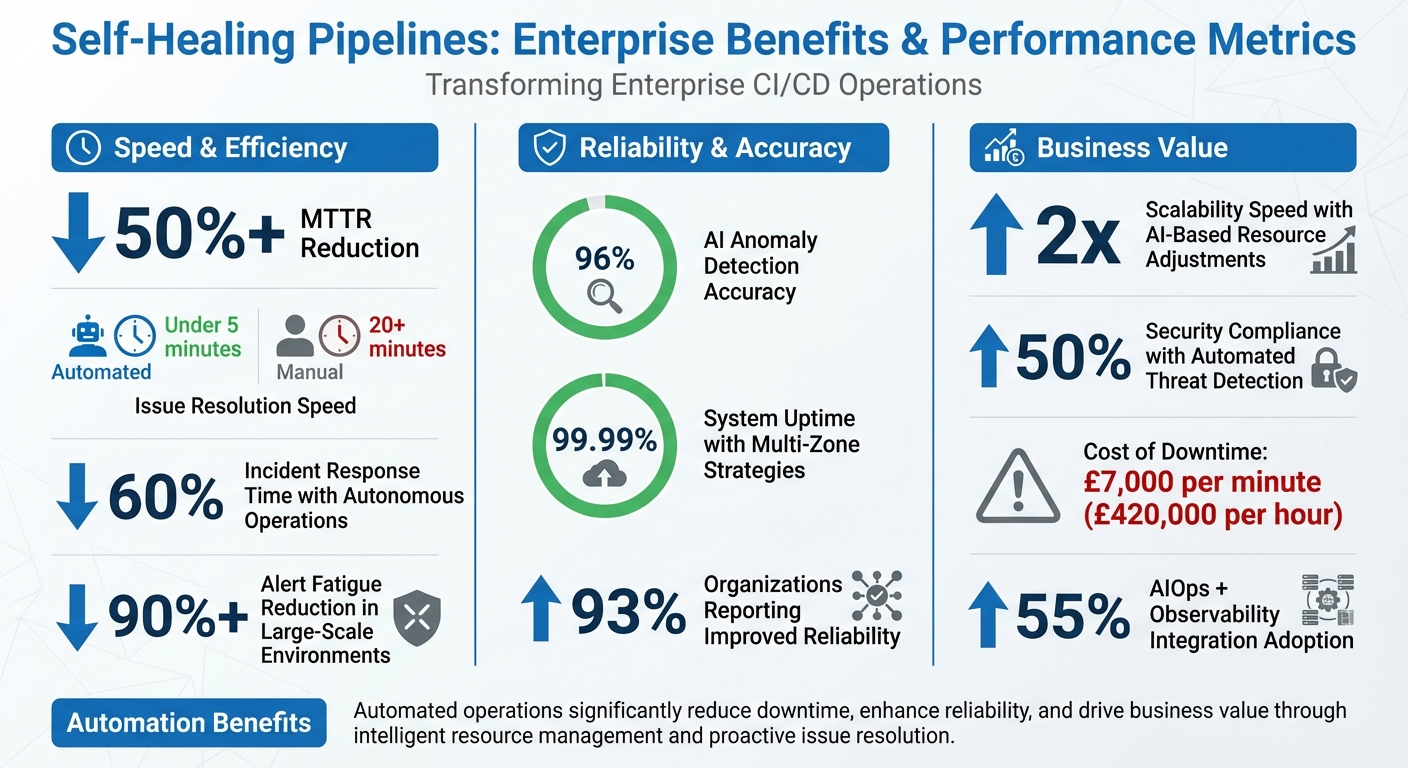 {Self-Healing Pipelines: Key Benefits and Performance Metrics for Enterprises}
:::
{Self-Healing Pipelines: Key Benefits and Performance Metrics for Enterprises}
:::
How to Architect Self-Healing CI/CD for Agentic AI
Assessing Readiness for Scaling Self-Healing Pipelines
Before scaling self-healing pipelines, enterprises need to carefully evaluate their readiness. Diving in prematurely - with underdeveloped pipelines and unstable infrastructure - can create more problems than it resolves. As CloudBees aptly puts it:
Untested, inefficient, and insecure code will lead to a 'garbage in, garbage out' scenario: production environments will be more susceptible to outages and compromise, regardless of operational tooling and monitoring[5].
In other words, a solid foundation is essential before scaling up.
Evaluating Pipeline Maturity
Pipeline maturity isn’t an all-or-nothing concept - it’s more of a spectrum. A proper assessment should cover the entire workflow, from the planning and design stages to code commits, testing, CI/CD automation, and finally, monitoring and feedback loops[5]. The goal is to pinpoint areas where manual intervention still dominates and where automation has started to take hold.
Key signs of low maturity include reliance on manual processes for tasks like resource provisioning, application restarts, and database failovers[7]. These gaps indicate that the infrastructure isn’t ready for large-scale self-healing. Distributed systems are prone to failures, so readiness means accounting for and addressing these inevitable issues.
Another crucial aspect is whether your services expose health endpoints. These endpoints should provide insights into not just the service’s state but also the health of its dependencies[4]. Without this visibility, external tools like orchestrators and load balancers won’t be able to make informed routing decisions. Additionally, implementing circuit breakers and bulkhead patterns is a sign of architectural maturity[4][3]. Circuit breakers allow systems to fail fast when remote services are struggling, preventing resource exhaustion. Bulkheads isolate system resources into separate groups, ensuring that a failure in one part doesn’t cascade across the entire system.
Understanding these indicators of maturity lays the groundwork for building scalable infrastructure.
Understanding Enterprise Scalability Requirements
Once maturity gaps are identified, the focus shifts to creating an architecture that scales independently. Scaling self-healing pipelines isn’t simply about throwing more resources at the problem. Enterprises need event-driven architectures capable of responding to issues autonomously. For example, AWS Lambda functions can be triggered by Prometheus alerts to automatically address configuration drifts or network failures[2]. As Mohamed ElEmam, a DevOps/SRE Lead, succinctly states:
If your playbook needs a human, it's already failed[2].
The infrastructure must be designed to handle scale inherently. Serverless components such as AWS Lambda, SQS, and DynamoDB enable self-healing systems to scale up or down automatically, adapting to unpredictable workloads without requiring manual intervention[6]. Furthermore, the architecture should rely on decoupled components that communicate asynchronously, reducing the risk of cascading failures[4].
Another essential element is graceful degradation. For instance, if a database goes offline, can the system still function in a limited capacity, such as operating in read-only mode?[3] Can it handle temporary issues - like brief network outages or connection losses - through built-in retry mechanisms?[4][3] These features distinguish systems that can scale effectively from those that will collapse under pressure. Testing these capabilities through chaos engineering helps validate self-healing strategies in real-world conditions[4].
Designing Scalable and Resilient Pipeline Architectures
Once you've assessed your pipeline's maturity, the next step is crafting architectures that can handle growth while automatically recovering from failures. The goal is to embed resilience into every layer of the system, ensuring it can resist breakdowns and bounce back without manual intervention.
To achieve this, focus on stateless services and asynchronous, decoupled messaging systems. These design choices allow faulty components to be replaced without disrupting the entire pipeline, reducing the risk of cascading failures caused by tightly linked components.
Incorporate Bulkhead patterns to isolate resources and prevent a single failure from overwhelming the system. Similarly, use circuit breakers to halt failing requests quickly, avoiding resource exhaustion across the system. Distributed systems are prone to occasional failures, so redundancy is key. Implement multi-zone configurations, whether active-active or active-passive, to ensure operations continue even if a failure occurs in one zone.
For scaling, some situations may call for advance resource provisioning. Over-provisioning resources to maintain virtual machines at around 75% utilisation can help handle sudden spikes in demand without compromising performance [8].
Incorporating Shift-Left Principles
Building a resilient pipeline isn't just about robust architecture - it also requires early testing and monitoring. By shifting testing and validation to the earliest stages of development, you can catch potential issues before they escalate into production bottlenecks. This approach, known as shift-left practices, helps address failures when they are easiest and cheapest to fix.
For example, pre-commit hooks can catch syntax errors, static analysis tools can identify vulnerabilities, and contract testing ensures API schemas align with their specifications. If API contracts change unexpectedly, self-healing automation can detect and address discrepancies early in the pipeline, reducing the risk of downstream integration failures.
Data-heavy pipelines also benefit from tools like schema drift detection. Preflight checks and schema registries can identify changes in data structures - whether additions or deletions - and either map these changes automatically or quarantine problematic data before it impacts downstream processes. As Bacancy Technology puts it:
The future of data engineering isn't just building pipelines, it's building pipelines that fix themselves. [9]
A forward-thinking approach to resilience includes simulation and modelling to predict and neutralise potential failures before they occur. By testing configurations in virtual environments, enterprises can avoid costly unplanned downtime, which averages £7,000 per minute - or roughly £420,000 per hour [10].
Key Features of a Resilient Pipeline
Resilient pipelines are defined by their ability to scale and recover seamlessly. Some essential features include:
- Progressive delivery tools: Canary releases and feature flags allow for controlled rollouts of new features. Platforms like LaunchDarkly or Split enable teams to disable problematic features instantly, avoiding the need for full rollbacks.
- Health monitoring: Standardised health endpoints should not only report the status of a service but also provide insights into the health of its dependencies. This enables orchestrators and load balancers to reroute traffic away from struggling instances automatically.
- Infrastructure as Code (IaC): Tools like Terraform and Pulumi ensure environments remain reproducible and auditable. IaC allows for automatic re-provisioning of infrastructure to a stable state, reducing human error and minimising customer impact during failures.
- Intelligent retry mechanisms: Use exponential backoff with jitter for retries, which helps manage transient failures without overloading resources. For long-running transactions, include checkpoints to resume processes from the last successful state.
These features separate pipelines that can handle pressure from those that collapse under strain. By combining thoughtful design with proactive practices, you can ensure your architecture is ready for both growth and the unexpected.
Implementing Automation and Monitoring at Scale
Scaling self-healing pipelines involves more than just responding to alerts; it’s about creating systems that can resolve issues automatically. This shift - moving from a detect and alert
mindset to automated remediation - is changing how large organisations manage failures at scale [11]. Instead of constantly interrupting engineers, well-crafted automation handles frequent problems before they affect users. The strategies outlined below highlight how this automation can be effectively implemented.
Integrating Auto-Remediation as Code
Auto-remediation operates through a structured four-step process: detection, decision, action, and verification. Here’s how it works:
- Detect: Monitor event sources like CloudTrail to identify issues.
- Decide: Use compliance logic to determine if action is necessary.
- Act: Fix the problem by executing an API call or running a script.
- Verify: Confirm the fix through logging and success checks [11].
Tools like Lambda functions (using Python or Node.js), Ansible Playbooks, and PowerShell scripts are commonly triggered by event buses such as Amazon EventBridge or Azure Event Hubs [11][12][3]. The key to success here is idempotency - ensuring scripts deliver the same outcome every time they’re run, avoiding duplicate actions or resource damage [11].
Start with smaller, low-risk tasks like adding missing tags or labels. Once confidence builds, tackle more complex actions, such as restarting services or deleting resources. For critical changes, incorporate human approval workflows to maintain control [11]. This structured approach not only ensures reliability but also sets the stage for improved system observability, which we’ll explore next.
Enhancing Observability and Metrics
Monitoring at scale demands a unified view of telemetry spanning infrastructure, applications, and platform services [13][16]. Combining white-box monitoring (focused on internal metrics like JVM statistics) with black-box monitoring (tracking external behaviour) ensures both potential issues and active user-facing problems are detected [15][16].
To trace problems effectively in distributed systems, cross-system correlation IDs are indispensable [13][16]. Teams can also focus on the Four Golden Signals to gauge system health:
- Latency: The time taken to process requests.
- Traffic: The volume of system demand.
- Errors: The rate of failures.
- Saturation: Resource usage levels.
Alerts tied to these signals highlight when thresholds are breached, helping teams act before minor issues escalate. For example, a 2025 SRE report noted that autonomous operations can cut incident response times by 60% [2].
Leveraging AI for Proactive Scaling
AI is reshaping self-healing systems by making them predictive rather than reactive. Machine learning (ML) models can spot intricate failure patterns, such as memory leaks or gradual dips in performance [18][19].
Take Microsoft Azure’s Hardware Failure Prediction solution as an example: it uses ML to predict failures in disks, memory, and network routers. When risks are identified, customer VMs are automatically migrated to healthy nodes, avoiding disruptions [19]. Another Azure system, Gandalf
, analyses temporal and spatial patterns to detect latent problems that might surface days after a deployment, halting risky rollouts automatically [19].
AIOps platforms further streamline operations by grouping related alerts into broader incidents, cutting through the noise. This approach can reduce alert fatigue by over 90% in large-scale environments [17]. Today, 55% of organisations pair AIOps with observability tools to simplify IT incident management [17]. As Mark Russinovich, CTO of Azure, aptly puts it:
In the era of big data, insights collected from cloud services running at the scale of Azure quickly exceed the attention span of humans [19].
Scaling Self-Healing Pipelines for Enterprise Growth
Distributed Pipeline Architecture
As enterprises expand, relying on centralised pipelines can lead to bottlenecks that slow down operations. A distributed pipeline architecture is a smarter approach, offering the flexibility needed to support various teams, regions, and environments while removing single points of failure.
One effective method is the Deployment Stamps Pattern, which breaks the pipeline into independent units, or stamps
. Each stamp operates on its own, so if one fails, the others continue running smoothly. This minimises disruptions and simplifies pipeline management. Teams can reuse successful configurations across different regions or business units instead of managing an unwieldy, centralised system [3][8].
A great example of this principle in action is Google's Workflow
system, introduced in 2003. This system replaced fragile batch pipelines with a continuous processing model using a Leader-Follower architecture. Here’s how it works: a Task Master
(Leader) keeps job states in memory and logs changes to disk, while stateless workers (Followers) handle task execution. This design achieves exactly-once processing, scales to thousands of workers, and maintains key attributes like configuration accuracy, lease management, and unique filenames [20]. As Dan Dennison, a Google SRE, explains:
The collective SRE experience has been that the periodic pipeline model is fragile... organic growth and change inevitably begin to stress the system, and problems arise.[20]
To further protect the system, the Bulkhead Pattern isolates resources, ensuring that a failure in one area doesn’t cripple the entire pipeline [3][4]. Pair this with asynchronous communication using message brokers or service buses. This keeps components decoupled, even during high-load scenarios, and prevents cascading failures [3][4].
Additionally, health endpoints are essential. They allow orchestrators to direct traffic to healthy nodes and enable automated failover across availability zones during regional issues [3][4].
By adopting this distributed design, enterprises can prepare their infrastructure to handle heavy workloads more efficiently.
Optimising Resource Management
Once a scalable architecture is in place, efficient resource management becomes the next priority. Supporting thousands of builds daily isn’t just about adding capacity - it’s about using resources wisely to avoid waste and bottlenecks.
A multi-layered autoscaling strategy works best. Combine Horizontal Pod Autoscaling (HPA) for predictable loads with Vertical Pod Autoscaling (VPA) for unexpected demand spikes. Be cautious, though - don’t use both types of autoscaling on the same metrics (e.g., CPU or memory), as this can create conflicts [21]. Keep in mind that VPA needs at least 24 hours of historical data to make accurate recommendations [21].
For immediate scaling, consider deploying pause pods. These low-priority pods act as placeholders, reserving buffer space. When high-priority tasks arise, pause pods are preempted, allowing resources to be reallocated instantly - avoiding delays caused by provisioning new nodes [21]. To calculate the right buffer size, use the formula: 1 - (buffer / (1 + traffic)). For instance, with a 30% buffer and 40% expected traffic growth, you’d need a 50% overprovisioning margin [21].
To handle sudden traffic spikes, use queue-based load levelling. This approach buffers tasks in a queue, preventing surges from overwhelming backend systems and giving your pipeline time to scale up before hitting peak loads [4][20].
For storage, ephemeral OS disks are a great choice. They allow for faster reimaging and lower latency, which is ideal for stateless workloads that need quick recovery [21]. Always match your disk’s IOPS and throughput with the specifications of your VM SKU to avoid storage bottlenecks during high-demand periods [21]. As Microsoft’s Azure Well-Architected Framework advises:
Design your workload to be stateless to the extent practical... Stickiness can limit your scaling ability and introduces single points of failure.[8]
Finally, reserve system node pools specifically for critical OS daemons. This ensures that application-level failures don’t drain resources needed for the underlying infrastructure [21]. To control costs, set hard limits on the maximum number of scale units that can be automatically added during scaling events [8].
Validating and Deploying Scaled Pipelines
Testing Auto-Remediation in Pre-Production
Before rolling out self-healing pipelines, it's essential to test them in a staging environment that mirrors production in terms of reliability, capacity, and security [22]. This involves running a variety of tests - unit, smoke, UI, load, stress, and performance tests - alongside chaos engineering. Tools like Azure Chaos Studio or AWS Fault Injection can simulate real-world failures, such as node shutdowns, network issues, or resource exhaustion. These scenarios help validate how well remediation workflows perform under pressure [4][22]. The goal is to replicate the conditions of a fully scaled, enterprise-grade pipeline during testing.
Microsoft's Azure documentation highlights a common pitfall:
The success path often receives thorough testing, but the failure path doesn't. A system can run in production for a long time before a failure path is triggered.[4]
To address this, conduct a Failure Mode Analysis (FMA) to identify risks and evaluate whether failures could lead to partial or complete outages [22]. When testing automated remediation workflows, ensure the entire process is validated. This includes defining the workflow, configuring trigger events (like a CloudWatch alarm), and verifying that the automation runs correctly in pre-production. Synthetic loads can simulate traffic without impacting real users [14][22]. To maintain consistency, version-control all test scripts and configurations [22].
Deploying with Zero-Downtime Strategies
Once testing confirms readiness, deployment must be executed without interrupting operations. Techniques like Blue-Green deployments allow instant traffic switching, while canary releases enable gradual rollouts with automated monitoring of key metrics [23][24].
Rahul Kumar, a software architect, emphasises:
Blue-Green and Canary Deployments are critical for modern cloud-native microservices... ensuring zero-downtime releases is a must-have in production-grade systems.[23]
Traffic orchestration tools, such as service meshes (Istio, Linkerd) or application load balancers, can manage routing between versions [23]. During transitions, database migrations should be non-destructive, using tools like Liquibase or Flyway, as both old and new application versions might run simultaneously [24]. Wrapping new features in feature flags allows you to toggle functionality on or off without redeploying. Additionally, externalising sessions with stateless authentication (e.g., JWT) or Redis ensures users stay logged in during traffic shifts [23]. Health endpoints (e.g., /actuator/health
) are essential for load balancers to check service readiness [23].
After deployment, continuous monitoring ensures the pipeline remains stable and responsive, completing the self-healing cycle.
Monitoring and Feedback Loops
Post-deployment, rigorous monitoring is key to maintaining the reliability of scaled pipelines. Set up health state thresholds to trigger alerts and initiate corrective actions as soon as anomalies are detected [16]. This monitoring framework works hand-in-hand with automation, ensuring swift responses to performance deviations.
Comprehensive telemetry is essential. Collect metrics, resource logs, and traces to gain a complete view of the system [16]. Use standardised instrumentation, such as OpenTelemetry, to ensure consistency across your infrastructure. Persisting correlation IDs across service boundaries is crucial for diagnosing issues in distributed systems [16].
Automated recovery processes should be fully observable. Real-time dashboards can track the status of auto-remediation efforts, and automated checks can confirm that the system has returned to a steady state after recovery [25]. Always include a manual override (an Andon Cord
) to halt automated recovery if needed [25].
Combine white box monitoring (internal metrics like memory usage and latency) with black box monitoring (end-user experience and service-level indicators) for a complete picture of system health. Structured logging helps streamline data analysis, and health models and alert thresholds should be continuously refined based on lessons learned from incidents [16].
Conclusion
Self-healing pipelines are revolutionising enterprise CI/CD operations. According to research, 93% of organisations that have adopted these systems report improved reliability, while AI-powered anomaly detection boasts an impressive 96% accuracy in identifying issues before they escalate [1][26]. The result? Downtime is slashed, and mean time to recovery (MTTR) sees a dramatic reduction.
These technical benefits directly drive business success. Companies leveraging scalable self-healing solutions achieve 99.99% uptime using multi-zone strategies, double their scalability speed through AI-based resource adjustments, and enhance security compliance by 50% with automated threat detection and patching [26]. As Jennifer Thomas from Microsoft Azure puts it:
With Azure Integration Services, companies aren't just automating their processes; they're transforming into agile beasts capable of keeping up with the rapid-fire digital world [26].
To capitalise on these advantages, the next step is clear: take action now. Start by assessing whether your systems have moved beyond static alerts to AI-driven anomaly detection. Address repetitive issues and automate routine maintenance before expanding to complex, multi-cloud environments. Adopt resilient design patterns like circuit breakers and use chaos engineering to test your systems' self-healing capabilities in production-like conditions [4].
Making the leap from reactive to autonomous operations is no longer optional. Schedule annual disaster recovery drills, centralise log analytics, and ensure every service provides health endpoints that reflect both its internal state and dependency statuses. Tools like Azure Automation make this transition accessible, offering 500 free job minutes per subscription, with additional minutes costing around £0.14 each [26].
If you're looking for expert support in optimising your self-healing pipelines, Hokstad Consulting (https://hokstadconsulting.com) provides tailored strategies for DevOps transformation and cloud infrastructure optimisation. The question isn't whether to embrace self-healing pipelines - it’s how quickly you can get started. Organisations that act now will gain a critical edge in reliability, scalability, and cost efficiency.
FAQs
How can enterprises start implementing self-healing pipelines?
To get started with self-healing pipelines, the first step is to integrate real-time monitoring into your CI/CD workflows. This allows failures to be automatically spotted the moment they happen. Once that's in place, the next move is to implement automated root-cause analysis and remediation steps. These could include retries, regenerating dynamic selectors, or applying specific fixes that address recurring issues.
The final piece of the puzzle is embedding these automation scripts or plugins directly into your pipeline tools, such as Jenkins. This addition brings self-healing capabilities to life, helping to reduce downtime, boost efficiency, and build a more robust pipeline suited for large-scale operations.
How do self-healing pipelines enhance system resilience and minimise downtime?
Self-healing pipelines bring a new level of resilience to systems by identifying and fixing issues on their own. Whether it’s dealing with locator mismatches, timing glitches, or environment-related errors, these pipelines step in to take actions like regenerating selectors, tweaking wait times, or even restarting services. All of this happens without the need for human involvement.
By automatically re-running disrupted processes, these pipelines keep CI/CD workflows moving smoothly, cutting down on downtime caused by interruptions. This not only boosts system reliability but also streamlines operations, making them especially valuable for large organisations managing complex systems.
How does AI improve the efficiency of self-healing pipelines in large organisations?
AI plays a transformative role in boosting the efficiency of self-healing pipelines by automating essential processes. It can identify failures as they happen, sift through logs with advanced models to pinpoint the root cause, and take corrective steps like updating selectors, tweaking scaling parameters, or crafting remediation scripts - all without human involvement.
This level of automation not only minimises downtime but also enhances the reliability and adaptability of systems. For large organisations handling intricate infrastructures, this makes AI an ideal solution to keep pipelines resilient and responsive to shifting demands.