
If your business handles card payments, PCI DSS compliance is critical. This standard ensures secure handling of cardholder data and applies to both production and disaster recovery (DR) environments. From June 2024, only PCI DSS v4.0.1 will remain valid, and non-compliance can lead to fines of £4,000–£80,000 per month or up to £72 per compromised cardholder. For UK and EU businesses, breaches may also violate GDPR, resulting in additional penalties of up to €20 million or 4% of annual turnover.
Key points to know:
- DR sites fall under PCI DSS scope immediately during activation. Even standby sites with live cardholder data must meet compliance at all times.
- Critical PCI DSS requirements for DR include secure offsite backups (Requirement 9.5.1), incident response plans (Requirement 12.10.1), and robust logging/monitoring (Requirement 10).
- Challenges: Maintaining encryption, monitoring distributed systems, and synchronising configurations across DR sites.
- Solutions: PCI-compliant cloud platforms, centralised encryption management, and tailored DR strategies (e.g., active-active, warm standby).
Failing to meet these standards can result in severe financial and reputational damage. Regular testing, training, and expert support are essential to ensure compliance.
::: @figure 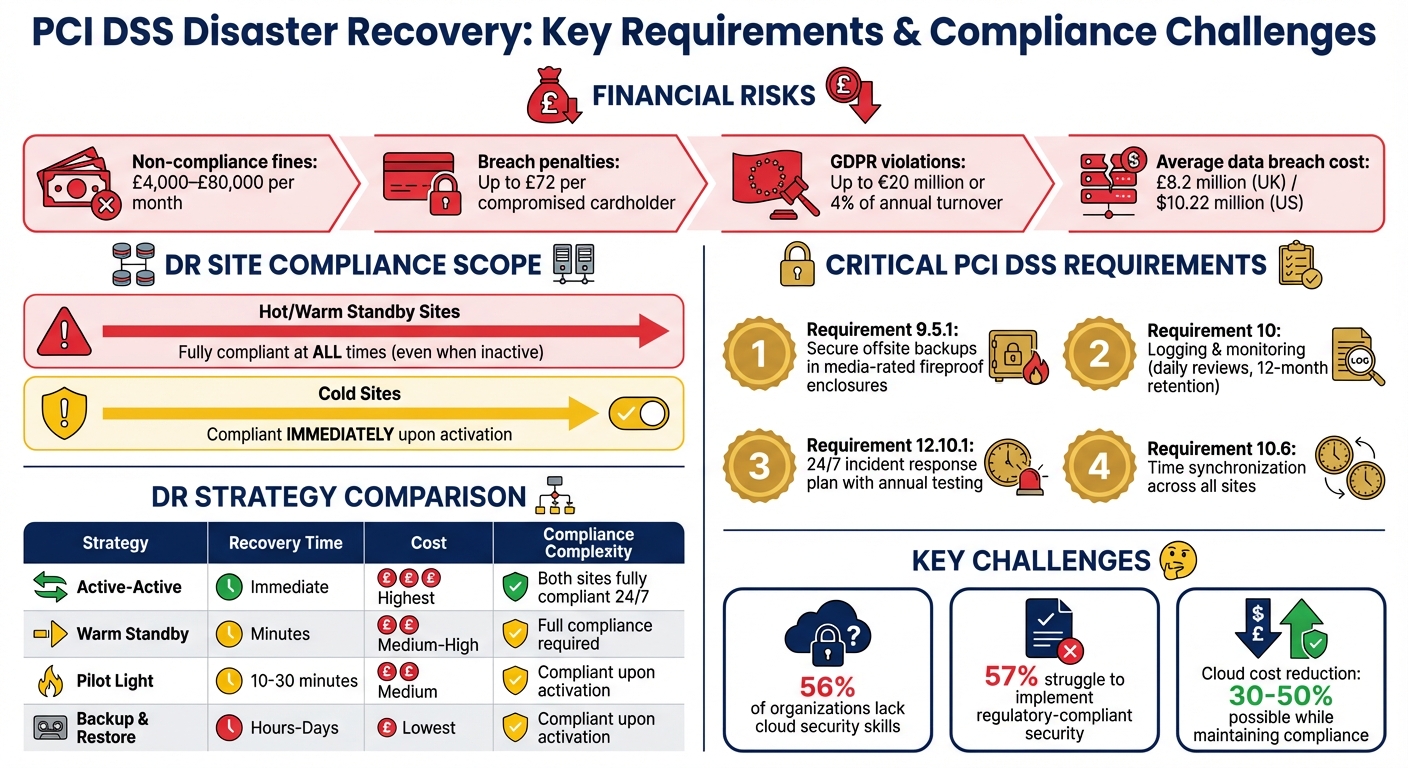 {PCI DSS Disaster Recovery Requirements and Compliance Challenges}
:::
{PCI DSS Disaster Recovery Requirements and Compliance Challenges}
:::
Your Journey Through the Key New PCI DSS v4.x Requirements - Get Started Now!
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
PCI DSS Requirements That Affect Disaster Recovery
When creating disaster recovery plans, managed hosting providers must align with specific PCI DSS requirements to ensure compliance.
Data Storage and Backup Security
Requirement 9.5.1 specifies that all media backups containing cardholder data must be stored securely in an offsite facility. Providers are required to review the security measures of this facility at least once a year. This poses a challenge for physical media since standard fireproof safes are usually designed to protect paper, which has a higher melting point than magnetic media. If you're using tapes or disks, be sure to store them in media-rated fireproof enclosures that are specifically built to safeguard magnetic storage.
It's crucial to encrypt backups both during storage and transit. Additionally, backups should be kept on a separate network with unique credentials to minimise the risk of ransomware spreading.
Requirement 12.10.7 addresses situations where Primary Account Number (PAN) data might appear in unexpected places, such as within backup files. Procedures must be in place to secure any unexpected PAN data immediately upon discovery.
Once data security is ensured, the focus moves to quick incident response and recovery.
Incident Response and Recovery Planning (Requirement 12.10.1)
Requirement 12.10.1 requires organisations to have a documented Incident Response Plan (IRP) that includes business recovery procedures and detailed backup processes. The plan must also identify specific personnel who are available 24/7 to respond to security alerts and initiate recovery (Requirement 12.10.3). This isn't a document you can file away and forget about. As John Rundell from Stratica points out:
Your incident response plan isn't a 'set and forget' document. It needs to be tested and updated at least annually [6].
Requirements 12.10.2 and 12.10.4 further emphasise the importance of annual testing and role-specific training. Conduct tabletop exercises with key teams to simulate real-world failures. Generic training sessions won't cut it - staff need focused instruction on the tools and procedures they'll rely on during an actual recovery.
PCI DSS v4.0 introduces additional clarity. Roberto Davila from Schellman explains:
In v4.0, the PCI SSC has clarified that organisations must respond immediately to not only confirmed security incidents but also suspected events [5].
This means your plan must be ready to address even suspected incidents without delay.
Logging and Monitoring (Requirement 10)
Effective logging and monitoring are essential to maintain compliance during recovery operations.
Requirement 10 covers all logging and monitoring activities, which remain critical during disaster recovery. Every access to cardholder data at the recovery site must be logged, capturing details like user ID, date and time, success or failure status, event type, source, and affected component (Requirement 10.3).
Requirement 10.1 ensures that all access to system components, especially administrative or root access, is linked to individual users. This creates a clear audit trail during failover events. Logs should be reviewed daily, with audit histories retained for 12 months. The most recent three months must remain immediately accessible.
Requirement 10.6 focuses on time synchronisation. Both production and disaster recovery sites need consistent time settings, typically achieved through technology like NTP. Without synchronised time, reconstructing event sequences for forensic investigations becomes difficult, which can hinder compliance efforts.
| Requirement | Focus Area | DR Importance |
|---|---|---|
| 10.1 | User Identification | Ensures admin actions during recovery are traceable to specific individuals |
| 10.4 | Daily Log Review | Detects potential attacks during disaster events |
| 10.6 | Time Sync | Essential for accurate forensic analysis across sites |
| 10.7 | Control Failures | Alerts admins to security tool malfunctions during failovers |
A Security Information and Event Management (SIEM) solution can simplify compliance by aggregating logs from both production and recovery sites, offering a centralised view for daily reviews. Automated log collection tools are especially important, as manually reviewing logs across distributed environments is often impractical.
Challenges PCI DSS Creates for Managed Hosting Disaster Recovery
Meeting PCI DSS requirements in disaster recovery environments presents managed hosting providers with a range of obstacles. These challenges play a key role in shaping compliant disaster recovery strategies.
Maintaining Security Standards Across Recovery Sites
The scope of PCI DSS compliance grows significantly depending on the type of recovery site you use. For example, hot
and warm
standby sites - which store live copies of Cardholder Data Environment (CDE) systems, data, or keys - are fully subject to PCI DSS requirements, even when they aren’t actively processing transactions [2]. This means that these sites must maintain the same level of physical security, including biometric scanners and access controls, as the primary site. And this isn’t just during failover - these standards must be upheld at all times.
On the other hand, cold
sites are initially outside the scope of PCI DSS. However, as soon as they become active, they must comply with all relevant requirements [2][1].
The financial risks of non-compliance are steep. Card brands may impose fines ranging from £3,900 to £78,000 per month, with penalties for breaches reaching up to £70 for every compromised cardholder [4]. In the United States, the average cost of a data breach hit $10.22 million in 2025 [4]. These issues also extend to areas like encryption synchronisation and monitoring.
Synchronising Configurations and Encryption Keys
Keeping encryption consistent across geographically separated sites is a technical challenge. Managed hosting providers need to ensure that end-to-end encryption - both at rest and in transit - is uniformly applied between primary and recovery environments. This involves securely managing and synchronising Data Encryption Keys (DEK) and Key-Encryption Keys (KEK) [8][1].
In cloud-based disaster recovery setups, this task becomes even trickier. Mohammed Khalil explains:
The CDE is no longer just a network segment; it's a collection of resources defined by IAM roles and metadata tags. A failure to properly manage IAM and tagging is a failure to manage your CDE boundary [4].
With traditional network boundaries becoming less relevant in distributed environments, Identity and Access Management (IAM) policies and metadata tags now define the CDE boundary. Misconfigurations here can lead to compliance failures. Additionally, any disaster recovery site testing involving cardholder data must meet PCI DSS security requirements, just as production environments do [2]. Without standardised encryption and configurations, monitoring these systems becomes even harder.
Monitoring Distributed Environments
Recovery systems spread across multiple locations add another layer of complexity when it comes to compliance. Meeting PCI DSS Requirement 10, which involves collecting, correlating, and archiving logs, becomes challenging in geographically dispersed setups [9]. Virtual components in these environments often lack the robust logging, access control, and monitoring features available in physical systems [9].
Cloud service providers add to the difficulty, as organisations often have limited visibility into their underlying infrastructure. This makes it hard to verify who has access to cardholder data in cloud-based disaster recovery environments [9][10]. The shifting boundaries of cloud perimeters further complicate intrusion detection and monitoring. Running data-discovery tools in these distributed systems can produce incomplete results, making it difficult to confirm that cardholder data hasn’t ended up in unmonitored areas of the recovery site [9].
| Monitoring Requirement | Challenge in Distributed DR | Solution Mechanism |
|---|---|---|
| Requirement 10 (Logging) | Correlating logs from multiple sites | Centralised SIEM with tamper-resistant storage [11] |
| Requirement 11.5 (FIM) | Maintaining visibility across virtual/cloud layers | Deploying FIM agents compatible with cloud-native events [10] |
| Requirement 12.10.1 (IR) | 24/7 alert response across different regions | Dedicated 24/7 incident response teams and automated alerts [1] |
| Requirement 11.4.5 (Segmentation) | Managing fluid perimeters in cloud environments | Semi-annual segmentation testing and isolation [11] |
Solutions for PCI-Compliant Disaster Recovery in Managed Hosting
To tackle the challenges previously discussed, there are several practical disaster recovery solutions that align with PCI DSS standards. Managed hosting providers can implement these strategies to address both technical and operational hurdles, such as encryption synchronisation and monitoring across distributed systems.
Using PCI-Compliant Cloud Infrastructure
PCI-compliant cloud platforms come with built-in physical security measures, like restricted data centre access and environmental monitoring, which align with Requirement 9 of PCI DSS [4]. This setup operates under a shared responsibility model: the cloud provider secures the infrastructure (security of the cloud
), while you handle data, configurations, and applications (security in the cloud
) [4].
These platforms often include tools for automated replication and failover. For instance, Azure Site Recovery can achieve recovery point objectives (RPOs) as low as 30 seconds, significantly reducing recovery times to just a few hours [15][1]. Additionally, features like Virtual Private Clouds (VPCs) or Virtual Networks (VNets) enable network segmentation, isolating the Cardholder Data Environment and minimising the systems subject to audits [4].
When choosing cloud infrastructure, it's essential to understand how service models affect compliance responsibilities. With Infrastructure as a Service (IaaS), you manage the operating system, applications, data, identity and access management (IAM), and network security. Platform as a Service (PaaS) shifts OS patching to the provider, while Software as a Service (SaaS) limits your scope to data and user access management [4].
Managed Hosting Features and Advisory Services
Managed hosting providers play a critical role in maintaining compliance across both primary and recovery sites. Key features include advanced monitoring systems, access controls, and expert advisory services. Specific compliance measures include dual control, segregation of duties, and detailed audit trails for customer information systems [12].
Centralised encryption and key management solutions, such as Azure Key Vault or Google Cloud KMS, are essential for secure key retrieval. These services often use managed identities to streamline secure access [13][14]. For organisations needing higher compliance levels, HSM-backed vaults (meeting FIPS 140-2 Level 3 standards) provide additional protection against unauthorised key exposure [13].
The disaster recovery pattern you choose also impacts compliance and costs. Here are some common configurations:
- Active-Active: Offers immediate recovery but requires both sites to meet PCI DSS standards continuously, making it the most expensive option.
- Warm Standby: Balances cost and recovery speed, enabling recovery within minutes.
- Pilot Light: A more cost-effective option, with recovery times between 10–30 minutes.
- Backup & Restore: The least expensive approach but with recovery times ranging from hours to days [12].
Choosing the right pattern involves weighing compliance requirements against business continuity needs and budget constraints.
How Hokstad Consulting Supports PCI DSS Compliance

Specialist support can make implementing these technical solutions more manageable and tailored to your organisation's needs.
Hokstad Consulting offers expert services to navigate PCI-compliant disaster recovery. Their expertise in DevOps transformation and cloud infrastructure optimisation ensures that both primary and recovery environments meet PCI DSS standards without downtime during cloud migrations.
Their cloud cost engineering strategies help organisations reduce cloud expenses by 30–50% while maintaining PCI DSS compliance. This is particularly crucial as the standard becomes mandatory for all organisations by 31 March 2025 [4]. Hokstad achieves this through automated CI/CD pipelines, robust monitoring, and continuous security audits.
For businesses using managed hosting or hybrid setups, Hokstad Consulting provides custom development and automation services. These ensure encryption keys, configurations, and monitoring systems remain synchronised across geographically dispersed sites. With experience in both public and private cloud environments, they design solutions tailored to the unique challenges of maintaining PCI DSS compliance in distributed disaster recovery systems.
Best Practices for Maintaining PCI DSS Compliance in Disaster Recovery
Annual Testing and Documentation
PCI DSS Requirement 12.10.1 highlights the importance of annual testing for disaster recovery and incident response plans. This involves activities like desktop exercises, training sessions, and simulated activations [1][3].
PCI DSS requirement 12.10.1 requires you to establish an incident response plan to be implemented in the event of a breach and to ensure that the programme addresses... business recovery and continuity procedures.- Surkay Baykara, Senior Information Security Consultant [3]
Start with a Business Impact Analysis to pinpoint critical functions and ensure that key personnel are available around the clock. Keep documentation updated and ready for review by a Qualified Security Assessor [16][3]. After each test, take the opportunity to refine your recovery plan based on lessons learned and any recent industry changes [1][3]. Regular testing not only strengthens your recovery protocols but also ensures your team is well-prepared to handle crises effectively.
Logging and Audit Trails
Requirement 10 of PCI DSS emphasises that all system access - especially administrative or root access - must be tied to individual users. This ensures clear accountability during both routine operations and recovery efforts [7].
Requirement 10 stipulates that a merchant must 'establish a process for linking all access to system components (especially access done with administrative privileges such as root) to each individual user.'- Atlantic.Net [7]
Implementing a Security Information and Event Management (SIEM) solution can centralise log management across both primary and disaster recovery environments. This approach provides visibility into user activities, raises alerts for suspicious behaviour, and records every instance of encryption key usage or data retrieval during recovery [7][1]. To stay compliant, system logs must be reviewed daily to catch anomalies early [7]. Beyond technology, training your team to interpret logs and respond appropriately is essential for maintaining compliance during incidents.
Training and Preparedness
Effective disaster recovery goes beyond testing and logging - it requires a well-trained team that understands its role in maintaining PCI DSS compliance. The standard mandates that staff responsible for responding to security breaches receive tailored training [1].
Provide appropriate training to personnel with security breach response responsibilities.- Surkay Baykara, Senior Information Security Consultant [1]
The financial risks of non-compliance are steep, with fines ranging from £4,000 to £80,000 per month, depending on the size of the organisation and the severity of the breach [17]. For major data breaches, the UK Information Commissioner's Office (ICO) can impose penalties of up to £17.5 million or 4% of global annual turnover [17].
Training should equip staff to handle alerts from systems like Intrusion Detection Systems (IDS), Intrusion Prevention Systems (IPS), and File Integrity Monitoring (FIM) tools [1]. It’s crucial for teams to recognise that when production shifts to a disaster recovery site, that site immediately falls under PCI DSS requirements [1]. Additionally, cross-training is key to addressing potential gaps caused by the loss of critical personnel, ensuring no single point of failure disrupts recovery efforts [3].
Conclusion
PCI DSS compliance brings a new perspective to disaster recovery in managed hosting. The standard treats production and recovery environments equally - if production shifts to a disaster recovery site, that site must meet compliance requirements immediately [1]. This means encryption, logging, access controls, and monitoring must be fully functional the moment a failover occurs.
With the average cost of a data breach now reaching around £8.2 million [4], the stakes couldn't be higher.
Security continuity and business continuity depend on each other. In a bad scenario, you should add features to the plan... that protect your customer data.– Surkay Baykara, Senior Information Security Consultant [3]
As discussed earlier, addressing these challenges requires tailored strategies and expert intervention. Around 56% of organisations report difficulties in securing the necessary skills to safeguard cloud infrastructure, while 57% struggle to implement security measures that meet regulatory standards [18]. Specialists can help by defining the scope of disaster recovery sites, applying scope reduction techniques like tokenisation, and building cloud-native architectures that maintain compliance while cutting costs by as much as 50% [1][4].
FAQs
Does my DR site need PCI DSS compliance even when it’s not in use?
If a disaster recovery (DR) site is not actively processing, storing, or transmitting cardholder data, it does not need to meet PCI DSS compliance requirements. However, the moment a recovery site begins handling such data, it must adhere fully to PCI DSS standards.
How do I keep encryption keys and configs consistent across DR sites?
To keep encryption keys and configurations consistent across disaster recovery (DR) sites, it's crucial to stick to solid key management practices that comply with PCI DSS. This involves encrypting data both in transit and at rest, securely handling keys (including their generation, rotation, and destruction), and leveraging tools like Hardware Security Modules (HSMs). Techniques such as split knowledge and dual control play a key role in maintaining synchronisation, safeguarding keys, and managing their lifecycle effectively across all DR sites.
What evidence will a QSA expect from DR testing and logging?
A Qualified Security Assessor (QSA) will need to see documented proof that disaster recovery (DR) testing is conducted regularly. This means providing logs that outline the testing procedures, the results, and any follow-up actions taken to address issues. Having thorough documentation not only helps meet PCI DSS requirements but also shows that your disaster recovery processes are both effective and consistently evaluated.