
Cloud systems are complex, and failures can happen at any time. Fault injection testing helps you prepare by simulating disruptions like server crashes or network delays.
This testing method identifies weak points, tests recovery systems, and improves monitoring tools. For example, BMW uses fault injection to maintain 99.95% reliability in their vehicle systems. By creating controlled failures, you can ensure your infrastructure is ready for unexpected challenges.
Here’s how it works:
- Simulate failures: Introduce controlled issues like API throttling or service outages.
- Test recovery: Check if failovers, retries, and monitoring systems respond correctly.
- Learn and improve: Analyse results to fix vulnerabilities and refine processes.
Fault injection isn’t just about finding problems - it’s about building confidence that your systems can handle disruptions before they affect users.
AWS re:Invent 2024 - Chaos engineering: A proactive approach to system resilience (ARC326)
What is Fault Injection Testing?
Fault injection testing involves deliberately introducing faults into a system to assess how well it performs under stress [7][10]. Instead of waiting for unexpected issues to surface in production, teams simulate disruptions - like network delays, service crashes, or resource shortages - to evaluate the system's resilience.
This method follows a fault-error-failure
cycle: a fault (the root cause) introduces an error (an incorrect state), which can lead to a failure (the system behaving incorrectly) [7]. By injecting faults in a controlled environment, organisations can test whether automated recovery mechanisms - such as failovers, retries, or back-off procedures - function as intended [7][5].
Fault injection is particularly useful for testing error-handling paths that rarely activate during normal operations. It encourages teams to design systems with redundancy, ensuring quick recovery from disruptions [7]. For instance, Microsoft incorporates fault injection into its Security Development Lifecycle, requiring fuzzing at every untrusted interface to identify vulnerabilities [7]. With this groundwork, we can explore the types of failures typically simulated during fault injection.
Key Concepts in Fault Injection
Fault injection tests often simulate scenarios like network delays, resource depletion, service failures, or API throttling to push systems to their limits and verify recovery [6][4][8].
These simulations can be applied at different levels. For example, infrastructure-level tests might involve shutting down virtual machines or simulating expired certificates. Protocol-level tests, on the other hand, might use fuzzing to send invalid or unexpected data to APIs [7]. The aim is to mimic real-world conditions as closely as possible, so systems are better prepared for actual failures.
Fault Injection vs Chaos Engineering
Though often confused, fault injection and chaos engineering have distinct purposes. Fault injection is about controlled testing of specific, known failure scenarios - like verifying whether a database failover works as expected [7]. It targets particular components or situations to confirm that recovery mechanisms are effective.
Chaos engineering, in contrast, takes a broader approach. It tests entire systems under real-world stresses to uncover hidden vulnerabilities and improve resilience against unpredictable conditions [7][11]. While fault injection zeroes in on specific recovery paths, chaos engineering explores systemic weaknesses by applying generalised, real-world stresses. Used together, these methods form a comprehensive strategy for ensuring cloud systems remain robust and reliable.
How Fault Injection Improves Cloud Resilience
Fault injection is a proactive way to uncover weaknesses in cloud systems, helping businesses avoid unexpected outages. For organisations using public or hybrid cloud setups, this approach changes how teams design and maintain robust infrastructure. Let’s break down how targeted disruptions can highlight vulnerabilities like single points of failure.
Finding Single Points of Failure
Fault injection is particularly effective at identifying over-reliance on a single service or resource [12]. By intentionally disrupting critical components - such as a database, API endpoint, or even an availability zone - teams can assess the wider impact of these failures.
These tests also reveal issues like bimodal behaviour, where systems respond unpredictably under stress [12]. For example, a cache failure might redirect all traffic to a single database, creating a bottleneck that no one anticipated. Fault injection ensures isolation boundaries work as intended, so a failure in one area doesn’t snowball into a system-wide issue [12].
Testing Recovery Mechanisms
Another key benefit of fault injection is its ability to test failover systems and disaster recovery plans [5][8]. Simulating failures - like forcing a primary database to fail or triggering auto-scaling - allows teams to confirm that traffic is smoothly redirected and that recovery objectives, such as RTO (Recovery Time Objective) and RPO (Recovery Point Objective), are met [8][13][5].
This method also puts Standard Operating Procedures and automated recovery scripts to the test under real-world failure conditions [5]. Instead of assuming these systems will work when needed, organisations can repeatedly trial them to build confidence in their effectiveness. Once recovery mechanisms are validated, the focus shifts to ensuring monitoring systems can detect failures immediately.
Improving Monitoring and Observability
Fault injection also shines a light on the effectiveness of monitoring tools [5][13]. It helps verify whether systems like CloudWatch alarms and other notification mechanisms are triggered during critical events. This process can uncover blind spots in monitoring setups, giving teams the chance to address them before they lead to undetected issues [5][13].
How to Implement Fault Injection Testing
::: @figure 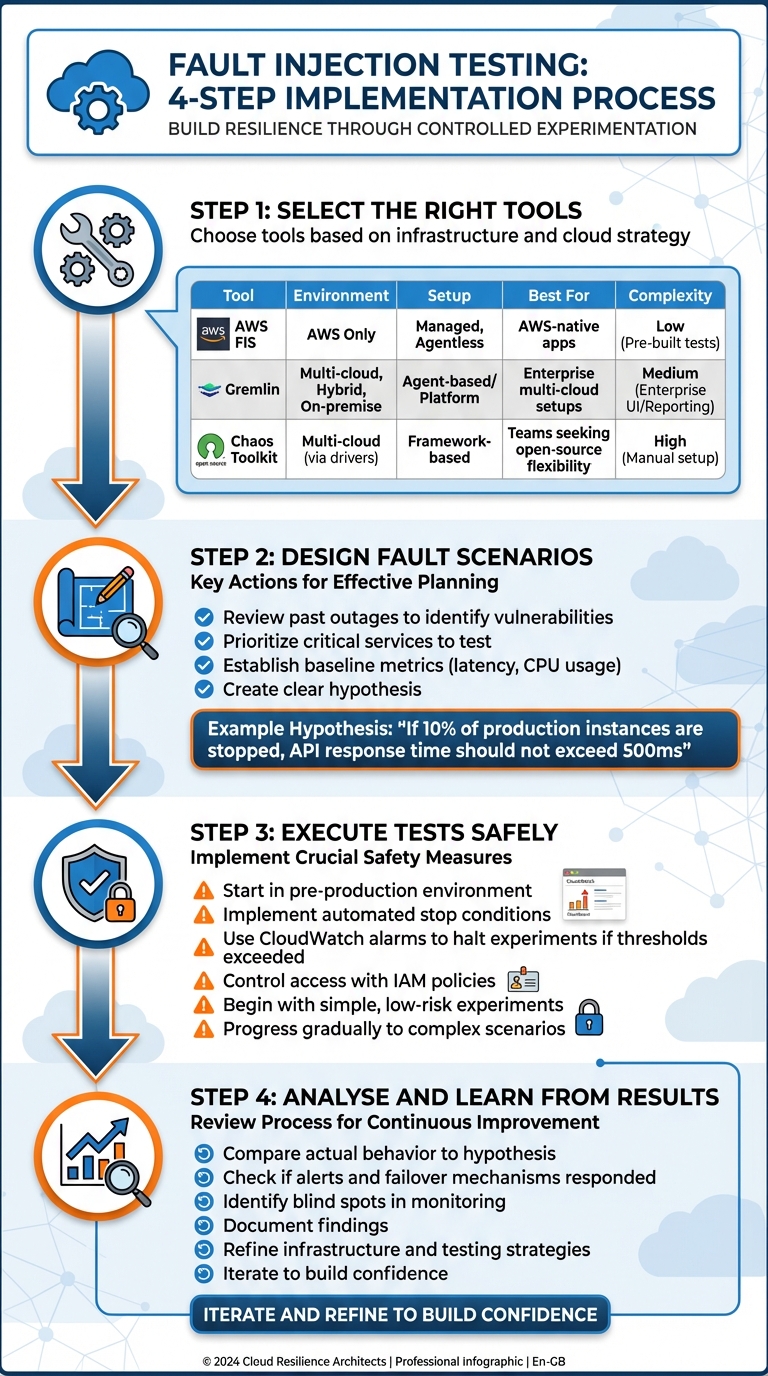 {4-Step Fault Injection Testing Implementation Process for Cloud Systems}
:::
{4-Step Fault Injection Testing Implementation Process for Cloud Systems}
:::
Fault injection testing requires a careful and systematic approach to ensure safety and effectiveness. The process involves selecting the right tools, creating realistic fault scenarios, safely executing tests, and analysing results to improve system resilience.
Step 1: Select the Right Tools
The tools you choose will depend on your infrastructure and cloud strategy. For AWS workloads, AWS Fault Injection Service (FIS) is a managed, agentless option that integrates seamlessly with AWS APIs. It can simulate failures like API throttling, database failovers, and availability zone outages. FIS is particularly useful for organisations fully operating within AWS, offering pre-built scenarios that require minimal configuration [3][9].
For more diverse environments, Gremlin supports multi-cloud, hybrid-cloud, and on-premise setups, providing flexibility for enterprise needs. If you're looking for an open-source alternative, Chaos Toolkit offers an adaptable framework with drivers and add-ons, though it demands more manual effort. For highly customised scenarios, tools like stress-ng allow precise control over resource loads but come with the trade-off of higher maintenance [14].
| Feature | AWS FIS | Gremlin | Chaos Toolkit |
|---|---|---|---|
| Environment | AWS Only | Multi-cloud, Hybrid, On-premise | Multi-cloud (via drivers) |
| Setup | Managed, Agentless | Agent-based / Platform | Framework-based |
| Best For | AWS-native apps | Enterprise multi-cloud setups | Teams seeking open-source flexibility |
| Complexity | Low (Pre-built tests) | Medium (Enterprise UI/Reporting) | High (Manual setup) |
Once you've chosen your tool, the next step is to design fault scenarios tailored to your system.
Step 2: Design Fault Scenarios
Start by identifying potential vulnerabilities in your system. Review past outages to pinpoint recurring weaknesses and prioritise the most critical services to test [6]. Focus on failures that would have the greatest impact on end-users.
Establish baseline metrics - such as latency or CPU usage - to define your system's normal performance [6]. Then, create a clear hypothesis for each test. For instance, If 10% of production instances are stopped, API response time should not exceed 500ms.
AWS FIS enables precise targeting, allowing you to simulate faults on a specific subset of resources, like instances tagged with environment:prod
[9].
You can also leverage AWS FIS's library of pre-defined scenarios to test common issues, such as cross-region connectivity outages or power failures in an availability zone [3][9]. Once your scenarios are ready, it's time to move on to testing.
Step 3: Execute Tests Safely
Executing tests in a controlled and secure manner is crucial to avoid unintended disruptions. Always start in a pre-production environment before testing in production [6][1][15].
Implement safety measures such as automated stop conditions. For example, set up CloudWatch alarms to immediately halt experiments if metrics exceed predefined thresholds [3][9]. Use IAM policies to tightly control who can run tests and which resources can be targeted [3][9]. Begin with simple, low-risk experiments, like stopping a single EC2 instance, and gradually progress to more complex scenarios involving multiple services [6].
Step 4: Analyse and Learn from Results
After the tests, compare your system's actual behaviour to the hypothesis you formulated. Check whether alerts and failover mechanisms responded as expected. Look for any blind spots where failures were missed or recovery times were longer than planned. Document these findings to refine your infrastructure and testing strategies.
This process of iterating and learning builds confidence in your system's ability to handle disruptions. Over time, it strengthens your infrastructure and ensures your team is better prepared for unexpected challenges in the future.
Best Practices for Fault Injection in Cloud Environments
Building on the implementation steps, these practices are designed to make fault injection testing safer and more effective.
Fault injection testing works best when approached thoughtfully and with clear alignment across the organisation. The practices below can help ensure your testing programme achieves its goals while minimising risks.
Start Small and Scale Gradually
Begin with low-risk, non-production experiments before attempting tests in live environments. For instance, stopping a single instance or introducing a brief network delay can reveal valuable insights without impacting customers. Once your team understands the system's behaviour and has fine-tuned monitoring thresholds, you can gradually increase the complexity of your tests. Conduct these experiments during off-peak hours or maintenance windows to minimise customer disruption [2][13]. This step-by-step approach builds confidence and allows you to refine automated stop conditions before moving on to more invasive scenarios [1][13].
While there must be an allowance for some short-term negative impact, it is the responsibility and obligation of the Chaos Engineer to ensure the fallout from experiments are minimized and contained.- Principles of Chaos Engineering [13]
Integrate Fault Injection into CI/CD Pipelines
By embedding fault injection into your automated testing workflows, resilience testing becomes a continuous and proactive practice. For example, you can use tools like AWS Lambda or APIs to trigger fault injection experiments as part of a dedicated stage in your deployment process, whether in staging or production environments [16][9]. Set up quality gates to block releases if recovery targets are not met [7][8]. Using dynamic configuration through environment variables, you can run different failure scenarios across development, staging, and production without making code changes [16]. This approach helps uncover vulnerabilities that traditional unit tests might overlook, ensuring your infrastructure can handle real-world challenges before customers are affected [7]. Collaboration across teams further strengthens this integration, ensuring shared responsibility for resilience testing.
Collaborate Across Teams
Effective fault injection testing goes beyond technical challenges to address broader business risks. Involve representatives from development, operations, security, and QA when planning experiments and defining Service Level Objectives. Ensure operations, service reliability, and customer support teams are informed of the testing schedule, and establish clear channels for reporting any issues [2][13]. After each experiment, hold retrospectives to review unexpected behaviours and identify areas for improvement. A culture that avoids blame encourages rapid issue reporting, which is critical for quick responses to incidents. When teams share ownership of the CI/CD pipeline and resilience testing, they can identify root causes more effectively and implement stronger solutions.
Conclusion
Fault injection testing transforms cloud resilience by taking a proactive approach rather than waiting to respond to failures. By deliberately introducing controlled disruptions, organisations can pinpoint weaknesses and identify single points of failure before they affect customers. This method not only validates recovery plans but also enhances monitoring systems, offering better visibility into how infrastructure performs under stress. The result? Greater confidence in your system's ability to handle real-world disruptions.
Take BMW Group as an example. With a reliability rate of 99.95% [4], their approach demonstrates how exposing and addressing vulnerabilities through fault injection can lead to exceptional stability. Achieving this level of dependability requires ongoing, intentional testing that strengthens systems over time.
To make fault injection testing effective, it’s crucial to define measurable steady-state metrics, establish safeguards to protect production environments, and embed testing into CI/CD pipelines. This ensures resilience becomes an ongoing practice rather than a one-off effort. Retrospectives after each test create a feedback loop, improving not just the system but the testing process itself.
While cloud infrastructure will always face unpredictable challenges, fault injection testing equips organisations to recover gracefully. By testing proactively, you can avoid costly outages, maintain customer trust, and achieve long-term operational excellence.
FAQs
What is the difference between fault injection and chaos engineering?
Fault injection is a precise testing technique where specific failures - like network delays, server crashes, or corrupted data - are deliberately introduced to see how individual components manage errors. This method is particularly useful for spotting elusive bugs and confirming that systems can handle isolated problems effectively.
Chaos engineering, by contrast, adopts a broader perspective, simulating large-scale disruptions such as regional outages or cascading failures across multiple services. The aim here is to test the resilience of the entire system by examining how failures spread and whether the infrastructure can continue functioning as expected.
Simply put, fault injection zeroes in on specific failures, while chaos engineering evaluates the overall robustness of a system under challenging and unpredictable conditions.
What are the main advantages of using fault injection in CI/CD pipelines?
Integrating fault injection into CI/CD pipelines means teams can automatically simulate failure scenarios with each deployment. This approach helps identify hidden weaknesses early, boosting system reliability and monitoring capabilities.
Testing for faults during deployment builds trust in a system's ability to handle unexpected problems. It also speeds up feedback, allowing teams to address issues quickly and keep their cloud infrastructure strong and dependable.
What tools are commonly used for fault injection testing in cloud environments?
Fault injection testing is a powerful way to simulate failures in cloud systems, helping teams uncover vulnerabilities and improve overall resilience. Tools like AWS Fault Injection Simulator (FIS) and Azure Chaos Studio offer managed environments to create realistic failure scenarios, making this process more structured and efficient.
With AWS FIS, you can simulate a range of issues, such as stopping EC2 instances, throttling APIs, or even mimicking power outages in specific availability zones. On the other hand, Azure Chaos Studio allows you to inject faults like network delays, CPU stress, or service disruptions across Azure resources. Both tools seamlessly integrate with their respective monitoring systems - Amazon CloudWatch for AWS and Azure Monitor for Azure - so you can track real-time impacts and ensure any changes are automatically reversed when needed.
These platforms also support custom experiments. For example, you can gradually increase CPU usage or trigger database failovers to identify weak spots before they impact users. If you're unsure where to start, Hokstad Consulting can help design and execute fault injection tests tailored to your specific needs, ensuring that your systems align with UK data-security standards and are prepared to handle potential disruptions.