
Quality of Service (QoS) in hybrid cloud environments focuses on managing network performance - like bandwidth, latency, and packet loss - across mixed infrastructure (on-premises and cloud). Unlike single-environment networks, hybrid setups face unique challenges:
- Inconsistent performance: Traffic moves between private and public networks with varying speeds, introducing latency and bottlenecks.
- Limited control: QoS tools often fail on the public internet due to inconsistent prioritisation.
- Visibility gaps: Limited data collection makes diagnosing and resolving issues harder.
- Dynamic scaling issues: Resource allocation struggles during high traffic.
Key solutions include unified monitoring, traffic prioritisation, and AI-driven tools. These approaches improve visibility, optimise resource use, and ensure consistent performance for critical services like VoIP or high-transaction systems. For businesses, effective QoS directly impacts customer satisfaction, operational efficiency, and cost management.
::: @figure 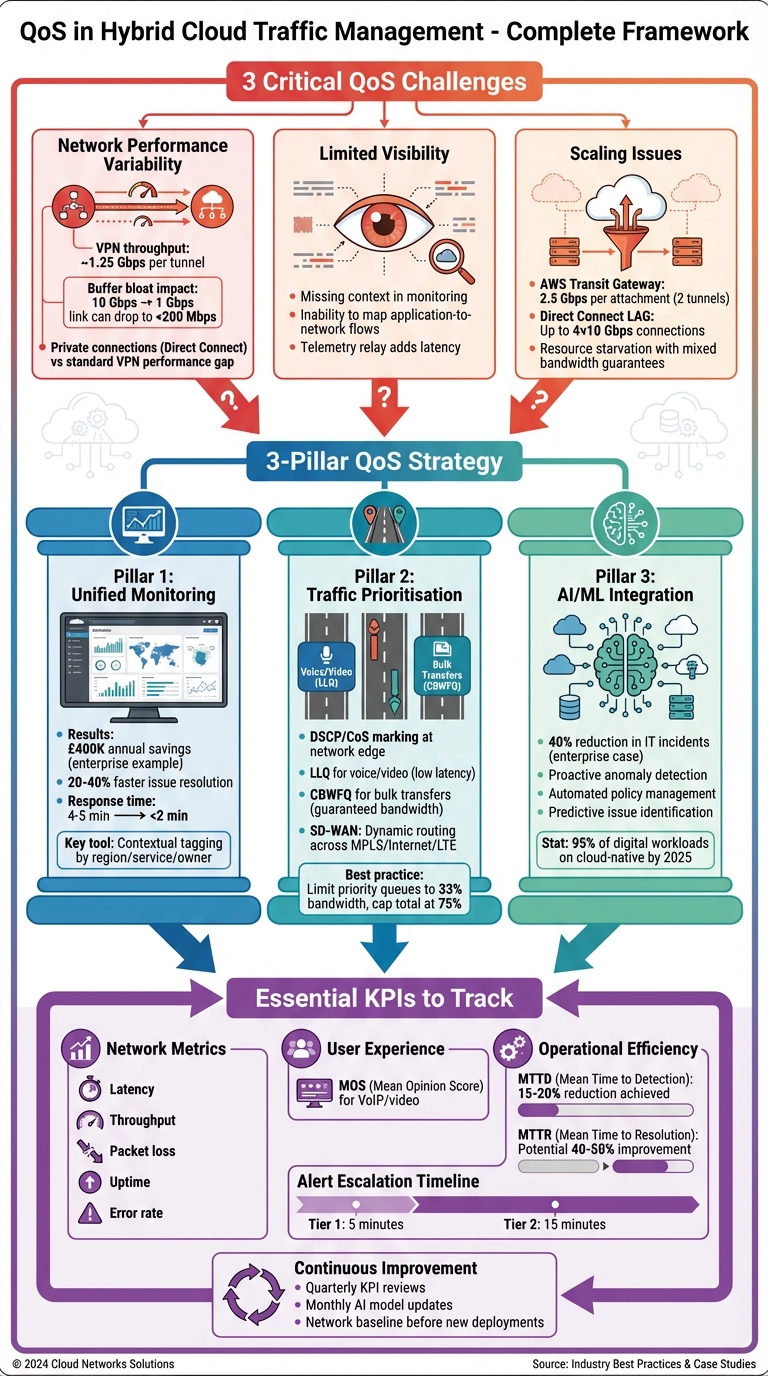 {QoS Hybrid Cloud Management Framework: Problems, Solutions & KPIs}
:::
{QoS Hybrid Cloud Management Framework: Problems, Solutions & KPIs}
:::
Common QoS Problems in Hybrid Cloud Environments
Network Performance Varies Between Environments
Hybrid cloud environments often face inconsistent performance as traffic moves between on-premises systems, private clouds, and public cloud platforms. This variability stems from factors like latency and jitter, especially when data traverses unmanaged public internet nodes or controlled private links. For example, private connections like AWS Direct Connect or Google Cloud Interconnect offer fewer, predictable hops, while standard Site-to-Site VPNs are capped at around 1.25 Gbps per tunnel [3]. The physical distance between a data centre and a cloud provider's on-ramp
significantly affects latency [3]. Additionally, VPN encryption adds overhead, further reducing throughput [4].
Issues like buffer bloat can drastically impact performance. For instance, a transition from a 10 Gbps to a 1 Gbps link might reduce throughput to under 200 Mbps [1]. Similarly, uneven BGP path costs across multiple connections can force traffic onto inefficient routes, disrupting load balancing [3]. Beyond these inherent challenges, limited data collection makes it even harder to maintain consistent quality of service (QoS).
Limited Data Collection and Visibility
A lack of comprehensive data collection creates blind spots in hybrid networks, making it difficult to diagnose and resolve performance issues. These environments often leave network teams without the full visibility needed to monitor and maintain consistent performance across on-premises systems, private clouds, and public clouds [5]. Without shared data, identifying the root cause of performance degradation becomes a daunting task [6].
The problem isn’t just about missing data - it’s also about the loss of context. For example, a monitoring system might highlight unusual CPU activity but fail to explain its business impact or underlying causes [7]. Limited visibility also makes it challenging to map application-to-network flows, leaving teams unable to understand service dependencies or how network delays affect specific applications [6]. Relaying telemetry data between environments can add latency, reducing its usefulness for real-time alerts and QoS management [7]. As these gaps widen, the complexities of dynamic scaling further complicate maintaining QoS.
Scaling and Dynamic Resource Allocation Issues
Resource allocation in hybrid environments can become a bottleneck, especially during high-traffic periods. For instance, combining ports with and without bandwidth guarantees on the same physical interface can lead to resource starvation for non-guaranteed ports [8]. In Red Hat OpenStack environments, QoS policies for guaranteed bandwidth cannot be adjusted while the associated ports are in use, limiting the flexibility of dynamic scaling [8].
As workloads grow, existing hybrid connections can quickly become over-subscribed. AWS Transit Gateway, for example, can scale VPN bandwidth to 2.5 Gbps per attachment using two tunnels and BGP ECMP load balancing. Similarly, Direct Connect Link Aggregation Groups allow up to four 10 Gbps connections to be combined [3]. However, if BGP path costs or AS PATH lengths differ across connections, ECMP may fail, resulting in uneven traffic distribution and degraded QoS [3]. During failovers, the situation can worsen if backup connections lack the same performance metrics as primary links, leading to immediate bottlenecks for scaled workloads [3].
How to Ensure QoS in Hybrid Cloud Traffic Management
Unified Monitoring and Centralised Visibility
Creating a single pane of glass is a game-changer for managing QoS in hybrid environments. By unifying logs and performance data from on-premises, private, and public clouds into one dashboard, teams can easily pinpoint the root causes of QoS issues across their entire setup [13]. This centralised approach allows for seamless correlation of database metrics with application performance and logs [11].
For example, an enterprise cloud operations team reported saving at least £400,000 annually by cutting response times from 4–5 minutes to under 2 minutes, thanks to unified monitoring [11]. Similarly, a utility company reduced issue resolution times by 20–40% after consolidating their monitoring tools into a single platform [11]. Tools like Datadog's Network Path further enhance visibility by mapping latency and packet loss hop-by-hop, making it easier to determine whether the problem lies in application code or the network backbone [6].
SolarWinds gives the power over the infrastructure back to the business. We can always see what's going on and where we need to invest or observe more closely.
- Monitoring Consultant, Enterprise IT Services Company [11]
To get the most out of your monitoring tools, use contextual tagging. By tagging resources with metadata like region, service name, or owner, teams can group and filter data more effectively [12]. Also, consider global synthetic monitoring to simulate user traffic and detect packet loss before it impacts operations [14]. Once real-time monitoring is set up, the focus can shift towards optimising traffic prioritisation and routing.
Traffic Prioritisation and Routing Methods
Marking and classifying traffic at the network edge with DSCP or CoS identifiers ensures that QoS priorities are maintained across multiple hops [1][2]. Different applications benefit from specific strategies: Low Latency Queuing (LLQ) is ideal for minimising delay and jitter in voice or real-time video, while Class-Based Weighted Fair Queuing (CBWFQ) ensures minimum bandwidth for bulk data transfers like FTP [2].
SD-WAN integration takes traffic management to the next level by dynamically managing traffic across various links - MPLS, Internet, or LTE - while continuously measuring latency and packet loss [1]. For organisations needing even more reliability, private connections through on-ramp providers or Internet Exchange Points (IXPs) can bypass the variability of public internet routes [1].
Bandwidth management rules also play a critical role. By guaranteeing minimum bandwidth for essential ports and capping traffic rates to prevent congestion, critical applications get the resources they need [9][10]. However, avoid using Weighted Random Early Detection (WRED) or traffic shaping for voice and real-time video, as these applications are particularly sensitive to latency [2]. WRED is better suited for TCP-based applications like HTTP, where it can trigger the TCP slow-start algorithm to manage congestion more gracefully [2].
These routing strategies lay the groundwork for even more advanced techniques, including AI-driven QoS management.
Using AI and Machine Learning for QoS
Once unified monitoring and effective traffic management are in place, incorporating AI takes QoS to a new level.
AI shifts the paradigm from reactive monitoring to proactive QoS management by identifying performance anomalies in real time [11]. With AIOps, IT teams can focus on critical issues by eliminating non-essential alerts [11]. For instance, a large enterprise reduced IT incidents by 40% after adopting SolarWinds Observability [11].
Machine learning adds another layer by analysing both historical and real-time data to predict potential network issues before they impact users [11]. These algorithms also automate identity and policy management, ensuring secure and prioritised access for users while speeding up verification processes [16]. By correlating application and network performance data, AI tools can quickly identify the root causes of performance degradation in complex hybrid environments [6].
Proactive synthetic monitoring, powered by AI, tests critical application features and network paths to identify potential failures or latency problems before they affect live traffic [15]. This capability becomes increasingly important as organisations scale. By 2025, it’s estimated that 95% of digital workloads will run on cloud-native platforms, and 60% of enterprises are already using cloud-based tools to manage their network infrastructure [16].
Hokstad Consulting is one example of how businesses are leveraging AI for QoS. They provide AI-driven strategies and agents within DevOps environments, helping organisations cut cloud costs by 30–50% while improving deployment cycles and automating QoS management.
Measuring and Improving QoS Performance
Key Performance Indicators for QoS
To evaluate the effectiveness of Quality of Service (QoS), focus on five key metrics: latency, throughput, packet loss, uptime, and error rate [17]. For services like VoIP and video conferencing, the Mean Opinion Score (MOS) is often used to measure user-perceived quality on a numerical scale [20].
Operational metrics such as Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR) are equally critical, as they reflect how quickly issues are identified and resolved [22][23]. For instance, Pine Labs reported a 15–20% reduction in MTTD and MTTR in 2025, with potential improvements of up to 40–50% by integrating unified monitoring systems [23].
Because Differentiated Services Code Point (DSCP) tags can sometimes be lost when data traverses the public internet, it’s essential to pair network-level monitoring with application-level tools like eBPF or OpenTelemetry [19]. To maintain balanced traffic, it’s recommended to limit real-time priority queues to 33% of bandwidth and cap total prioritised traffic at 75%, ensuring sufficient Layer 2 overhead [18].
These KPIs and strategies provide a solid foundation for maintaining and improving QoS.
Continuous Improvement and Feedback Loops
Once KPIs are established, a system of continuous improvement is vital for maintaining high QoS standards. Unified monitoring data plays a key role here, feeding into feedback loops that allow for quick adjustments and optimisation. Before deploying new cloud services, it’s essential to establish a network baseline to rule out pre-existing congestion as a cause of poor performance [18][21].
AI-powered feedback loops add another layer of refinement by retraining anomaly detection models to minimise false positives and negatives [23]. Combining real-world and synthetic monitoring allows teams to anticipate potential issues before they arise [22]. Automated alert escalation systems - such as notifying Tier 1 support within five minutes and escalating to Tier 2 after 15 minutes - help ensure critical QoS breaches are addressed without delay [23]. Regular reviews, such as quarterly KPI assessments and monthly AI model updates, keep your network agile and responsive to evolving demands [23].
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Conclusion
Key Takeaways
Maintaining consistent Quality of Service (QoS) in hybrid cloud environments requires a combination of unified observability, intelligent traffic management, and automation. Together, these elements minimise disruptions and improve performance. SD-WAN plays a critical role here, offering dynamic routing and straightforward QoS classes - ideally limited to four - to ensure uniform traffic handling across different environments when traffic is marked near its source [1][2].
A holistic hybrid cloud network observability architecture... transforms monitoring into true observability for hybrid networks, enabling faster troubleshooting.
- Ripin Checker, Senior Product Solutions Architect at Datadog [6]
Regularly refining your network through feedback loops, KPI reviews, and AI model updates keeps it agile and responsive to changing demands. This proactive approach helps prevent costly outages and ensures optimal performance.
How Hokstad Consulting Can Help

Turning these strategies into actionable results often requires expert guidance - and that’s where Hokstad Consulting comes in. They specialise in DevOps transformation and cloud optimisation, offering services like:
- Strategic cloud migration to streamline your move to hybrid environments.
- Cost engineering, which can cut expenses by 30–50%.
- AI-driven monitoring solutions to maintain high QoS across complex deployments.
Hokstad’s tailored CI/CD automation, combined with integrated monitoring, tackles challenges such as unified observability, predictive analytics, and automated root cause analysis - ensuring robust QoS management.
Whether you’re looking for ongoing support through a retainer, project-specific consulting for cloud migration, or their No Savings, No Fee
cost optimisation service, Hokstad Consulting delivers solutions suited to your needs. Visit hokstadconsulting.com to explore how they can optimise your hybrid cloud infrastructure.
Cato Demo: Bi-directional QoS, advanced bandwidth management, and real-time application analytics

FAQs
How does AI enhance Quality of Service (QoS) in hybrid cloud environments?
AI plays a crucial role in enhancing Quality of Service (QoS) within hybrid cloud environments by efficiently managing network resources and traffic. By leveraging machine learning (ML) and deep learning (DL), AI processes massive data sets in real time, fine-tuning critical elements such as latency, throughput, and resource distribution. This ensures that essential applications get the attention they need while keeping disruptions to a minimum and maintaining steady service reliability.
Another key advantage of AI is its ability to deliver proactive monitoring and predictive analytics. It can spot potential bottlenecks or system failures before they affect users. With automated adjustments and self-healing capabilities, AI helps to minimise downtime and optimise resource use. In hybrid cloud systems, where traffic and performance demands can shift dramatically, AI’s capacity to adapt on the fly is indispensable for ensuring dependable, high-quality service delivery.
What are the main challenges in ensuring Quality of Service (QoS) in hybrid cloud environments?
Managing Quality of Service (QoS) in hybrid cloud environments comes with its fair share of challenges. One of the biggest hurdles is ensuring consistent QoS across both on-premises and cloud networks, which often operate on entirely different infrastructures and control systems. These differences can lead to inconsistencies in network performance, with issues like latency and bandwidth fluctuations potentially disrupting the reliability of real-time traffic.
Another critical aspect is prioritising real-time, high-priority data over less urgent traffic. This demands advanced traffic management strategies capable of adapting to the varied capabilities of hybrid cloud setups. To tackle this, organisations need sophisticated tools and clearly defined policies to monitor and fine-tune traffic flow. These measures are crucial for ensuring that key applications remain reliable, even amidst the complexities of hybrid cloud architectures.
How does unified monitoring improve network performance in hybrid cloud environments?
Unified monitoring enhances network performance in hybrid cloud environments by providing a single, centralised perspective of your entire infrastructure. This includes both on-premises systems and various cloud platforms. With this comprehensive visibility, IT teams can swiftly pinpoint and resolve issues, reducing downtime and avoiding potential bottlenecks. By bringing together logs, metrics, and traces into one dashboard, organisations can keep a close eye on traffic patterns, system health, and possible security risks in real time.
Additionally, this method supports proactive planning by leveraging predictive analytics to foresee and address issues before they grow into significant problems. In the ever-changing landscape of hybrid cloud setups, unified monitoring plays a key role in maintaining consistent Quality of Service (QoS). It achieves this by fine-tuning resource allocation and catching anomalies early. The outcome? Greater reliability, stronger security, and a smooth, uninterrupted user experience across all systems.