
Deploying software across multiple regions isn’t simple. Cross-region CI/CD pipelines face issues like network delays, tool incompatibilities, fragmented monitoring, and high costs. These problems arise when managing deployments across geographies, especially in industries with strict data laws like Healthcare or FinTech.
Key challenges include:
- Network latency: Distance and security layers slow down data transfer.
- Tooling issues: APIs and features differ between regions or cloud providers.
- Monitoring gaps: Logs and metrics are often inconsistent across regions.
- Security risks: Data sovereignty laws and fragmented access controls complicate compliance.
- Costs: Egress charges and duplicated resources inflate budgets.
Solutions focus on automation, standardisation, and localising resources:
- Use local build agents and caching to reduce latency and costs.
- Standardise infrastructure with tools like Terraform or CloudFormation.
- Centralise logging and metrics for clear visibility.
- Implement policy-as-code and centralised secrets management for security.
- Automate deployments and cost tracking to simplify operations.
Expert support can help streamline these pipelines, reduce costs, and ensure compliance with regulations like GDPR. By addressing these challenges, businesses can build efficient, secure, and scalable CI/CD systems.
::: @figure 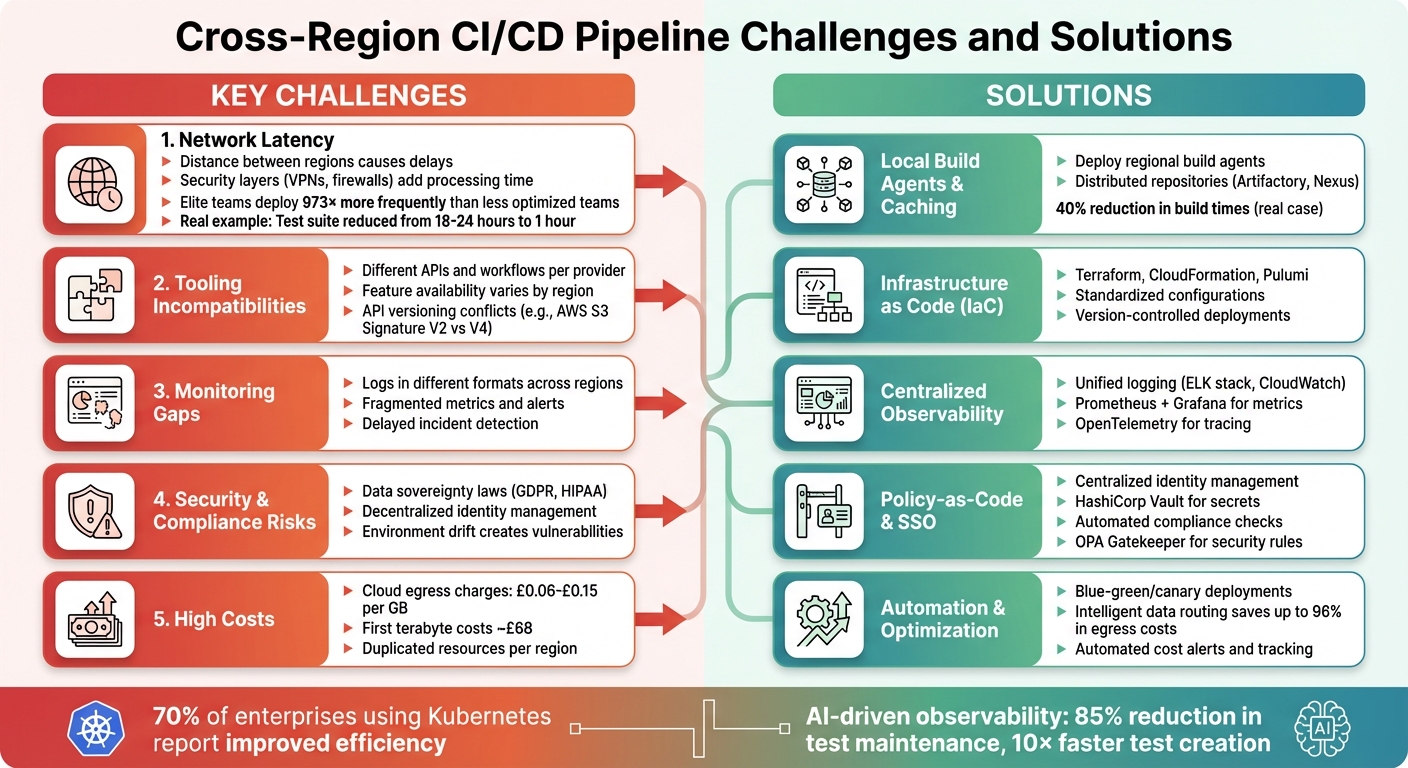 {Cross-Region CI/CD Pipeline Challenges and Solutions Overview}
:::
{Cross-Region CI/CD Pipeline Challenges and Solutions Overview}
:::
Kat LIU : Building Multi-region CI/CD Pipelines with a DevOps Mindset
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Main Challenges in Cross-Region CI/CD Pipelines
Cross-region CI/CD pipelines bring unique hurdles that can impact speed, reliability, and costs. These challenges arise from managing distributed systems across different geographies, each with its own network behaviours, regulations, and infrastructure quirks. Understanding these difficulties is key to building efficient global deployment pipelines. Below, we delve into the main obstacles, from network issues to managing costs.
Network Latency and Data Transfer Delays
Distance between regions and large artefacts often lead to delays in pipeline stages. Adding to this, security measures like VPNs, firewalls, and encrypted tunnels - while essential - introduce extra processing time.
Networking acts as the circulatory system that allows data to flow securely between various components, from code repositories to build servers and from testing environments to deployment platforms.- Trend Micro [6]
The performance gap between teams is striking. For example, elite DevOps teams resolve incidents 6,570 times faster and deploy software 973 times more frequently than less optimised teams [7]. A real-world case highlights this: in 2025, i2 Group reduced an automated test suite's execution time from 18–24 hours to just 1 hour by leveraging CircleCI's caching, parallelism, and orbs
[7]. This shows how tackling network inefficiencies can drastically improve performance.
Latency also causes environment drift, where infrastructure in one region becomes inconsistent with another, jeopardising reliability. Beyond network delays, mismatched tools and API versions add further complications.
Tooling and API Incompatibilities
CI/CD tools are often tailored to specific environments, making cross-region or cross-cloud integration tricky. Different providers use unique workflows, automation capabilities, and APIs, which often require extra integration layers or custom middleware. These additions not only increase complexity but also introduce new failure points.
Feature availability can vary by region. For instance, some AWS CodePipeline action types or service features may not be supported in smaller or newer regions, forcing teams to create separate configurations. API versioning is another headache - Amazon S3, for example, uses Signature Version 2 in older regions but requires Version 4 elsewhere, potentially breaking deployment scripts during expansion.
Implementing CI/CD pipelines in a multi-cloud environment is undoubtedly challenging, but with the right strategies and tools, these challenges can be effectively managed.- Rohit Tiwari, Senior Subject Matter Expert, CloudThat [5]
These incompatibilities often result in teams spending more time maintaining integration code rather than focusing on product development. Configuration drift becomes inevitable when settings must be manually replicated across systems, leading to the infamous it works here but not there
issues. These tooling struggles also exacerbate visibility challenges in distributed systems.
Observability and Monitoring Limitations
Establishing consistent monitoring and logging across multiple regions is a major challenge. Logs may be stored in different formats, metrics in separate systems, and alerts handled differently in each region. Without a unified view, pinpointing failures becomes a slow, frustrating process of piecing together data from disparate sources.
The expanded attack surface of multi-region pipelines adds another layer of difficulty. Security incidents can originate in any region, and fragmented observability slows down detection and response. Teams often discover issues only after they’ve spread across multiple regions, compounding the damage. Without a single pane of glass
for monitoring, engineers have to juggle multiple dashboards, which delays incident resolution and increases response times.
Delayed feedback loops also frustrate developers, who rely on quick confirmation that their changes deployed successfully across all regions. When visibility gaps prevent real-time insights into pipeline health, confidence in the deployment process erodes. This often leads to slower releases and risk-averse behaviours.
Security and Compliance Risks
Cross-region pipelines must navigate a maze of data sovereignty and residency laws, which often require data and workloads to remain within specific jurisdictions [3]. Cloud providers and regions come with their own security features and APIs, making it difficult to maintain consistent protection and compliance standards, such as GDPR or HIPAA [5].
Each cloud provider has unique security features, making it challenging to ensure that data is protected and compliance standards (like GDPR or HIPAA) are met uniformly across all environments.- Rohit Tiwari, Senior Subject Matter Expert, CloudThat [5]
Managing identity and access control across regions is particularly tricky. Decentralised identity management increases the risk of unauthorised access, while secrets management across regions can expose sensitive data if not handled securely. Manual changes and regional differences often lead to environment drift, creating vulnerabilities that may go unnoticed until exploited.
| Security Challenge | Impact on Cross-Region CI/CD | Recommended Mitigation |
|---|---|---|
| Data Sovereignty | Legal/regulatory non-compliance | Regional data pinning and automated checks |
| Environment Drift | Security gaps and failures | IaC with automated drift detection |
| Identity Fragmentation | Unauthorised access risks | Centralised SSO and unified IAM policies |
| Secrets Exposure | Compromised credentials | Centralised secrets management (e.g., Vault) |
| Visibility Gaps | Delayed incident response | Centralised logging and SIEM integration |
These risks are compounded by the operational costs of managing multi-region infrastructure.
Cost and Complexity Management
Managing infrastructure across multiple regions increases both direct expenses and operational complexity. Data transfer between regions incurs cloud egress charges, which can quickly add up, especially when large artefacts are involved. Each region also requires its own resources - such as artefact registries, build agents, and monitoring tools - leading to higher costs.
Environment drift doesn’t just pose security risks; it also causes inefficient resource allocation. Teams may over-provision infrastructure, wasting money, or under-provision it, leading to performance issues. Tracking costs across regions with different pricing models and billing cycles adds another layer of difficulty.
Manual processes that work in single-region setups often become unsustainable in multi-region deployments. The administrative burden of managing configurations, troubleshooting region-specific issues, and coordinating deployments takes time away from delivering actual value. Without automation and standardisation, complexity grows with each additional region, making the system harder to manage over time.
Solutions for Cross-Region CI/CD Challenges
The challenges of cross-region CI/CD pipelines can be tackled effectively with the right strategies and tools. By focusing on localisation, standardisation, and automation, teams can build pipelines that are fast, secure, and cost-efficient. Here’s how to address the key challenges in this space.
Reducing Network and Data Transfer Costs
To cut down on latency and bandwidth usage, it’s essential to localise work. Deploy regional build and test agents in each target region to keep build jobs local, reducing the need for constant communication with a central controller. Adding local caching layers or distributed repositories like Artifactory or Nexus can also minimise redundant data transfers, speeding up processes and cutting egress costs. For instance, a financial services company using this setup reported a 40% reduction in build and deployment times while improving fault tolerance[9].
Another effective approach is adopting a cell architecture, where each region operates as an independent unit with minimal dependencies on others. Regional resources are created locally, while global resources like IAM roles are managed separately. This minimises inter-region traffic and prevents configuration drift.
Treating each Region as one cell... decreases cross-regional dependencies. Regional resources are created once in each Region... adding or expanding the workload to additional Regions would have no impact on the state files of existing Regions.– Lerna Ekmekcioglu, AWS[10]
To further manage data egress costs, enable compression for cross-region transfers, co-locate services within the same region whenever possible, and use Content Delivery Networks (CDNs) to offload internet-bound traffic. On AWS, egress fees typically range from £0.06 to £0.15 per GB, with the first terabyte costing around £68[8]. In Kubernetes environments, setting up default deny egress policies and allowing only necessary traffic (e.g., DNS on port 53) can help avoid hidden transfer costs.
If you’re using AWS CodePipeline, configure one artefact bucket per region to ensure build and deploy processes access data with minimal latency. These measures not only reduce costs but also lay the groundwork for consistent orchestration.
Standardising Tools and Orchestration
Consistency is key, and Infrastructure as Code (IaC) plays a crucial role in achieving it. Tools like Terraform, CloudFormation, or Pulumi allow you to define your build environments and dependencies programmatically, ensuring uniform deployments across regions. With versioned module composition - similar to building with Lego blocks - you can maintain consistent resource definitions and avoid code drift.
Parameterising IaC providers with region-specific values enables the same codebase to target multiple locations without manual adjustments. Designate one region for global resources while replicating regional resources like VPCs as needed. Separating infrastructure into distinct namespaces for regional and global resources further strengthens consistency.
The clean account separation lets us easily control the IAM permission for granular access and have different guardrails and security controls applied. Ultimately, this enforces the separation of concerns as well as minimises the blast radius.– Lerna Ekmekcioglu, AWS[10]
Hosting CI/CD pipelines and repositories in a dedicated tooling account, separate from workload accounts, ensures tighter IAM permissions and reduces risks. Adopting a standardised Git tagging convention (e.g., env_region/team/version) allows for precise control over pipeline executions.
Improving Monitoring and Observability
Effective observability begins with centralised logging and metrics collection. Tools like Prometheus for metrics, Grafana for visualisation, and OpenTelemetry for distributed tracing provide a unified view across regions. Aggregating logs centrally using solutions like the ELK stack or AWS CloudWatch Logs Insights ensures consistent formatting and tagging, making it easier to trace issues across regions.
Automated alerting with region-specific context helps teams address problems quickly. Integrating Security Information and Event Management (SIEM) tools strengthens security by correlating events across regions. Together, these measures enhance system resilience and simplify compliance monitoring.
Improving Security and Compliance
Centralising Single Sign-On (SSO) and enforcing policy-as-code frameworks are essential for maintaining security. Using federated identity management simplifies user administration, while consistent IAM policies across regions reduce the risk of unauthorised access.
Policy-as-code tools like Open Policy Agent (OPA) Gatekeeper allow you to enforce security rules programmatically. Integrating linting and static security scans into your pipeline catches vulnerabilities early. For secrets management, tools like HashiCorp Vault or AWS Secrets Manager with cross-region replication ensure that sensitive information remains secure.
Automated compliance checks can verify that data residency requirements (e.g., GDPR or HIPAA) are met, ensuring sensitive data stays in approved regions. Using IaC with automated drift detection prevents security gaps caused by manual changes or regional inconsistencies.
Reducing Costs Through Automation
Automation is a powerful way to control costs while simplifying operations. With IaC, you can eliminate manual provisioning and ensure consistent deployments, avoiding both over-provisioning and under-provisioning.
Implement deployment strategies like blue-green or canary with automated rollback triggers based on real-time metrics. Sequential deployments combined with parallel builds can speed up feedback cycles and reduce data processing volumes[1][9]. AWS CodePipeline’s built-in cross-region actions, for example, automatically handle artefact replication between S3 buckets, reducing the need for custom scripts[2].
Optimise replication paths with intelligent data routing tools, which can save up to 96% in egress costs when replicating data across regions[11]. Tagging resources by region, team, and environment, setting up automated cost alerts, and regularly reviewing spending patterns can also help identify further cost-saving opportunities. Automation not only saves money but also simplifies the complexities of managing cross-region pipelines.
Building Enterprise-Grade Architectures
Scaling cross-region CI/CD pipelines requires a thoughtful, layered approach. By combining containerisation, service meshes, and AI-driven observability, businesses can achieve scalable, efficient, and resilient operations. Here’s how these components fit together.
Containerisation serves as the backbone of scalable systems. It’s no surprise that 70% of enterprises using Kubernetes report improved efficiency and faster scalability [13]. Tools like AWS Step Functions can enable serverless workflows to replicate container images locally in each region [14]. This eliminates the need to fetch images across continents during critical deployments, speeding up processes and reducing latency.
Service meshes provide the networking intelligence needed for seamless cross-region operations. WAN federation links independent clusters, enabling global service discovery and secure mTLS communication [12]. Many advanced setups use a hub-and-spoke model, centralising management while allowing geographic failover. This ensures traffic is redirected effortlessly if local services fail [12]. Service meshes also simplify network management, and when paired with AI insights, they enhance operational stability.
A service mesh decouples operations from development by addressing networking, security, and observability issues across applications with an independent networking layer.– Tetrate Service Bridge Documentation [15]
AI-driven observability is the final piece, revolutionising how teams identify and fix issues. AI agents excel at root cause analysis and enable self-healing capabilities, complementing traditional monitoring tools. For instance, they can analyse DOM snapshots, network activity, and logs to pinpoint pipeline failures in seconds rather than hours [16]. These agents can also adjust pipelines in real time, ensuring systems remain stable without human intervention. Platforms powered by AI have shown an 85% reduction in test maintenance and deliver test creation speeds 10× faster [16]. By integrating AI early in the pipeline - using shift-left intelligence - developers gain immediate feedback on local builds or pull requests before code reaches staging [16].
How Hokstad Consulting Can Help

Adopting these advanced architectures isn’t straightforward - it demands deep expertise in DevOps, cloud infrastructure, and automation. That’s where Hokstad Consulting steps in. They specialise in helping UK businesses streamline their DevOps workflows and cut cloud costs by 30–50% with tailored cross-region CI/CD solutions. Their services include:
- DevOps transformation with automated CI/CD pipelines
- Cloud cost engineering to optimise spending
- Strategic cloud migration with zero downtime
- Custom development and automation for faster deployments
Hokstad Consulting also excels in AI integration. Their expertise spans implementing AI-driven observability solutions that reduce test maintenance and speed up deployment cycles. Beyond technical implementation, they offer ongoing support, including cloud cost audits, security reviews, and performance optimisation. Flexible engagement models - like retainer agreements or savings-based fees - ensure businesses get value without unnecessary expense.
Whether you’re dealing with cross-region latency, multi-cloud complexity, or need advanced service mesh architectures, Hokstad Consulting can help. Their experience with public, private, hybrid, and managed hosting environments enables them to design solutions tailored to your needs. With a focus on cost control and operational efficiency, they tackle the challenges of building robust, enterprise-grade CI/CD pipelines, ensuring your systems are ready for anything.
Conclusion
Cross-region CI/CD pipelines come with their fair share of hurdles: network latency, incompatibilities between tools, fragmented monitoring, security vulnerabilities, and escalating costs. Native tools like AWS CodePipeline and Azure DevOps introduce their own unique APIs and workflows, making integration and deployment even more challenging [4][5]. For UK businesses, ensuring consistent security policies and meeting GDPR requirements across varied environments adds another layer of complexity [4][5]. Without careful planning, these obstacles can snowball into blind spots in monitoring and unpredictable spending.
The solution lies in automation and a disciplined architectural approach. As outlined earlier, overcoming these issues requires clear strategies and meticulous implementation. Techniques such as containerisation, service meshes, and AI-driven observability help build robust, scalable systems. Standardising practices like Infrastructure as Code, policy-as-code, and GitOps ensures a consistent and reliable pipeline. Additionally, automation and smart caching mechanisms simplify deployments, paving the way for smoother operations and readiness for expert support.
Expert guidance can turn fragmented systems into a cohesive infrastructure. Hokstad Consulting specialises in helping UK businesses navigate these challenges, offering solutions that cut cloud costs by 30–50%, implement automated CI/CD pipelines, and ensure compliance with GDPR and PCI-DSS standards. Their approach blends cost optimisation, DevOps expertise, and AI-driven tools to deliver faster deployments and improved system reliability.
Whether you're dealing with multi-cloud setups, cross-region latency, or advanced service mesh complexities, expert solutions can transform challenges into opportunities. Hokstad Consulting offers flexible engagement models, including a no savings, no fee option for cost optimisation, ensuring tailored solutions without unnecessary risks. Building enterprise-grade cross-region CI/CD pipelines requires both technical expertise and strategic foresight, and the right partner can make all the difference in creating systems designed to endure.
FAQs
What are the best ways to reduce network latency in cross-region CI/CD pipelines?
To cut down on network latency in cross-region CI/CD pipelines, one effective approach is to use latency-based routing. This method directs traffic along the quickest paths, ensuring smoother performance. Tools like content delivery networks (CDNs) and optimised routing protocols can play a big role in speeding things up. Another key step is to position workloads in cloud regions that are geographically closer to your users, reducing the physical distance data has to travel.
Tracking actual latency metrics between regions is equally crucial. By keeping an eye on these numbers, you can adjust your architecture as network conditions change, maintaining efficiency. When you combine these techniques, you’re likely to see faster deployments and a more seamless experience for your users.
How can security be maintained consistently across multiple regions in a CI/CD pipeline?
Maintaining security consistency across regions in a CI/CD pipeline can be a challenge, but it’s manageable with the right mix of automation, strict access controls, and constant oversight.
Using Infrastructure as Code (IaC) is a great way to automate security controls. This approach ensures that security policies and configurations are applied the same way in every region, cutting down on the chance of human error. Pair this with a Zero Trust security model, which relies on strict access controls and continuous checks on users and systems, and you’ve got a solid foundation for protecting your pipeline.
Another important layer of security is employing multi-region encryption keys. When managed properly, these keys not only protect your data but also allow it to move securely and efficiently across regions. On top of that, regular audits, strict policy enforcement, and real-time monitoring keep your security measures on track, ensuring they remain strong and consistent no matter where they’re applied.
How does automation help cut costs in multi-region CI/CD deployments?
Automation plays a crucial role in cutting costs for multi-region CI/CD deployments by streamlining and refining processes. With automated pipelines, organisations can deploy infrastructure and applications consistently and reliably across multiple regions. This reduces the need for manual intervention and minimises the risk of errors that could lead to costly downtime or rework.
Using tools like Infrastructure as Code (IaC), businesses can provision resources uniformly, eliminating inefficiencies and ensuring resources are used effectively. Automation also supports dynamic scaling, enabling systems to adjust resource allocation based on demand. This flexibility helps keep cloud spending under control. On top of that, automated monitoring systems can swiftly detect and address issues, ensuring smooth operations and avoiding expensive disruptions.
By improving efficiency, managing resources wisely, and supporting robust multi-region setups, automation delivers measurable cost savings and operational resilience for organisations.