
Modern development teams need to deliver software quickly, and hybrid cloud setups - blending on-premises infrastructure with public cloud services - make this both possible and challenging. CI/CD (Continuous Integration and Continuous Delivery) is key to automating and synchronising code deployment across these environments, but unique obstacles like network latency, identity management, and cost control require tailored solutions.
Key Takeaways:
- Centralised Pipelines with Distributed Runners: Use tools like GitHub Actions or GitLab CI to manage pipelines centrally while running tasks in specific environments (e.g., on-premises for sensitive data, cloud for scalable workloads).
- Cloud-Agnostic Orchestration: Tools like Terraform and Kubernetes ensure consistency across AWS, Azure, GCP, or on-premises setups.
- Infrastructure and Policy as Code: Automate infrastructure provisioning and enforce compliance using tools like Open Policy Agent (OPA).
- Container-Centric Workflows: Standardise deployments with Docker and Kubernetes, enabling efficient testing and progressive delivery methods such as canary releases.
- Cost Management: Optimise pipelines with techniques like caching, ephemeral runners, and resource tagging to reduce expenses.
By combining these strategies, hybrid cloud CI/CD pipelines can achieve consistent, secure, and efficient software delivery across diverse environments.
Hybrid CI/CD with Kubernetes & Codefresh
Centralised Pipeline Control with Distributed Runners
Hybrid cloud CI/CD thrives on a centralised control plane combined with distributed runners across various environments. Instead of juggling separate pipelines for on-premises and cloud tasks, your team can work from a single control hub while assigning build and test processes to runners strategically placed where they’re most effective.
How Centralised Control Works
Platforms like GitHub Actions or GitLab CI serve as the central orchestrator, handling job scheduling, pipeline logic, and result tracking. Meanwhile, runners - the agents performing the pipeline tasks - are deployed wherever they’re needed: on-premises, in a private cloud, or across public cloud regions. This separation is crucial. Your pipeline’s definition remains centralised, but its execution is distributed. For instance:
- A job requiring access to an internal database runs on a private network runner.
- A stateless compilation task runs on an elastic public cloud runner.
The control plane coordinates these tasks without needing to manage the specifics of each environment. This setup simplifies operations and can also boost performance.
Benefits of Distributed Runners
One big advantage of distributed runners is lower latency. By placing a runner within the same network as its dependencies - like internal databases, APIs, or package registries - you avoid unnecessary network round trips [1]. This keeps critical processes running locally, speeding up execution.
Distributed runners also enhance security and compliance. Runners within a private network can access sensitive data or systems without requiring broad firewall changes or fragile tunnels [1]. For example:
- Integration tests can stay within your private network.
- Stateless jobs can scale dynamically in the cloud.
Here’s a quick breakdown of ideal environments for different workloads:
| Workload Type | Best Fit Environment | Rationale |
|---|---|---|
| Static Compilation | Public Cloud | Highly parallel, stateless, and bursty workloads |
| Integration Tests | Private/On-Premises | Proximity to internal systems and sensitive data |
| Secrets Broker | Private Cloud | Centralised governance with strict audit requirements |
| Production Runtime | Boundary-based | Depends on data locality and user proximity |
Data source: [1]
When to Use This Pattern
This setup is particularly valuable for regulated industries - like financial services, healthcare, or public sector organisations - where compliance, data residency, and cost control are critical. It’s also ideal for teams spread across multiple locations, as placing runners near each site reduces latency and keeps sensitive processes within private environments.
Cost considerations can also make this approach appealing. For example, GitHub Actions charges approximately £0.006 per minute for Linux-hosted runners on private repositories [3]. In contrast, self-hosted runners are free to use but require you to manage your own infrastructure [3][5]. For teams with high build volumes, self-hosted distributed runners can offer significant savings - if you’re prepared to handle the operational demands.
Cloud-Agnostic Orchestration and Infrastructure as Code
Cloud-Agnostic CI/CD Orchestration
Distributed runners handle the where, but cloud-agnostic orchestration focuses on the how. Tools like GitHub Actions, GitLab CI, and Jenkins allow pipeline logic to operate seamlessly across AWS, Azure, GCP, or on-premises setups - no need for custom rewrites. This flexibility matters because over 80% of organisations now rely on two or more public cloud providers [4]. Pipelines tied to a single vendor's tools risk limiting adaptability and increasing dependency on that provider.
To enhance security while maintaining neutrality, consider adopting OIDC federation. By replacing long-lived keys with short-lived tokens, you reduce vulnerabilities without compromising on multi-cloud compatibility [3][6].
This orchestration approach lays the groundwork for managing infrastructure consistently across diverse environments.
Infrastructure as Code for Hybrid Clouds
Managing your pipeline is only half the battle. You also need a reliable way to provision and oversee infrastructure across both on-premises and cloud setups. Tools like Terraform are commonly used for this, offering built-in support for multi-cloud and hybrid environments.
By defining infrastructure in code and versioning it, you can let your pipeline handle automatic updates. This ensures every environment - whether development, staging, or production - has a consistent and reproducible setup. It eliminates the headaches caused by manually configured servers. Just as orchestration reduces complexity, consistent Infrastructure as Code (IaC) helps prevent configuration drift between environments.
More teams are now turning to specialised IaC orchestrators like Spacelift, Env0, and Terraform Cloud [6]. Unlike general CI/CD tools, these platforms are designed to manage infrastructure state directly. They handle tasks like state locking, drift detection, and approval workflows automatically, reducing manual intervention.
This unified method complements cloud-agnostic orchestration by ensuring every environment is provisioned in a standardised way.
Policy as Code for Compliance
Hybrid environments often make enforcing uniform security and cost controls a challenge. This is where Open Policy Agent (OPA) comes in, enabling you to write compliance rules as code and integrate them into your pipeline.
With OPA, you can create a policy abstraction layer that smooths out provider-specific differences. For instance, a single storage encryption
policy can simultaneously apply to AWS S3, Azure Blob Storage, and GCP Cloud Storage buckets [7]. This removes the need to maintain separate rule sets for each provider. Minor issues, like a missing cost-centre tag, can trigger automated fixes, while more serious security problems are escalated for manual review [7].
This approach not only simplifies compliance but also ensures your policies are enforceable across all environments.
Container-Centric Pipelines for Hybrid Workloads
::: @figure 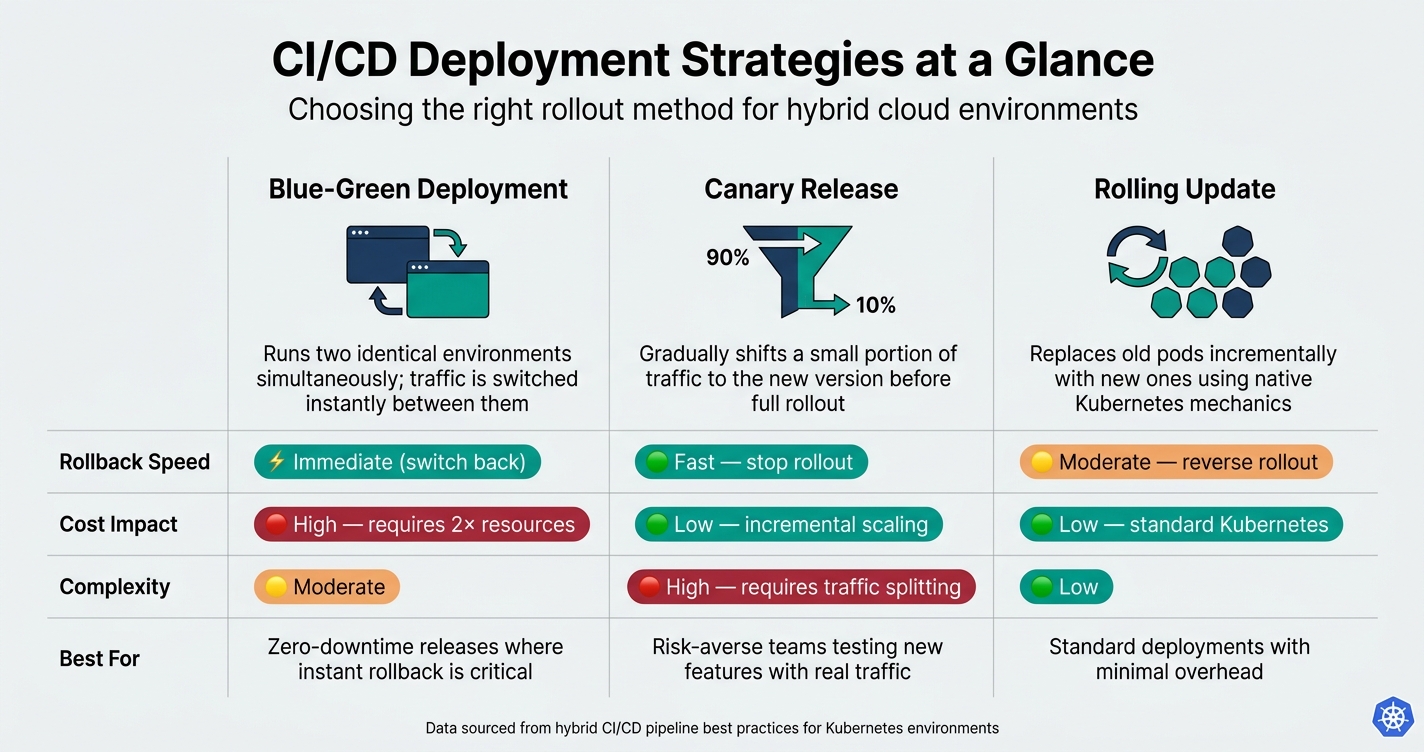 {CI/CD Deployment Strategies: Blue-Green vs Canary vs Rolling Update}
:::
{CI/CD Deployment Strategies: Blue-Green vs Canary vs Rolling Update}
:::
Containers solve many challenges in hybrid CI/CD setups by standardising deployments across various infrastructures. They provide a scalable way to meet the demands of hybrid cloud environments. By packaging an application and its dependencies into an OCI-compliant image, you ensure consistency from testing to production - whether you're deploying to an AWS cluster, an Azure node, or an on-premises server in your data centre.
Build Once, Deploy Anywhere
The concept is simple: build a Docker image once, push it to a centralised registry like JFrog Artifactory or Amazon ECR, and let all environments pull from that single source. This guarantees uniformity across your deployments.
At scale, Kubernetes becomes essential, offering a consistent orchestration API that hides the complexities of differing infrastructures. Combine this with a GitOps workflow using tools like Argo CD or Flux, and your clusters automatically align with the configurations stored in Git. This approach reduces manual interventions and avoids configuration drift.
For teams adopting a cautious approach to changes, progressive delivery tools such as Argo Rollouts or Flagger enable strategies like canary releases and blue-green deployments. These tools allow you to direct a small portion of traffic to the new version before fully committing, ensuring safer rollouts across hybrid clusters.
Supporting Legacy Workloads
Not all workloads can be containerised immediately. Tools like Ansible and SaltStack help bridge the gap by managing legacy systems. They handle tasks like patching, service configuration, and package installation on non-containerised hosts. These tools can be integrated into your CI/CD pipeline, running alongside container deployments. This way, both on-premises, regulated workloads and cloud-based stateless jobs can coexist within the same pipeline [1].
This integration allows legacy systems to complement Kubernetes-driven dynamic testing environments seamlessly.
Ephemeral Testing Environments
With a container-first approach, ephemeral testing environments become a game-changer. Kubernetes can spin up isolated, temporary namespaces for each pull request, enabling integration tests to run in a clean environment. Once testing is complete, the namespace is automatically torn down, eliminating the need for long-lived staging servers that often accumulate configuration issues [1][8].
This method is resource-efficient and avoids the noisy neighbour
problem. By enforcing resource quotas and network policies within each namespace, you maintain control over resource usage [9]. The tested image becomes the immutable artefact deployed to production, ensuring reliability and cost efficiency across hybrid pipelines.
| Deployment Strategy | Rollback Speed | Cost Impact | Complexity |
|---|---|---|---|
| Blue-Green | Immediate (switch back) | High (requires 2× resources) | Moderate |
| Canary Release | Fast (stop rollout) | Low (incremental scaling) | High (requires traffic splitting) |
| Rolling Update | Moderate (reverse rollout) | Low (standard K8s) | Low |
Optimising CI/CD Pipelines for Cost and Scale
Hybrid CI/CD pipelines can quickly become expensive if not managed effectively. However, there are several practical ways to reduce build times and cloud costs while maintaining reliability.
Scaling with Parallelism and Caching
One effective way to optimise pipelines is by parallelising test and build jobs. Instead of running tests sequentially, distribute them across multiple agents to execute simultaneously. For example, in 2025, i2 Group managed to cut their automated test suite runtime from 18–24 hours to just 1 hour by using CircleCI's caching, parallelism, and orbs [4]. This not only speeds up processes but also reduces compute costs.
Another key technique is Docker layer caching, which avoids rebuilding dependencies with every commit. By storing these caches in a shared registry, all runners - whether on-premises or in the cloud - can access them, improving efficiency across the board.
These strategies lay the groundwork for further cost-saving measures.
Cost-Reduction Practices
There are additional methods to keep CI/CD pipeline costs under control:
Ephemeral runners: These temporary runners are spun up only for the duration of a job and then removed. This ensures you only pay for compute resources when they're actively in use. Pairing this with ephemeral Kubernetes namespaces enhances efficiency.
Right-sizing resources: Regularly review and adjust resource allocations to avoid over-provisioning, which can lead to unnecessary expenses. Tools like Prometheus and Grafana can monitor CPU and memory usage, helping teams fine-tune resource limits. A European fintech company, under CTO James O'Connor, achieved a 35% reduction in cloud costs within six months by combining automated Kubernetes scaling with cost audits using these tools [2].
Tagging pipeline resources: Add metadata tags (e.g., team, project, environment) to all resources. This makes it easier to attribute costs and identify areas for optimisation, ensuring both on-premises and cloud environments remain cost-efficient and well-managed.
How Hokstad Consulting Can Help
In hybrid cloud environments, keeping costs under control is essential. Hokstad Consulting works directly with engineering teams to improve CI/CD pipeline performance and reduce cloud expenses. Their cloud cost engineering service typically delivers savings of 30–50%. This includes pipeline architecture reviews, caching improvements, right-sizing, and workload routing. Plus, their no savings, no fee
model ensures you only pay when measurable results are achieved. For ongoing support, they also offer a retainer option. Learn more at hokstadconsulting.com.
Conclusion
Managing hybrid cloud environments can be challenging, but applying CI/CD patterns helps simplify the process. By combining centralised pipeline control with distributed runners, cloud-agnostic orchestration, Infrastructure as Code, and container-focused workflows, teams can achieve a balance of consistency and flexibility across both on-premises and cloud systems.
These approaches minimise manual tasks, uphold standards, and ensure portability. As Radu Domnu and Ilias Raftoulis from Red Hat explain:
GitOps practices are becoming the de facto way to deploy applications and implement continuous delivery/deployment in the cloud-native landscape.
Cost management is another crucial aspect. Practices like using ephemeral runners, resource tagging, and parallelised builds are essential for keeping hybrid cloud expenses in check. Without these measures, costs can escalate quickly.
FAQs
How do I decide which CI/CD jobs run on-premises vs in the public cloud?
Deciding where to run your CI/CD jobs hinges on several key factors, including the nature of your workloads, security requirements, and operational priorities.
On-premises setups work well for jobs that handle sensitive data, demand low-latency performance, or need to comply with regulations such as GDPR. This option gives you more control over your infrastructure and data.
Public cloud is a better fit for workloads requiring scalability, access to cloud-native tools, or global deployments. It allows you to leverage the cloud’s flexibility and wide range of services.
A hybrid approach offers a middle ground, combining the strengths of both on-premises and cloud environments. This can help balance security, compliance needs, and cost considerations while adapting to your organisation’s specific objectives.
Each option comes with its own advantages, so the best choice depends on your unique requirements and goals.
What’s the safest way to handle secrets and identity across hybrid CI/CD pipelines?
Combining centralised secrets management with identity federation is a reliable way to enhance security. Tools like HashiCorp Vault or cloud-native alternatives can securely store and rotate secrets, significantly lowering the risks associated with static credentials. For identity, consider federation methods like OpenID Connect (OIDC), which generate short-lived tokens on demand. This approach eliminates long-lived credentials, reduces potential attack surfaces, and supports best practices for securing hybrid cloud environments.
How can I cut CI/CD costs without slowing down builds and tests?
To keep CI/CD costs in check while maintaining speed, consider using Infrastructure as Code (IaC) tools like Terraform. These tools help standardise resource provisioning and reduce the likelihood of errors. You can also optimise resource usage by employing ephemeral agents, spot instances, and container orchestration platforms such as Kubernetes.
In addition, automating your pipelines can make a big difference. Features like dynamic scaling and workload distribution ensure resources are used efficiently. Finally, centralising monitoring allows you to pinpoint and eliminate underused resources, helping you stay efficient without compromising development speed.