
Autoscaling ensures that your applications can handle fluctuating demand efficiently, especially in edge and multi-region deployments. These setups face unique challenges, such as latency, limited resources, and compliance with data residency laws. This article explores strategies to optimise autoscaling, including reactive, predictive, and hybrid approaches, to maintain high availability and reduce downtime.
Key Takeaways:
- Reactive autoscaling adjusts resources after demand increases but struggles with delays during traffic spikes.
- Predictive autoscaling uses historical data to anticipate demand, reducing delays but requiring accurate forecasting models.
- Hybrid autoscaling combines both methods for better reliability and efficiency, especially in environments with high variability.
- Edge deployments face specific issues like cold starts, hardware diversity, and limited resources, requiring tailored solutions like lightweight models and traffic-aware techniques.
- Multi-region setups benefit from federated scaling, latency-based routing, and robust failover mechanisms to ensure uptime.
Best Practices:
- Use multi-metric autoscalers for better accuracy.
- Implement lightweight machine learning models for edge environments.
- Test predictive scaling in
forecast-only
mode before full deployment. - Ensure consistent configurations across regions to avoid failover issues.
For businesses managing edge and multi-region deployments, combining predictive insights with reactive triggers ensures your systems remain responsive, cost-efficient, and reliable.
Design a multi-region, highly available microservice architecture on GCP to handle 10x traffic spike
Reactive Autoscaling Strategies: A Baseline Approach
Reactive autoscaling steps in to allocate resources only after demand exceeds the current capacity. It works by monitoring real-time metrics like CPU usage and memory consumption, then adjusts resources based on predefined thresholds. This method is often the starting point for most cloud deployments.
Reactive auto-scaling solutions attempt to modify the micro-service resource allocation once the required resources exceed the current allocation. These algorithms are simple to develop and deploy, however, the time taken to scale resources leads to a degradation of resource availability and violates SLA compliance.– Suhrid Gupta, Muhammed Tawfiqul Islam, and Rajkumar Buyya [1]
Comparison: Reactive vs. Proactive Autoscaling
| Feature | Reactive Algorithms | Proactive Algorithms |
|---|---|---|
| Parameter Tuning | Simple | Complex |
| Deployment | Lightweight | Heavy-weight (e.g., ML models) |
| SLA Compliance | Often struggles during peaks | Better for time-sensitive services |
| Scaling Trigger | Threshold-based (Real-time) | Forecasting-based (Predictive) |
These distinctions highlight how reactive autoscaling serves as a foundation, paving the way for more advanced techniques.
Horizontal Pod Autoscaling (HPA) in Kubernetes
Kubernetes' HPA controller operates on a 15-second control loop [4], using a formula to calculate the required replicas:
desiredReplicas = ceil(currentReplicas × (currentMetricValue / desiredMetricValue)) [4].
To avoid frequent scaling, the controller ignores adjustments if the ratio between current and desired metrics falls within a 10% tolerance range. For downscaling, HPA employs a 5-minute stabilisation window, choosing the highest recommendation from that period to minimise disruptions [4][6].
However, in edge environments, HPA's round-robin allocation can misalign resources, especially when high-demand nodes require proximity to users. Research on traffic-aware horizontal pod autoscalers for edge IoT deployments showed a 150% improvement in response time and throughput compared to Kubernetes' default HPA [1].
For Java applications or similar workloads, application warm-up can mislead scaling decisions. To mitigate this, use startup probes or adjust the CPU initialisation period (default: 5 minutes) so that HPA ignores initial CPU spikes that don't represent actual demand [4].
Vertical Pod Autoscaling: Scaling Within a Pod
Vertical Pod Autoscaling (VPA) focuses on optimising resource allocation within individual pods by adjusting CPU and memory levels instead of adding or removing pods [1][5]. This method is particularly effective in edge environments with fixed pod counts and limited resources.
Since Kubernetes v1.35, in-place vertical scaling has been supported, allowing resource adjustments without restarting the pod [5]. This resolves a key limitation of earlier VPA versions, where pod restarts introduced downtime - an issue for deployments requiring constant availability.
It's important not to use HPA and VPA on the same metrics (e.g., CPU or memory) simultaneously. Instead, consider a multidimensional approach: scale horizontally based on CPU and vertically based on memory. This avoids conflicting decisions that could destabilise your cluster [6].
Rule-Based Autoscaling Techniques
Rule-based autoscaling uses simple triggers, such as adding pods when CPU usage exceeds 70% or when memory consumption surpasses 500Mi [4][6]. These thresholds are often set as percentages of requested resources or fixed values.
More advanced setups go beyond CPU and memory metrics, incorporating custom signals like packets-per-second, requests-per-second, or external queue lengths (e.g., Pub/Sub messages) [6][7]. For example, Google Kubernetes Engine (GKE) supports load balancer signals like maxRatePerEndpoint, offering a more proactive scaling trigger compared to lagging metrics like CPU or memory [8].
In GKE (version 1.33 or later), the Performance HPA profile can handle up to 5,000 HPA objects while maintaining the 15-second recalculation period [6]. This feature is critical for large-scale, multi-region deployments managing thousands of microservices across distributed clusters.
When configuring HPA, avoid setting spec.replicas in deployment manifests. This prevents the cluster from reverting the pod count to the manifest value during manual updates, which could cause instability. For workloads driven by specific containers, use container-specific resource metrics instead of aggregated pod metrics. This avoids including sidecar containers such as logging agents, which can skew scaling decisions [4].
These reactive strategies lay the groundwork for exploring predictive and hybrid approaches, which aim to build on these principles for even greater efficiency and reliability.
Predictive Autoscaling: Using Forecasting Models
Predictive autoscaling takes a forward-thinking approach by analysing historical data to anticipate demand and prepare resources in advance. Instead of waiting for demand to spike, it forecasts future needs and pre-launches capacity minutes or even hours ahead of time [18, 19, 20].
This method tackles a key issue with reactive scaling: the delay caused by initialisation. By launching resources based on these forecasts, it avoids the cold start problem, which is especially critical for applications with long warm-up times, like containerised workloads requiring complex bootstrapping [1, 19].
To ensure flexibility, predictive scaling is often combined with reactive triggers. This hybrid setup addresses unexpected demand surges that forecasts might miss, maintaining service availability while still benefiting from the efficiency of prediction [19, 20]. Below, we explore the forecasting models and multi-metric approaches that enhance the precision of predictive autoscaling.
Workload Forecasting with Predictive Models
Forecasting models take resource allocation a step further than reactive methods by planning ahead. Cloud providers use machine learning algorithms trained on historical usage data to generate these predictions. For example, AWS predictive scaling creates hourly forecasts for up to 48 hours, updating every 6 hours. While it requires at least 24 hours of historical data, using two weeks improves accuracy [19, 20, 23]. Google Cloud, on the other hand, needs a minimum of three days of CPU usage history and leverages up to three weeks of data for training its models [10].
In edge environments, where small-scale devices handle compute-heavy workloads, specialised algorithms like AMAS (Adaptive Auto-scaling) are used. AMAS is tailored for IoT workloads that traditional cloud-native tools struggle to manage. Studies reveal that AMAS can reduce delayed requests by 63% and lower average CPU utilisation by over 10% compared to other auto-scaling tools [2].
To maximise the benefits of predictive scaling, it’s crucial to align the system's scheduling buffer with the application's warm-up time. For instance, if a service requires 10 minutes to initialise, resources should be launched at least 10 minutes before the expected demand spike. Without this buffer, the system risks being unprepared when traffic arrives, undermining the predictive advantage [18, 19].
Before fully deploying predictive scaling, many organisations test the waters by running the system in forecast-only
mode. This validation period, lasting between 24 hours and two weeks, allows them to compare predictions against actual demand without risking over-provisioning or service interruptions [19, 21].
| Provider | History Required | Horizon | Update Frequency |
|---|---|---|---|
| AWS (EC2/ECS) | 24 hours (14 days recommended) [11] | 48 hours | Every 6 hours [11] |
| Google Cloud | 3 days (3 weeks for training) [10] | Continuous | Every few minutes [10] |
Multi-Metrics Autoscalers for Better Accuracy
Traditional reactive scaling often relies solely on CPU and memory usage. However, multi-metric autoscalers improve accuracy by incorporating additional signals. Metrics like latency, throughput, and network I/O can provide earlier indications of demand changes, especially in edge or multi-region deployments. For instance, AWS predictive scaling supports metrics such as CPU, network I/O, and Application Load Balancer request counts [12]. Similarly, Google Cloud integrates multiple signals into its models to enhance forecasting precision [10].
Predictive autoscaling works best for workloads with consistent patterns, such as daily traffic cycles or scheduled batch jobs, and for applications with lengthy boot times [18, 22]. However, for workloads with unpredictable or highly volatile demand, time-series models may struggle to maintain accuracy [1]. In such cases, combining predictive forecasts with reactive triggers ensures the system can adapt to both expected trends and sudden anomalies.
Edge clusters introduce unique challenges, particularly due to resource variability. Forecasts can become skewed if devices within a cluster vary significantly in vCPU capacity or network bandwidth [11]. To improve reliability, using uniform instance types within a scaling group is recommended, though this may conflict with the diverse hardware often found in edge environments.
Hybrid Autoscaling: Combining Reactive and Predictive Approaches
::: @figure 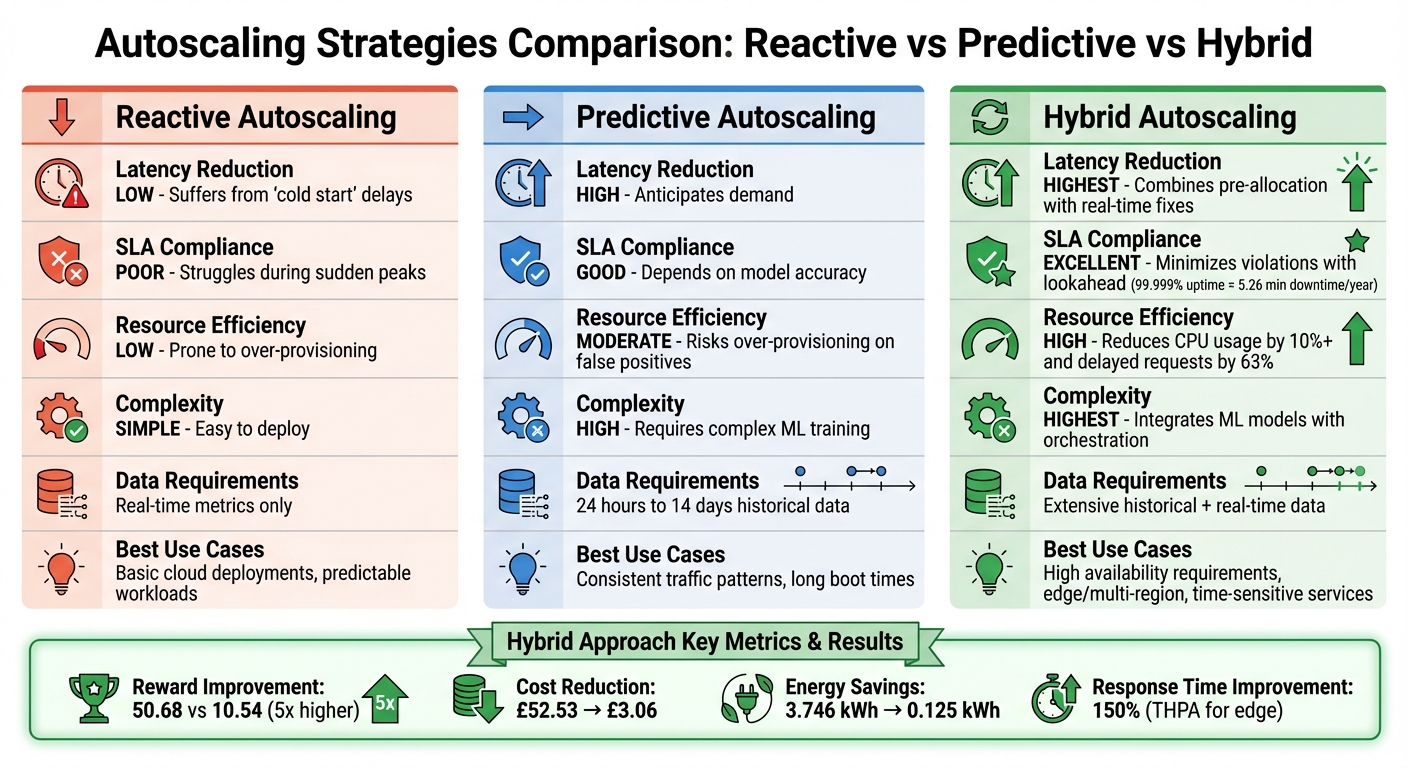 {Reactive vs Predictive vs Hybrid Autoscaling Strategies Comparison}
:::
{Reactive vs Predictive vs Hybrid Autoscaling Strategies Comparison}
:::
Hybrid autoscaling bridges the gap between reactive and predictive strategies, leveraging the strengths of both to create a more balanced and efficient system.
This method starts with reactive scaling while an online machine learning (ML) model is trained. Once the model's accuracy is validated, it shifts to predictive scaling, ensuring a seamless blend of immediate responsiveness and pre-emptive resource allocation [13]. Reactive triggers handle unexpected demand spikes, while predictive scaling anticipates recurring patterns, offering an optimal balance.
The architecture behind hybrid autoscaling often follows the MAPE-K control loop (Monitor-Analyse-Plan-Execute-Knowledge), which dynamically adjusts container counts based on real-time metrics and historical trends [13]. By integrating forecasting into this loop, hybrid systems avoid the pitfalls of reactive crisis management
and instead focus on balancing low latency, energy savings, and cost efficiency [14].
This foresight shifts the whole strategy from 'crisis management' to a continuous balancing act between keeping latency low, using less energy, and cutting operational costs.– Anika Garg, Department of IT, IIIT Vadodara [14]
Hybrid scaling is particularly advantageous for edge deployments, where initial workload behaviour is unpredictable. In these cases, the reactive phase collects telemetry, creating a data foundation for accurate predictions. This is crucial in edge clusters with limited resources, where reducing CPU usage and extending hardware lifespan are top priorities [2][13].
LSTM-Based Hybrid Strategies
Long Short-Term Memory (LSTM) models are well-suited for hybrid autoscaling because they capture both linear and non-linear patterns, as well as long-term dependencies. This makes them ideal for proactive scaling in edge environments [1]. Advanced frameworks often combine LSTM models with Convolutional Neural Networks (CNNs). The CNNs extract short-term spatial features - like local demand patterns - while the LSTMs manage temporal trends [14].
By combining these two, we get the best of both worlds: the CNN is great at spatial feature extraction, and the LSTM is great at temporal modelling.– Anika Garg et al., Department of IT, IIIT Vadodara [14]
One notable example is the AMAS algorithm, which has shown a 63% reduction in delayed requests and a 10% drop in CPU usage when integrated with reactive triggers [2]. Similarly, research presented at the CNSM Conference in October 2022 showcased a Kubernetes edge cluster architecture that combined AIMD-like task scheduling with ML-based profiling. Tested on a small edge infrastructure, this approach reduced CPU core usage by 8% while maintaining Quality of Service (QoS) targets [3].
Another hybrid framework, developed by researchers at IIIT Vadodara, demonstrated impressive results: achieving a reward nearly five times higher (50.68 compared to 10.54) than a purely reactive baseline. It also slashed operating costs from £52.53 to £3.06 and cut energy consumption from 3.746 kWh to 0.125 kWh [14]. These outcomes highlight the real-world benefits of combining predictive insights with real-time adjustments, particularly in scenarios requiring multi-objective optimisation.
Comparing Reactive, Predictive, and Hybrid Approaches
Each autoscaling strategy comes with unique advantages and trade-offs, making it essential to match the approach to specific operational needs.
| Feature | Reactive Autoscaling | Predictive Autoscaling | Hybrid Autoscaling |
|---|---|---|---|
| Latency Reduction | Low; suffers from cold startdelays [1] |
High; anticipates demand [14] | Highest; combines pre-allocation with real-time fixes [13] |
| SLA Compliance | Poor during sudden peaks [1] | Good, but depends on model accuracy [1] | Excellent; minimises violations with lookahead [14] |
| Resource Efficiency | Low; prone to over-provisioning [14] | Moderate; risks over-provisioning on false positives | High; reduces CPU and core usage significantly [2][3] |
| Complexity | Simple to deploy [1] | High; requires complex training [1] | Highest; integrates ML models with orchestration [14] |
| Data Requirement | Real-time metrics only | 24 hours to 14 days of historical data [11] | Extensive historical and real-time data |
For applications requiring high availability (99.999% uptime, or just 5.26 minutes of downtime annually), hybrid autoscaling is the most reliable option [1]. It eliminates cold start delays by pre-loading containers, fetching images, and registering pods before workloads arrive. At the same time, reactive safeguards handle unpredictable spikes, making it invaluable for time-sensitive sectors like healthcare and real-time monitoring, where SLA breaches can have severe consequences [1].
To implement hybrid scaling effectively, start with a forecast only
mode to validate prediction accuracy before enacting active scaling. Additionally, configure a default warmup period for new instances to ensure they are ready to handle traffic when scaling policies activate [11]. These strategies provide a strong foundation for customising policies and developing lightweight models tailored to edge and multi-region environments.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Addressing Edge and Multi-Region Specific Challenges
Handling edge and multi-region deployments comes with its own set of hurdles. Standard autoscalers often fall short due to inefficiencies like round-robin policies that lack awareness of regional specifics or delays caused by cold starts. These shortcomings can lead to breaches of strict SLAs, such as maintaining 99.999% uptime (which translates to just 5.26 minutes of downtime annually) [1]. On top of that, network latency between cloud layers and edge cloudlets adds another layer of difficulty, making real-time scaling a challenge [1]. Failures during failover can also stem from infrastructure inconsistencies across regions, such as mismatched IAM permissions or security policies [9]. And let’s not forget DNS propagation delays - despite low TTL settings, users can still face 5–10 minutes of downtime during regional outages due to ISP caching [9]. These complexities demand specialised strategies, which we’ll explore next.
Federated Scaling Across Regions
Federated scaling focuses on coordinating resources across multiple regions, requiring precise orchestration. Tools like Terraform and CDK play a key role here, ensuring consistent IAM roles, security policies, and configurations across regions to avoid failover issues [9].
While many outages are partial or service-scoped, architectures that assume full regional loss are the only ones that behave predictably under compound failures.– Thilina Ashen Gamage, Platform Engineer [9]
Health check endpoints are crucial for verifying the readiness of backend dependencies like databases and caches, ensuring that entire regions are operational [9]. To minimise downtime during regional outages, AWS Global Accelerator can reroute traffic efficiently, improving network performance by up to 60% by using Anycast IPs to bypass DNS propagation delays [16]. Stateless compute is another critical factor - storing application state in external, durable services like DynamoDB or Aurora instead of local disks ensures seamless failover without data loss [9].
Data consistency across regions is a challenge in itself. Multi-writer setups often require trade-offs between latency and consistency. As Thilina Ashen Gamage points out:
AWS provides replication primitives - not correctness guarantees. Conflict safety is always an application responsibility[9].
For most SaaS systems, active-passive architectures strike a balance by keeping costs low while ensuring data consistency. On the other hand, active-active setups are better suited for high-traffic applications where global low latency is a priority, even if it means tolerating eventual consistency [9].
Mobility-Aware Autoscaling Strategies
Scaling to meet the demands of mobile users introduces another layer of complexity. Edge environments cater to mobile devices via wireless links, leading to constantly shifting resource requirements based on user location [1]. Standard autoscalers often fail to account for these geographic demand patterns. This is where the Traffic-aware Horizontal Pod Autoscaler (THPA) comes into play, modelling resource requests per node and placing pods where mobile demand is concentrated. This approach can boost response time and throughput by 150% [1].
Another effective approach is hierarchical offloading. Geo-distributed edge servers handle local workloads but transfer excess computational tasks to higher-tier remote data centres when capacity is exceeded [1]. Predictive scaling, powered by machine learning models like ARIMA or LSTM, forecasts workload patterns, allowing resources to be spun up ahead of time in areas where mobile users are expected to arrive [1]. This proactive strategy helps to avoid cold start delays, which are especially problematic for mission-critical mobile services.
Latency-based routing directs mobile users to the fastest available region based on their location [17]. For critical applications, a Warm Standby
setup - maintaining a scaled-down version of the environment in a secondary region - enables faster failover compared to traditional Backup and Restore methods [17]. Additionally, optimised container images that use lazy fetching or snapshots can further reduce cold start delays [1].
Integration Limitations with Default Tools
Default Kubernetes tools often fall short when it comes to the unique demands of edge and multi-region deployments. For instance, Kubernetes does not include zone-aware networking by default. This means load balancers might route connections without considering the specific zone of the pod, which can increase latency [15].
To address these limitations, custom solutions are often necessary. Tools like KEDA (Kubernetes Event Driven Autoscaling) allow scaling based on application-specific events - such as the length of message queues - rather than just CPU or memory usage [5]. The AMAS (Adaptive Auto-Scaling) algorithm, designed for edge clusters, has shown a 63% reduction in delayed requests and at least a 10% decrease in average CPU utilisation compared to standard autoscalers [2]. Advanced task scheduling methods, like AIMD combined with ML-based profiling, can also lower CPU core requirements by 8% while maintaining service quality [3].
Pod topology spread constraints and node labels are essential for distributing replicas across different failure zones in multi-region setups [15]. For storage, Kubernetes uses the NoVolumeZoneConflict predicate to ensure pods are placed in the same zone as their associated PersistentVolumes [15]. However, Kubernetes API server endpoints lack default cross-zone resilience, making third-party load balancing or DNS round-robin necessary for high availability across regions [15]. As Thilina Ashen Gamage aptly warns:
Complexity you cannot operate is not resilience - it is risk[9].
Best Practices for Optimised Autoscaling
Successfully implementing autoscaling in edge and multi-region environments takes more than just relying on default settings. These setups often involve complex considerations like geographical differences, resource limitations, and the need for quick responses. By adopting well-thought-out strategies, businesses can see meaningful gains in both performance and cost management.
Custom Policies for Edge and Multi-Region Scaling
Default autoscaling policies that rely on a single metric, like CPU usage, often fall short. Multi-signal scaling offers a better approach by looking at various metrics - such as CPU utilisation, load balancing capacity, and custom application indicators - and scaling based on the metric that calls for the highest number of instances. This method helps to avoid bottlenecks [18].
Handling traffic at the edge requires a specialised approach. Instead of simply spreading workloads evenly, techniques like THPA focus on nodes with the heaviest traffic, improving response times and throughput by as much as 150% [1]. Tools like AWS Global Accelerator or Azure Traffic Manager provide automatic failover, routing traffic to healthy regional endpoints when failures occur [16][19]. For database operations, a read local, write global
setup allows edge locations to handle read-heavy workloads locally while syncing write operations with a global primary database, striking a balance between speed and consistency [16].
To avoid flapping
- the constant scaling up and down of resources - fine-tuning is essential. By setting scale-in controls with initialisation periods, newly launched instances can stabilise before their metrics are factored into scaling decisions [18]. Custom metrics, such as queue depth for task processing or active connection counts for web services, often provide more accurate scaling triggers compared to generic CPU or memory thresholds [18]. These tailored policies enable smarter, data-driven scaling decisions.
Lightweight Machine Learning Models for Edge Constraints
Edge environments often operate under tight resource constraints, making full-scale machine learning models impractical. Instead, lightweight models such as ARIMA (Auto-Regressive Integrated Moving Average) and LSTM (Long Short-Term Memory) are better suited for identifying workload patterns without overloading hardware [1]. These models analyse historical data - typically covering the past 14 days - to forecast hourly workload demands for the next 48 hours, updating every 6 hours to ensure accuracy [11].
In June 2024, Saptarshi Mukherjee from Google and Subhajit Sidhanta from IIT Kharagpur introduced AMAS (Adaptive Auto-Scaling), designed for edge clusters running compute-heavy IoT tasks. Their research demonstrated a 10% reduction in average CPU usage and a 63% decrease in delayed requests compared to traditional auto-scalers. This not only improved performance but also extended device lifespans and reduced failure rates [2]. Similarly, ML-based Application Profiling Modelling has been shown to cut CPU core usage by 8% while maintaining acceptable service quality [3].
When rolling out predictive scaling, it’s wise to proceed cautiously. Running models in a forecast only
mode lets teams compare predictions against actual traffic before enabling automatic scaling [11]. Pre-launch buffers can help ensure that containers are ready before traffic spikes, while cooldown periods of 300–600 seconds prevent unnecessary scaling triggered by minor fluctuations [20].
Proactive auto-scaling solutions attempt to model resource allocation over time and effectively predict the resource requirements... This approach removes the latency inherent in scaling resources.– Suhrid Gupta, Muhammed Tawfiqul Islam, and Rajkumar Buyya [1]
Working with Experts for Cloud Optimisation
Navigating the challenges of multi-region and edge autoscaling often requires expert guidance. Many issues arise not from the limitations of cloud platforms but from prioritising features over planning for potential failures or trade-offs [9]. While proactive autoscaling models are excellent for reducing latency, they can be complex to develop, train, and fine-tune for specific applications [1]. As Thilina Ashen Gamage aptly notes:
Complexity you cannot operate is not resilience - it is risk[9]
Experts can help simplify these complexities, ensuring smooth operation of multi-region setups. This includes maintaining consistent IAM policies across regions, securing data replication, and making smart choices between active-active and active-passive configurations to balance costs [9]. Standard autoscaling tools, like Kubernetes Horizontal Pod Autoscaler, often fall short for edge deployments, as they typically use round-robin allocation and don’t account for node-specific resource needs [1]. Custom solutions, tailored to application-specific events, provide more precise scaling mechanisms.
Hokstad Consulting, for example, offers expertise in cloud cost management and DevOps transformation. Their strategies have been known to reduce cloud expenses by 30–50%. They specialise in seamless cloud migrations with no downtime and provide custom automation services to speed up deployment cycles. For businesses managing complex edge and multi-region environments, Hokstad Consulting’s tailored solutions address challenges like geographical distribution, resource limitations, and cost control. Their No Savings, No Fee
model ensures companies only pay when they see real cost reductions. Learn more at hokstadconsulting.com.
Effective implementation starts with planning for failure scenarios. Define what needs to remain operational during a regional outage, including Recovery Time Objective (RTO) and Recovery Point Objective (RPO) targets, before selecting the right cloud services [9]. Avoid over-engineering by resisting the urge to provision full compute capacity in all regions unless absolutely necessary; active-passive setups with warm standbys can keep costs manageable while maintaining resilience [9]. Automating failovers eliminates the risk of human error during critical moments [9]. Finally, ensure robust health checks that assess backend dependencies like databases and caches, rather than relying solely on basic ping
tests, to avoid routing traffic to non-functional systems [9].
Conclusion: Key Takeaways for Businesses
Edge and multi-region deployments demand sophisticated autoscaling solutions. For time-sensitive applications like those in healthcare, where even brief delays can breach SLA agreements, predictive and hybrid strategies are crucial. By pre-scaling resources based on workload forecasts, businesses can ensure containers are primed and ready to handle requests, maintaining high availability standards - such as 99.999% uptime, which equates to just 5.26 minutes of downtime per year [1]. These strategies are indispensable for meeting stringent performance expectations.
Lightweight predictive models like LSTM and ARIMA play a vital role in proactive edge management, addressing resource limitations by analysing historical data to anticipate demand. Hybrid approaches, which combine predictive scaling with reactive downscaling, offer a balanced method for aligning resources with fluctuating workloads.
Given the complexity of implementing these systems, expert guidance is often necessary. Specialists can assist with advanced health checks that assess entire infrastructure stacks (beyond simple ping
tests), ensure consistent infrastructure across regions through Infrastructure as Code (IaC), and help weigh the pros and cons of active-active versus active-passive configurations. Starting with a forecast only
mode can help teams validate predictive model accuracy before enabling automated scaling, while monitoring at one-minute intervals improves response times [21].
For organisations aiming to adopt advanced autoscaling practices, Hokstad Consulting offers tailored solutions in DevOps transformation and cloud cost optimisation. Their expertise in custom automation and strategic cloud migration enables businesses to implement robust scaling strategies while cutting cloud expenses by 30–50%. With a No Savings, No Fee
model, companies only pay if measurable cost reductions are achieved. Visit hokstadconsulting.com to learn how their expertise can reshape your infrastructure and cost management.
FAQs
What are the benefits of hybrid autoscaling in edge computing?
Hybrid autoscaling plays a key role in improving performance in edge computing by intelligently distributing workloads between local edge nodes and central cloud resources. By processing latency-sensitive tasks closer to where the data is generated, it helps cut down delays and enhances the overall user experience.
When demand surges, hybrid autoscaling taps into cloud resources to manage traffic spikes, ensuring services remain stable and uninterrupted. This method works especially well in scenarios with patchy connectivity, as it maintains steady performance while making efficient use of available resources.
What are the main advantages of using predictive autoscaling for multi-region deployments?
Predictive autoscaling brings a host of advantages to multi-region deployments, particularly in terms of performance, cost efficiency, and resource planning. By launching instances in advance of expected traffic surges, it helps minimise latency and ensures users enjoy a seamless experience, even during high-demand periods.
On the financial side, it helps keep cloud spending in check by preventing over-provisioning, with potential savings of up to 15% on hosting costs. Moreover, it delivers precise demand forecasts across regions, enabling smarter and more effective resource allocation.
Why should you test predictive scaling in 'forecast-only' mode before fully implementing it?
Testing predictive scaling in forecast-only mode lets you check how accurate your capacity predictions are without altering your actual resources. This approach helps you refine scaling policies to suit your workload, preventing overspending from over-provisioning or performance dips caused by under-provisioning.
By simulating predictive scaling outcomes, you can roll out policies with confidence, ensuring a balance between efficiency and reliability across your multi-region edge infrastructure.