
In 2025, GPU pricing varied significantly across providers and regions, with hourly rates for the same GPU differing by up to 10x. For instance, an NVIDIA H100 cost as little as £1.10/hour on Thunder Compute but exceeded £11.50/hour on Google Cloud. These price differences stemmed from factors like energy costs, taxes, and regional demand.
Key highlights include:
- AWS: H100 prices dropped to £3.93/hour after a 44% price cut. Spot instances offered discounts up to 90%, but regional premiums added 5–40%.
- Azure: H100 rates ranged from £5.48 to £9.65/hour, with a 25% surcharge for Azure ML users. Spot VMs reduced costs by 60–80%.
- Google Cloud: H100 prices were £3.79–£4.10/hour on-demand, dropping to £1.23–£1.52 with Spot pricing. Regional costs varied by 10–50%.
Quick Comparison
| Provider | H100 On-Demand (£/hour) | Spot Discount (%) | Regional Premiums (%) | Data Egress (£/GB) |
|---|---|---|---|---|
| AWS | £3.93 | 70–90 | 5–40 | £0.07–£0.12 |
| Azure | £5.48–£9.65 | 60–80 | 20–40 | £0.07–£0.11 |
| Google Cloud | £3.79–£4.10 | 60–91 | 10–50 | £0.08–£0.12 |
For cost savings, use spot instances, co-locate compute and storage, and consider less expensive GPUs like the A100 or L4 for suitable workloads. This approach can cut GPU costs by 2–5x.
::: @figure 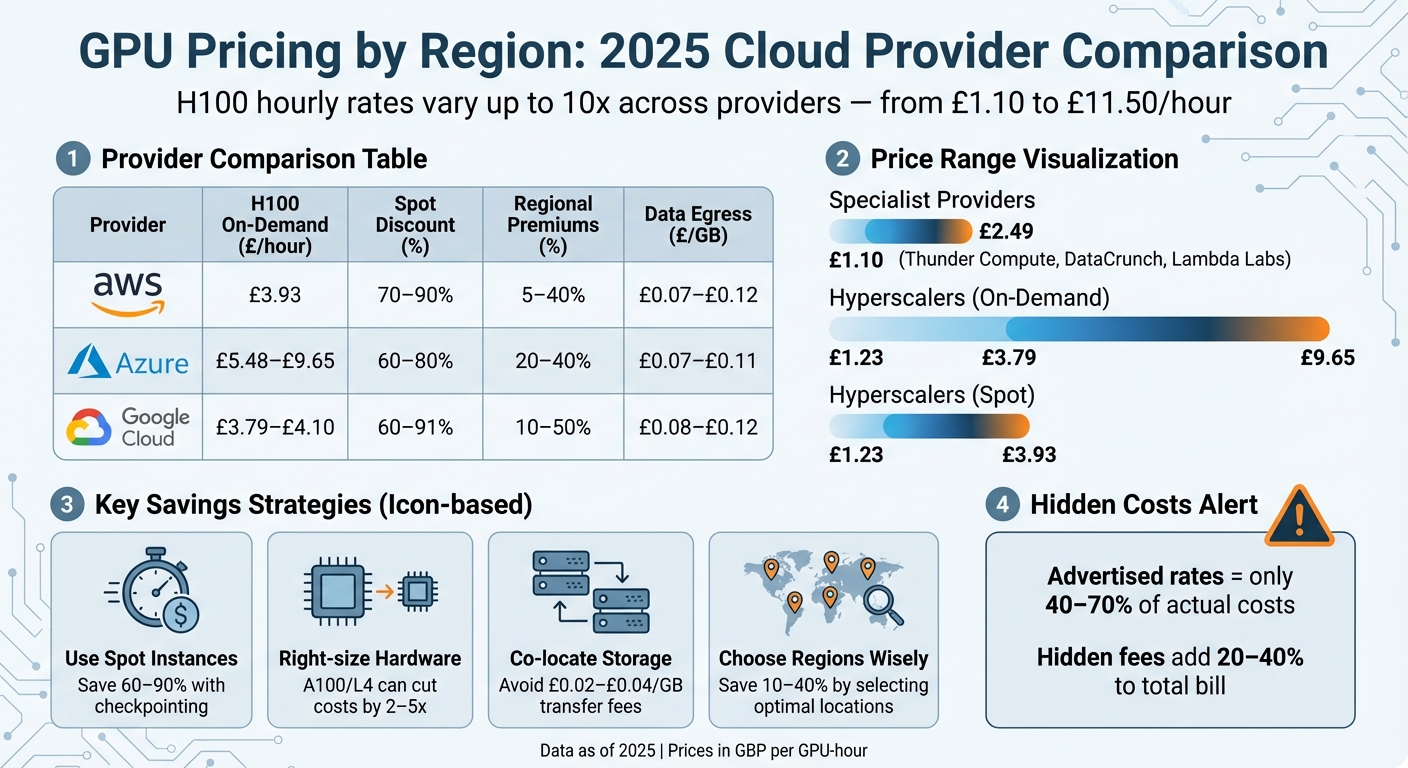 {2025 GPU Pricing Comparison: AWS vs Azure vs Google Cloud H100 Costs}
:::
{2025 GPU Pricing Comparison: AWS vs Azure vs Google Cloud H100 Costs}
:::
1. AWS GPU Pricing
This section examines AWS's GPU pricing, offering a key reference point in the broader 2025 market landscape.
Hourly Rates
On 1 June 2025, AWS introduced significant price reductions: 45% off P5 (H100), 26% off P5en (H200), and 33% off P4d/P4de (A100) on-demand pricing [7]. After these cuts, the P5 instance (8× NVIDIA H100) is now priced at £31.46 per hour (around £3.93 per GPU-hour), down from £55.04 [1][4]. The newer P5en instance (8× NVIDIA H200) costs £74.69 per hour, while the recently launched P6-B200 (8× NVIDIA B200) is priced at £113.93 per hour [2][6]. For older models, the P4d instance (8× NVIDIA A100) is available at £21.95 per hour, equating to about £2.74 per GPU-hour. For inference tasks, the G5.xlarge (single NVIDIA A10G) costs £1.24 per hour, and the G6.xlarge (single NVIDIA L4) comes in at £0.98 per hour [2][6]. These adjustments highlight AWS's competitive positioning and underline regional pricing variations.
Regional Price Variations
AWS pricing varies by region, with US East (N. Virginia) serving as the baseline. Other regions incur additional costs due to infrastructure expenses and demand [5]. For instance:
- US West (Oregon): Typically 5–10% higher.
- Europe (Ireland): Adds 15–20%.
- Asia Pacific regions: Can be 20–40% more expensive than US East.
For workloads where latency isn't a concern, such as batch training, choosing US East can lead to savings of 10–40% compared to European or Asian regions [5][4].
Cost-Per-Performance
While hourly pricing and regional differences are important, performance also plays a major role in cost efficiency. H100 instances deliver three times the training throughput of A100s for most transformer workloads, levelling out costs per token trained [10]. The H100's standout feature is its speed: training runs that would take 72 hours on an A100 can be completed in just 24 hours [10]. Additionally, spot instances offer steep discounts - up to 70–90% off on-demand rates. For teams with robust checkpointing strategies, this can bring H100 costs down to as low as £2.50 per GPU-hour [4][5].
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
2. Azure GPU Pricing
Let’s dive into Azure's GPU pricing to understand its costs, regional differences, and performance. Azure's rates are comparable to AWS, though they tend to be slightly higher than other providers [11]. Here’s a closer look at the hourly rates, regional pricing adjustments, and how performance ties into the overall cost.
Hourly Rates
Azure provides a variety of GPU instance families tailored to different workloads. Here’s a breakdown of the hourly costs:
- H100 Instances: The Standard_ND96isr_H100_v5 (H100 SXM) is priced at £9.65 per GPU-hour, while the NC40ads H100 v5 costs £5.48 per GPU-hour [11].
- A100 Instances: The Standard_NC24ads_A100_v4 (80GB) is £2.88 per GPU-hour, with the 40GB version slightly lower at £2.67 [11].
- Older Models: The V100 comes in at £2.40 per GPU-hour, the T4 at £0.41, and the A10 at just £0.36 per GPU-hour [11].
However, if you're using Azure Machine Learning, expect a 25% surcharge on top of the raw VM rates. For instance, an 8× A100 cluster rises from £25.07 to £31.34 per hour due to this additional cost [10].
For cost-saving options, Azure offers Spot VMs, which can slash prices by 60–80% but come with the risk of short eviction notices. Alternatively, committing to a Reserved VM Instance for three years can reduce costs by up to 63% [8].
Regional Price Variations
Azure's pricing fluctuates significantly depending on the region. Factors like infrastructure expenses, demand, and data centre availability all play a role. On top of this, ancillary fees can add 20–40% to the advertised rates [9]. For example, transferring data from South America costs around £0.16 per GB [2], which can quickly add up for large-scale training tasks.
Cost-Per-Performance
When it comes to performance, Azure justifies its pricing through efficiency. H100 instances offer three times the throughput of A100 instances, which significantly improves the cost per token trained [10]. These H100 GPUs also train 2.4× faster than A100s and up to 9× faster in clusters equipped with NVLink Switch Systems [8].
For inference tasks, using quantisation techniques - like converting fp16 to int8 - can reduce memory needs by half. This allows models to run on smaller, less expensive instances while maintaining performance. To avoid unnecessary expenses, configuring auto-shutdown for Azure ML compute resources is highly recommended. Idle GPUs could otherwise rack up costs of hundreds of pounds per month [10].
3. Google Cloud GPU Pricing
Google Cloud Platform (GCP) charges for GPUs with a 1-minute minimum, followed by per-second increments. This makes it a great fit for short-burst workloads [14]. GCP offers three main pricing options: On-Demand, Spot (previously called Preemptible), and Committed Use Discounts (CUDs). Spot instances provide the biggest savings, with discounts ranging from 60% to 91% off standard rates. Meanwhile, CUDs offer approximately 37% off for 1-year commitments and 55% off for 3-year terms [12][13]. These pricing options align with earlier comparisons of AWS and Azure, showing how factors like region and usage patterns influence GPU costs. Like its competitors, GCP's pricing structure highlights the importance of tailoring costs to specific needs.
Hourly Rates
GCP's hourly GPU rates vary depending on the model and commitment level, catering to diverse workload requirements. For example:
- The H100 (80GB) costs around £3.79–£4.10 per hour on-demand, dropping to £1.23–£1.52 with Spot pricing [12][16].
- The A100 (80GB) is priced at £5.10 per hour on-demand or £1.53 on Spot. The 40GB version costs £3.67 and £1.10, respectively [12].
- For inference tasks, the L4 (24GB) is available at £0.71 per hour on-demand, or just £0.25 with Spot pricing. The older T4 (16GB) is even cheaper at £0.35 on-demand and £0.11 on Spot [12][13].
However, these rates often don't reflect the full picture. Additional charges such as data egress (£0.08–£0.12 per GB), storage (£0.02–£0.08 per GB), and management fees can increase overall costs by 20–40% [9][16]. For lengthy training jobs, GCP's CUDs often make it the more economical choice [8].
Regional Price Variations
Location plays a big role in GCP's pricing. For instance, deploying in US regions like us-central1 or us-east1 avoids the 30–50% higher costs seen in regions such as India [15]. As an example, running an H100 instance in Mumbai costs £7.50–£8.50 per hour, compared to significantly lower rates in US regions. European regions tend to add 10–20% to base costs, while Asian regions can add 15–30% [17].
But before shifting workloads to a cheaper region, consider data transfer costs. Moving large datasets between regions incurs egress fees of about £0.12 per GB, which can quickly negate any savings from lower hourly rates [9][16].
Cost-Per-Performance
GCP's A3 instances (H100) deliver up to 2.4× faster training throughput compared to A100 instances [8]. However, this performance boost doesn't always mean better value for money.
Thunder Compute observed that two hours on its H100s costs less than 25 minutes on AWS H100s and 12 minutes on GCP H100s [3].
For inference tasks, the L4 GPU stands out as the most cost-effective option. At £0.71 per hour, it can handle real-time serving without the hefty £4.10-per-hour price of an H100 [12][8]. Spot instances are particularly appealing for fault-tolerant training jobs with frequent checkpointing, potentially reducing costs by up to 91% [13]. To maximise these savings, ensure that GPU compute and data storage are in the same region to avoid high egress fees.
Pros and Cons
Cloud providers vary significantly when it comes to GPU pricing, regional availability, and additional costs. Picking the right platform means weighing factors like affordability, access to resources, and the total cost of ownership - not just the hourly rates they advertise.
Here's a breakdown of how major providers stack up in terms of cost, availability, and hidden expenses:
| Provider | Affordability | Regional Availability | Hidden Costs |
|---|---|---|---|
| AWS | Moderate: Offers discounts of 60–90% on spot instances, but on-demand rates are higher and include regional premiums [10]. | Excellent: Has the largest global footprint and GPU fleet, ensuring availability in most regions [9]. | Moderate: Egress fees are about £70 per TB, though the first 100 GB per month is free [18]. |
| Azure | Mixed: Reserved instance pricing for 1–3 years is competitive, but on-demand rates are steep (e.g., H100 costs £6.98–£12.29/hour) [8]. | Good: While strong overall, some regions may experience capacity constraints, though enterprise integration is robust [9]. | High: Complex inter-region and VNet charges add up, with egress fees of approximately £67 per TB [18]. |
| GCP | Strong: A100 pricing is highly competitive, averaging £2.53 per GPU-hour (around $3.28), about 20% cheaper than AWS [10]. | Moderate: Smaller GPU fleet compared to AWS, with limited availability in certain regions [9]. | Low: Offers a generous free egress tier of 200 GiB/month [8]. |
While advertised rates might grab attention, they only account for 40–70% of the actual costs. Hidden fees, such as data egress and storage, can add another 20–40% to the total bill [19][9]. For instance, egress fees at large cloud providers can be up to 127 times higher than those from specialised GPU cloud platforms [18].
Interestingly, on-demand pricing for H100 instances has started aligning across providers, making overall cost efficiency a key differentiator [10]. GCP, for example, shines with its a2-highgpu-8g offering for A100 workloads. SpendArk highlights this as the lowest-cost A100 option at $3.28/GPU-hour, roughly 20% cheaper than the equivalent AWS p4d
[10].
To manage costs effectively, consider these strategies:
- Use spot instances with checkpointing every 15–30 minutes to save 60–70% [10].
- Co-locate GPU compute and data storage to minimise data transfer costs.
- Right-size your hardware by opting for GPUs like the A100 or L40S instead of H100s where possible, potentially cutting costs by more than 50% [9][18].
These pros, cons, and strategies align with earlier performance and regional analyses, making them essential considerations during cloud vendor negotiations.
Conclusion
By 2025, specialist providers like DataCrunch (£1.99/hr for H100 in North Europe) and Lambda Labs (£2.49–£3.29/hr) are offering some of the lowest GPU prices, outpacing hyperscalers in affordability [2][1]. For instance, AWS's eu-north-1 (Stockholm) region saw an 88% drop in H100 spot pricing between January 2024 and September 2025, making it one of the most budget-friendly options among hyperscalers [20].
These pricing differences underscore the importance of adopting flexible strategies. The key to achieving the best cost-per-performance balance is not about sticking to one cheapest
provider but about remaining adaptable. As Laurent Gil, Co-founder of Cast AI, explains:
The winners will be those who remain agile: hopping across regions, moving between clouds and neoclouds, and letting automation carry out the repetitive tasks of selecting and provisioning the best GPU options[20].
Teams that can dynamically move workloads across regions and providers while automating GPU instance selection can achieve savings of 2× to 5× compared to average spot prices [20][21]. To start cutting costs effectively, focus on these steps:
- Right-size your hardware: Opt for A100 or L40S GPUs for inference workloads instead of more expensive H100s.
- Automate instance scheduling: This can reclaim up to 50% of wasted development spend.
- Co-locate storage and compute: Avoid cross-region transfer fees, which can range from £0.02–£0.04/GB [9][19].
- Leverage per-second billing: For bursty workloads, this can reduce costs by 15–30% compared to hourly billing [9].
For businesses looking to optimise their GPU infrastructure costs, Hokstad Consulting offers expert cloud cost engineering services. Their approach can reduce expenses by 30–50% through strategic migration, automation, and tailored optimisation. With their No Savings, No Fee
model, you only pay based on the savings they deliver - making it a no-risk solution to lower cloud costs without sacrificing performance.
In 2025, the combination of flexibility, automation, and careful vendor selection proves essential for achieving significant savings. This analysis of GPU pricing across AWS, Azure, and GCP highlights the value of strategic planning and negotiation in managing cloud infrastructure costs effectively.
FAQs
Why can the same H100 cost up to 10× more between regions and providers?
The cost of an H100 GPU can differ widely - sometimes by as much as 10 times - depending on several factors. These include regional energy prices, fluctuations in supply and demand, and the pricing structure used, such as on-demand, spot, or reserved options. Additionally, hidden fees like data transfer or storage charges can further impact the overall price, leading to considerable variations between regions and providers.
How can I estimate total GPU costs including data egress, storage, and regional premiums?
To get a clear picture of total GPU costs, you need to look beyond just the hourly GPU rate. Factor in base compute costs, data egress charges, storage fees, and regional price variations. Don’t forget to include other operational expenses like network usage or IP fees. Adding up all these elements will give you a more precise estimate tailored to your specific workload and location, making it easier to plan your budget effectively.
When should I choose H100 vs A100 or L4 to get the best cost-per-performance?
Choosing between H100, A100, and L4 comes down to your workload requirements and budget.
- H100: Best for large-scale AI training or inference where top-tier performance is essential. However, it comes at a higher cost, ranging from £1.87 to £7.50 per hour.
- A100: Offers a balance between cost and performance, making it a solid choice for training tasks. Pricing falls between £1.15 and £4.20 per hour.
- L4: Designed for inference tasks where cost efficiency is the priority, with a rate of £0.86 per hour.
Your choice should align with your performance demands and budget constraints.