
Handling failures in distributed systems requires more than just retrying failed operations. Without the right strategies, retries can worsen issues, overwhelm services, and lead to cascading failures. Here's what you need to know:
- Retries are a way to handle temporary issues like network timeouts or service overloads. However, they need to be paired with backoff strategies to avoid overloading systems.
- Backoff introduces delays between retries, with options like fixed intervals, exponential backoff, and jittered backoff (randomised delays to prevent synchronised retries).
- Idempotency is critical. Operations should produce the same result no matter how many times they're retried to prevent unintended side effects.
- Retry budgets limit retries to a small percentage of total requests (e.g., 10%) to control load and avoid retry storms.
- Circuit breakers stop retries when a service is persistently down, protecting the system from further strain.
Key Takeaways
- Use exponential backoff with jitter for high-load systems to avoid synchronised retries.
- Retry only for transient errors (e.g., HTTP 429, 503) and skip retries for persistent errors (e.g., 400, 401).
- Monitor retries, ensure idempotency, and respect
Retry-Afterheaders to minimise risks.
These strategies help distributed systems recover gracefully from failures without turning minor issues into major outages.
Retry & Backoff Strategies: Handling Failures in Distributed Systems
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Common Failures in Distributed Systems
Grasping the different ways distributed systems can fail is essential for designing effective retry and backoff strategies. These systems don’t fail in a single, predictable way - they fail in diverse and sometimes unexpected manners.
Transient Failures
Transient failures are short-lived issues that usually resolve on their own. Examples include dropped network packets, DNS timeouts, or a service temporarily struggling with high traffic. These are the exact kinds of problems where retry logic shines.
Common transient errors include HTTP status codes like 408, 429, 503, and 504. These codes generally indicate that a service is either overwhelmed or briefly unreachable [1][5][7]. Interestingly, for a service with 99% availability, implementing a single client-side retry can theoretically boost perceived availability to 99.99% - a massive improvement from two nines to four nines [8].
Persistent Failures
Persistent failures, on the other hand, are more serious and long-lasting. These include issues like database outages, bad deployments, or client-side errors such as HTTP 400, 401, 403, and 404. Retrying in these situations won’t help and might even make things worse. Instead, handling these failures often requires tools like circuit breakers [1][5][7].
The real danger comes when persistent failures are paired with poorly designed retry logic. Sujeet Jaiswal, a Principal Software Engineer, highlights this risk:
Naive retries do not just fail to help - they actively cause the outages they are trying to recover from [2].
For example, a failing service under heavy retry traffic can lead to cascading failures. In complex systems, a single failure at depth 3 with just two retries per layer can result in a 27× traffic surge to the failing service [8].
Beyond Transient and Persistent Failures
Distributed systems can also face more complex issues like Byzantine and partial failures. Byzantine failures occur when a service responds with incorrect or corrupted data - often due to stale caches or silent data corruption. Partial failures happen when only some replicas of a service fail while others remain functional. These scenarios demand more advanced detection and handling techniques, as basic retry logic won’t suffice [7].
The table below summarises the various failure modes and their suitability for retries:
| Failure Mode | Characteristics | Retryable? |
|---|---|---|
| Transient | Temporary issue; resolves on retry | Yes (with backoff) [7] |
| Persistent | Extended outage or client-side error | No (requires circuit breakers) [7] |
| Cascading | One failure triggers a chain reaction | No (causes thundering herd) [7][2] |
| Byzantine | Incorrect or corrupted responses | No (hardest to detect) [7] |
Understanding these failure modes is the first step toward building resilient systems that can handle the unexpected.
Retry and Backoff Strategies
When working with distributed systems, understanding failure patterns is only part of the challenge. The next critical step is choosing a retry strategy that fits the situation. The wrong approach can escalate a minor issue into a major outage.
Immediate Retry
This method retries an operation with no delay between attempts. While it might work for rare, sub-millisecond errors, it can easily cause thundering herd problems during network operations. Without a pause, systems under stress don't get the chance to recover, potentially worsening the issue.
Fixed Interval Retry
Here, retries happen after a consistent delay (e.g., one second). This gives dependent systems time to recover but can lead to synchronised traffic spikes. For example, if multiple clients fail simultaneously, they retry in unison, creating bursts of traffic [1][4]. While this approach works in low-concurrency environments, it struggles to handle larger-scale systems effectively.
Exponential Backoff
Exponential backoff increases the delay after each failure, often doubling it with each attempt. For instance, starting at 100 ms, the fifth retry would occur after 800 ms [1]. This strategy reduces system strain over time, as Ayooluwa Isaiah from Better Stack explains:
Exponential backoff is particularly effective because it starts with quick retries for potentially brief disruptions, then rapidly backs off to give overwhelmed systems time to recover [3].
However, without randomisation, retries can still synchronise. Clients failing at the same time will calculate identical delays, leading to simultaneous retries [2][9]. To avoid impractical delays, always set a maximum cap - usually between 30 and 60 seconds - especially for user-facing applications [1][3].
Jittered Backoff
Jittered backoff solves the synchronisation issue by introducing randomness into retry intervals. Each client waits a random amount of time, anywhere between 0 and the calculated delay. This spreads requests over a broader time window, preventing synchronised spikes. A 2015 AWS study found that full jitter
offers the best throughput under heavy contention, as it evenly distributes the load [1]. The formula looks like this:
sleep = random(0, min(cap, base * 2^attempt)) [2].
A real-world example comes from March 2017, when Discord faced a thundering herd issue. Their presence-tracking server became unresponsive, and millions of Erlang processes attempted to reconnect simultaneously, exhausting memory on session nodes. Discord resolved the issue by combining jittered backoff with strict connection caps [2]. For systems with numerous clients, combining exponential backoff with full jitter is often the go-to solution [1].
Adaptive Retries
Adaptive retries take a more dynamic approach, adjusting retry behaviour using real-time telemetry like error rates, latency, or retry budgets
[3][9]. These strategies assume that client requests target a single resource, meaning that throttling one resource impacts all traffic from that client [2]. Instead of setting a fixed retry count, adaptive methods monitor the ratio of retries to total requests. Retries are only allowed if this ratio stays below a threshold, typically 10%. Production retry budgets often range from 5% to 10%, enabling recovery without triggering cascading failures [1][2][5].
This approach represents a more advanced level of resilience, often requiring centralised retry management or machine learning to fine-tune parameters. It's especially useful for large-scale, complex architectures where traditional backoff methods may still lead to retry storms [9].
To summarise the differences, here's a quick comparison:
| Strategy | Avg Load on Dependency | Client Wait Time | Desynchronisation | Best Use Case |
|---|---|---|---|---|
| Immediate Retry | Very High | Near Zero | None | Local, sub-millisecond errors [1] |
| Fixed Interval Retry | High (Waves) | Predictable | None | Low-concurrency, simple systems [1][4] |
| Exponential Backoff | Medium (Waves) | Grows Fast | None | Reducing pressure on scaling systems [4] |
| Jittered Backoff | Low | Moderate | High | High-load distributed systems [1][4] |
| Adaptive Retries | Very Low | Dynamic | High | Systems needing SLO-aware resilience [9] |
Implementation Best Practices
Building on the retry and backoff strategies discussed earlier, these implementation tips will help ensure these concepts work effectively in live systems.
Preventing Retry Storms
A retry storm happens when multiple clients fail at the same time and retry in sync, overwhelming an already struggling service. Adding jitter - a random variation in retry intervals - can break this synchronisation. Without jitter, even exponential backoff can result in waves of synchronised traffic.
Take Discord’s presence service as an example. Synchronised retries overwhelmed their servers, leading to the implementation of hard caps on in-flight connections and a fast-fail mechanism for the sessions-to-presence dependency [2].
To avoid amplifying load, use retry budgets. Limit the retry-to-request ratio to 10%. Here’s why: a single user request passing through three service layers, each retrying up to four times, can result in up to 64 attempts at the failing service [2]. Sujeet Jaiswal, Principal Software Engineer, provides this insight:
The discipline is not 'retry harder when things fail.' It is 'retry only when retrying is likely to help, only as much as your budget allows, only at the right layer, and only for operations that are safe to repeat.' [2]
Retries should also be implemented at just one layer - preferably the layer directly above the one rejecting requests. This avoids multiplying the load on a failing service and gives it the breathing room it needs to recover [2][10].
Once these safeguards are in place, the next step is to configure retry policies.
Configuring Retry Policies
Start by classifying errors. Retry only for transient errors (e.g. 408, 429, 503, 504), and skip retries for permanent errors (e.g. 400, 401, 403, 404). For 500 errors, retry only if the operation is idempotent [2].
Idempotency is critical for write operations. Twilio’s incident involving non-idempotent operations led to duplicate charges, proving how essential idempotency is. Using Idempotency-Key headers can help avoid these duplicate side effects.
Respect Retry-After headers, and add slight jitter to prevent synchronised retry waves. Set a maximum delay cap - typically 30 to 60 seconds - to keep retries from blocking caller threads indefinitely [2]. For asynchronous tasks, use dead letter queues (DLQs) to capture messages that fail after all retries. These can then be inspected manually or replayed later [1].
Testing and Monitoring
Testing and monitoring are vital to ensure retry strategies work as expected in production.
Monitor which retry attempt typically resolves the issue. For instance, if 90% of recoveries occur on the second attempt, five retries might be unnecessary [1][2]. Log detailed metadata for each retry, such as operation name, attempt number, delay, actual sleep time, and error codes or headers.
Keep an eye on the retry budget. If the retry-to-request ratio exceeds 10%, force immediate failures. Use delay histograms in dashboards to confirm that jitter is spreading the load effectively and preventing synchronised spikes [2].
For dead letter queues, monitor not just the queue depth but also the age of the oldest message and the specific reasons for failures. A few very old messages could signal a deeper issue [1]. As Let's Build Solutions aptly notes:
Retries that you cannot see are retries you cannot tune. [1]
Strategy Comparison
::: @figure 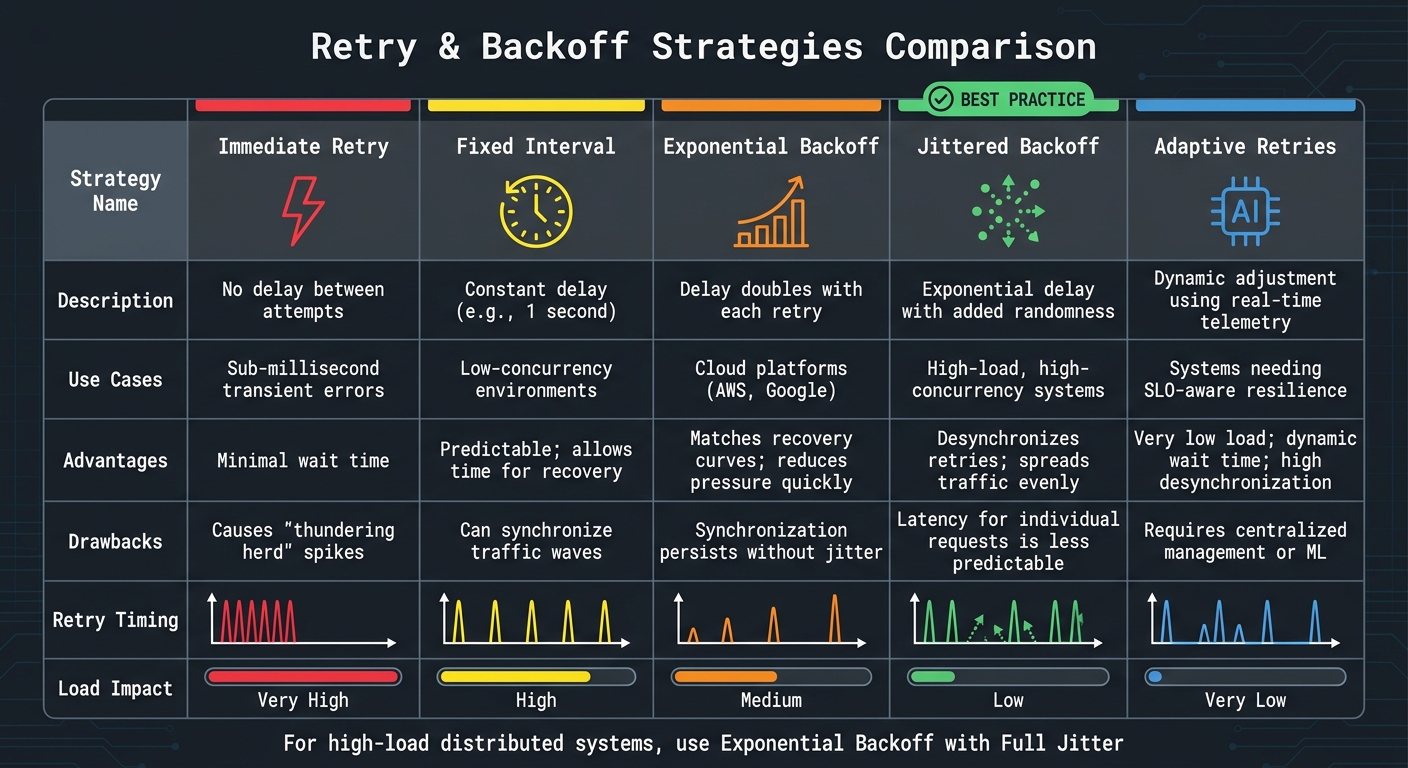 {Retry and Backoff Strategies Comparison for Distributed Systems}
:::
{Retry and Backoff Strategies Comparison for Distributed Systems}
:::
This section breaks down and compares the retry strategies discussed earlier, helping you weigh their strengths and weaknesses based on your system's needs.
The best retry strategy for your setup depends on factors like system scale, concurrency levels, and how much latency your application can handle. Each method balances efficiency, reliability, and complexity differently.
Immediate retry is effective for handling transient errors lasting less than a millisecond. However, it can lead to the thundering herd
problem, where multiple clients retry simultaneously, overwhelming the system [1].
Fixed interval retry introduces a consistent delay between retries, allowing services time to recover. While predictable, it can cause synchronised traffic spikes, making it better suited for systems with low concurrency [1].
Exponential backoff improves on fixed intervals by doubling the delay with each retry (e.g., 100 ms, 200 ms, 400 ms). This approach aligns well with how systems recover from overloads, easing pressure quickly [2]. But without randomisation, clients can still retry in sync, maintaining traffic surges [2].
Jittered backoff adds randomness to exponential delays, preventing synchronised retries. A 2015 analysis by AWS showed that full jitter evenly distributes retries, maximising throughput under heavy loads [1]. This makes jittered backoff a go-to choice for distributed systems handling high load and concurrency [1].
The table below summarises these strategies, highlighting their trade-offs to help you make an informed choice.
Comparison Table
| Strategy | Description | Use Cases | Advantages | Drawbacks |
|---|---|---|---|---|
| Immediate Retry | No delay between attempts. | Sub-millisecond transient errors [1]. | Minimal wait time. | Causes thundering herdspikes [1]. |
| Fixed Interval | Constant delay (e.g., 1 second). | Low-concurrency environments [1]. | Predictable; allows time for recovery. | Can synchronise traffic waves [1]. |
| Exponential Backoff | Delay doubles with each retry. | Cloud platforms (e.g., AWS, Google) [2]. | Matches recovery curves; reduces pressure quickly [2]. | Synchronisation persists without jitter [2]. |
| Jittered Backoff | Exponential delay with added randomness. | High-load, high-concurrency systems [1]. | Desynchronises retries; spreads traffic evenly [1]. | Latency for individual requests is less predictable [1]. |
This breakdown offers a clearer view of how each strategy aligns with different system requirements, setting the stage for exploring tools and frameworks that implement these methods effectively.
Tools and Frameworks
When it comes to implementing retry and backoff logic, several tools and frameworks can simplify the process. These options range from pre-configured solutions to fully custom implementations, depending on your needs. The choice boils down to where you want to handle retries - whether at the application level, within your infrastructure, or through a managed service. Each route has its own level of complexity, control, and integration with your existing code. Below are three approaches to consider: configuration-based workflows, library-driven solutions, and custom-coded implementations.
AWS Step Functions
AWS Step Functions lets you define retry and backoff strategies without needing to write custom code. Using the Amazon States Language, you can configure parameters like MaxAttempts, BackoffRate, and Interval directly in JSON or via a visual editor [14].
By default, the BackoffRate is set to 2.0, meaning the wait time doubles with each retry, which aligns with the exponential backoff method discussed earlier [12]. This makes AWS Step Functions particularly useful for long-running workflows where state persistence is critical, such as coordinating microservices or managing asynchronous tasks.
Netflix Hystrix
Netflix Hystrix, along with its successor Resilience4j, combines retry logic with a circuit breaker to avoid overloading failing services [1][2]. Resilience4j is widely used in Java-based microservices, offering granular control over retry policies through annotations and configuration [13]. However, this approach requires modifications to your codebase and can add complexity, making it better suited for cases where retry logic is tightly tied to specific application behaviours.
Custom Implementation
If you need complete control over retry logic, a custom implementation might be the way to go. This allows you to design specific algorithms, such as jitter-based delays, retry budgets, and deadline-aware logic [1][2]. A common formula for capped exponential backoff is:
delay = min(cap, base * 2^attempt)
For added randomness, you can incorporate Full Jitter, where the actual delay is a random value between 0 and the calculated maximum delay [2].
When creating custom retry mechanisms, ensure the operations are idempotent. For instance, you can use an Idempotency-Key to avoid unintended side effects. A cautionary tale comes from Twilio in July 2013, when a Redis misconfiguration caused balance writes to fail. Their auto-recharge system, lacking idempotency, triggered multiple charges for the same operation, affecting 1.4% of customers [2].
Idempotency is a property of the operation, not of the retry helper. A retry library cannot make a charge-card-then-update-balance flow safe.– Sujeet Jaiswal, Principal Software Engineer [2]
While custom implementations offer unmatched flexibility, they are best reserved for scenarios where off-the-shelf tools cannot meet specific performance or control needs. For most cases, it’s wise to start with built-in SDK features. For example, the AWS SDK’s Standard mode uses exponential backoff with a 100ms base delay and a maximum of 3 attempts [11], providing a solid foundation before diving into custom solutions.
Conclusion
To ensure system resilience, a well-thought-out retry and backoff policy is essential. These strategies are the backbone of a microservices architecture's ability to recover gracefully from failures without turning minor issues into major outages. The distinction between an effective retry policy and a poorly designed one can determine whether your system weathers a brief network hiccup or succumbs to a cascading failure that disrupts your entire platform.
The approach must be carefully calibrated: retries should only occur when they are likely to succeed, within operational limits, at the appropriate layer, and for operations that are safe to repeat. This involves filtering errors to separate transient issues (e.g., HTTP 429, 503, 504) from permanent ones (e.g., 400, 401), using exponential backoff with Full Jitter as the default, and setting limits on both maximum delays (30–60 seconds) and total attempts (3–5) to avoid resource strain. Additionally, employing a per-client retry budget - typically limiting retries to 10% of total requests - helps keep load amplification under control, capping it at approximately 1.1x per layer instead of the 3x or more seen with unrestricted retries [2].
Desynchronised retries must also strictly adhere to idempotency rules. As Sujeet Jaiswal, Principal Software Engineer, explains:
Idempotency is a property of the operation, not of the retry helper. A retry library cannot make a charge-card-then-update-balance flow safe [2].
Non-idempotent operations demand extra vigilance, as illustrated by incidents like Twilio's 2013 auto-recharge failure, which highlighted the dangers of retrying unsafe operations.
Retries should also integrate circuit breakers to halt attempts when a dependency is persistently down. These mechanisms should respect Retry-After headers and incorporate jitter to avoid synchronised traffic spikes [2][6]. Whether you rely on tools like AWS Step Functions for configuration-driven workflows, Resilience4j for library-based solutions, or custom-built implementations for maximum flexibility, the core principles remain consistent: desynchronise retry attempts, enforce retry budgets, and ensure operations are safe to repeat.
While the formulas behind these strategies may seem straightforward, their execution requires precision. When applied correctly, these methods safeguard the reliability and efficiency of your microservices architecture.
FAQs
How do I choose the right retry strategy for my service?
Choosing the right retry strategy requires a clear understanding of the types of failures you’re dealing with and the specific needs of your system. For transient failures - those temporary glitches that often resolve themselves - exponential backoff with jitter is a smart choice. This approach spreads out retries, reducing the chance of overwhelming the system or creating retry storms.
For permanent errors, retries are not helpful and should be avoided altogether. Additionally, using capped delays ensures that wait times don’t spiral out of control, keeping retries manageable.
To build a truly resilient system, pair your retry strategy with tools like monitoring and circuit breakers. These help you adjust and refine your approach, maintaining stability and reliability across your services.
How can I make write operations safe to retry?
When handling write operations in distributed systems, it's crucial to make them safe for retries. One effective approach is using idempotency patterns, which ensure that repeating the same operation doesn't cause unintended consequences. For example, implementing client-generated idempotency keys can help prevent duplicate processing by uniquely identifying each operation.
To further enhance reliability, pair idempotency with retry strategies like exponential backoff (gradually increasing the time between retries), jitter (adding randomness to avoid spikes in traffic), and retry budgets (limiting the number of retries to reduce system strain). Additionally, incorporating tools like circuit breakers and retry limits can help manage load and improve overall system stability.
Where should retries live in a microservices call chain?
Retries should be implemented near the point where a service interacts with external systems - usually within the client or caller component. This keeps failure handling contained and helps prevent wider disruptions. To minimise risks like retry storms, it's wise to pair retries with methods like exponential backoff and jitter. These approaches promote stability and help maintain reliability, especially during partial outages or recovery phases.