
Managing Kubernetes clusters across hybrid clouds might seem complex, but it doesn't have to be. Multi-cluster CI/CD simplifies deployment across regions, providers, or on-premises setups. By using GitOps tools like ArgoCD and leveraging Kubernetes' flexibility, you can maintain consistent deployments, enhance resilience, and meet compliance needs.
Key Takeaways:
- Multi-cluster CI/CD: Deploy applications across multiple Kubernetes clusters using pipelines. GitOps principles ensure all clusters sync with a central Git repository.
- Hybrid Cloud Benefits: Store sensitive data locally (e.g., UK for GDPR compliance) while scaling globally. Reduces downtime risks and simplifies cost management.
- Planning: Understand Kubernetes basics, map workloads to environments, and design cluster topologies (e.g., hub-and-spoke or full mesh).
- Networking & Security: Use private connections, service meshes, and tools like BGP for reliable cluster communication.
- Standardisation: Tools like Terraform and Kustomize ensure consistent infrastructure and configurations.
- CI/CD Practices: Separate CI (build/test) from CD (deployment), and use GitOps workflows for secure, repeatable deployments.
This guide breaks down the process step-by-step, covering everything from prerequisites to advanced strategies like canary releases and cost optimisation.
Sponsored Workshop: Scaling Multi-cluster Management with Argo CD and Application Sets
Planning Your Multi-Cluster Hybrid Architecture
::: @figure 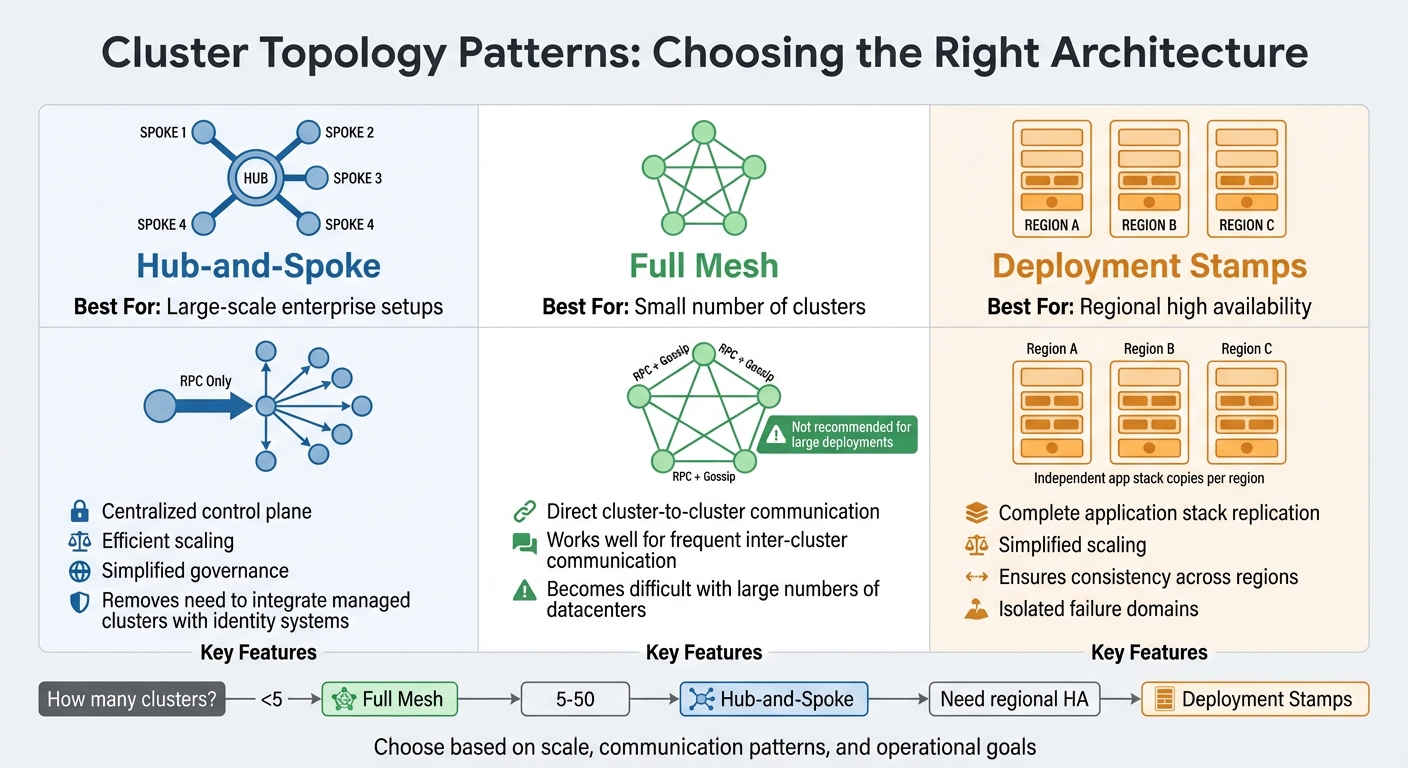 {Multi-Cluster Kubernetes Topology Comparison: Hub-and-Spoke vs Full Mesh vs Deployment Stamps}
:::
{Multi-Cluster Kubernetes Topology Comparison: Hub-and-Spoke vs Full Mesh vs Deployment Stamps}
:::
Before diving into deployment, it’s crucial to have a clear plan for how your clusters will be organised. This phase sets the foundation for a scalable and manageable multi-cluster setup. A key part of this involves understanding trust boundaries - logical divisions based on factors like network zones, operational environments, infrastructure providers, geography, business units, and application teams. These boundaries play a significant role in shaping your cluster organisation [4].
Mapping Workloads to Environments
When distributing workloads across clusters, you need to weigh factors like latency, cost, compliance, and operational constraints. For organisations in the UK, data sovereignty often dictates where data resides. For instance, sensitive data may need to stay within UK-based clusters to meet GDPR requirements, while less sensitive workloads can be allocated to more cost-effective regions globally [12].
Several deployment patterns can help with this mapping:
- Geode pattern: This strategy places compute resources close to users to minimise latency. Any cluster can handle any request, ensuring flexibility [11].
- Deployment stamps: This involves creating independent copies of your entire application stack in multiple regions, which simplifies scaling and ensures consistency [11].
- Cloud bursting: This approach replicates workloads in a secondary environment to handle peak demand, reducing the need for over-provisioning in your primary infrastructure [9].
You also have architectural choices to consider:
- Replicated architecture: All clusters host identical services, maximising reliability and uptime. However, it requires more resources [12].
- Split-by-service architecture: Different services are distributed across clusters, with a service mesh managing request routing. This enhances security and resource allocation but introduces added routing complexity [12].
Modern GitOps tools, such as ArgoCD, enable dynamic mapping by using cluster labels and cluster claims.
For example, clusters can be targeted based on metadata like env: prod or platform: AWS, removing the need to hardcode cluster names [4]. For larger organisations, a cluster-per-team approach can help limit the impact of failures and allow teams to independently manage and scale their infrastructure [4].
Once workloads are assigned, the next step is designing a cluster topology that balances governance with resilience.
Cluster Topology Design
Your cluster topology should align with your operational goals, whether that’s simplifying governance or maximising resilience. Two common models to consider are hub-and-spoke and full mesh.
In the hub-and-spoke model, a centralised control plane manages cluster lifecycles, governance, and workload distribution. As Jeroen Wilms from Red Hat explains:
The centralized control plane model in which all administrative and application activity is initiated from the hub has been long established in IT and removes the need to integrate managed clusters with identity systems and track user activity [4].
This setup is efficient for scaling, as spokes only need to connect to the hub.
On the other hand, a fully distributed (meshed) architecture links every cluster to every other cluster. While this approach works well for small environments with frequent inter-cluster communication, HashiCorp warns:
for organisations with large numbers of datacenter locations, it becomes increasingly difficult to support a fully connected mesh [8].
Here’s a quick comparison:
| Topology Pattern | Best For | Connectivity |
|---|---|---|
| Hub-and-Spoke | Large-scale enterprise setups | Spokes connect only to the hub (RPC only) |
| Full Mesh | Small number of clusters | All clusters connect to each other (RPC + Gossip) |
| Deployment Stamps | Regional high availability | Independent app stack copies per region |
Many organisations designate a primary cluster to manage global states, such as ACLs, service mesh configurations, and Certificate Authority (CA) management [8]. For high availability, an active/active setup across multiple regions ensures that if one region fails, global load balancers can redirect traffic to healthy clusters [11].
Networking and Identity Setup
With your topology in place, the next step is to establish robust networking and identity configurations to enable secure communication between clusters.
Start by ensuring reliable private connectivity. This can be achieved using dedicated links like AWS Direct Connect or Google Cloud Interconnect, or VPNs for smaller deployments. For high availability (99.99%), use redundant connections across different edge availability domains [14].
IP address management is another critical consideration. Ensure that node and pod CIDRs don’t overlap across on-premises clusters, cloud VPCs, or Kubernetes service CIDRs. Use IPv4 RFC-1918 ranges (e.g., 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16) to ensure compatibility [13]. Networking should support at least 100 Mbps bandwidth with under 200ms round-trip latency [13].
To make pod networks routable across hybrid environments, use Border Gateway Protocol (BGP). This approach scales better than static routes and supports direct communication between cloud and on-premises workloads [13]. If pod networks can’t be made routable, configure your Container Network Interface (CNI) to use egress masquerade or NAT for pod traffic [13].
For security, deploy a service mesh to enable mutual TLS (mTLS) and enforce authorisation policies across clusters. A shared Root CA or Certificate Authority ensures consistent certificate issuance and rotation [14][8]. Workload Identity Federation allows services in one environment to act as cloud service accounts when accessing APIs, removing the need for long-lived credentials [14].
Finally, use mesh gateways to simplify cross-cluster networking. These gateways enable secure communication between services in different clouds (e.g., AWS EKS and Azure AKS) using mTLS [10]. Features like prepared queries
in your service mesh can define fallback options, routing users to the next nearest healthy datacentre if the local one fails [8]. With these measures, you can ensure secure and efficient interoperability across clusters while maintaining strong performance standards.
Standardising Infrastructure and Configuration
Keeping clusters standardised is essential to avoid configuration drift and potential security vulnerabilities. Without consistent standards, environments can become misaligned, leading to operational headaches and exposing gaps in security. To address this, codify your infrastructure to maintain uniformity and control.
Infrastructure as Code for Multi-Cluster Environments
Infrastructure as Code (IaC) forms the backbone of any scalable multi-cluster strategy. By defining your infrastructure in code, you eliminate manual processes, reducing human error and ensuring that every cluster is set up in the same way. As AWS puts it:
Infrastructure as code (IaC) is the ability to provision and support your computing infrastructure using code instead of manual processes and settings [15].
Tools like Terraform are particularly effective here. They’re cloud-agnostic, meaning you can manage resources across multiple cloud providers using a single IaC workflow [10]. This approach ensures consistency, simplifies management, and makes auditing and governance much easier - especially important for organisations in the UK navigating GDPR compliance across hybrid environments.
IaC isn’t just about provisioning infrastructure; it can also automate the installation of critical add-ons like load balancers, security tools, or GitOps agents, ensuring clusters are ready for deployment [2][18]. For scaling, abstractions like MachinePools allow you to adjust worker nodes across cloud providers while maintaining specific hardware configurations for different workloads [17]. Terraform’s remote state feature is another powerful tool, enabling the sharing of key data - such as cluster IDs or endpoints - between environments. This automation makes it easier to set up cross-cluster services, like service mesh federation [10].
For those looking to extend GitOps principles to their entire infrastructure stack, tools like Crossplane allow Kubernetes clusters to manage external cloud resources (e.g. databases or storage) as if they were native Kubernetes objects [18].
Configuration Management Across Clusters
Once your infrastructure is in place, managing application configurations consistently across clusters becomes the next challenge. GitOps has emerged as the go-to approach for handling this. As Radu Domnu and Ilias Raftoulis from Red Hat explain:
GitOps practices are becoming the de facto way to deploy applications and implement continuous delivery/deployment in the cloud-native landscape [16].
In a GitOps workflow, Git acts as the single source of truth. Tools like Argo CD or Google Config Sync ensure clusters automatically align their state with the Git repository [16].
To address environment-specific differences - such as varying replica counts between staging and production - tools like Kustomize or Helm are invaluable. Kustomize, for instance, allows you to define a base configuration and layer environment-specific patches on top, ensuring updates to the base manifest are applied consistently across clusters [6]. You can even automate configurations based on cluster metadata, such as env: prod or platform: AWS [4][17].
For enforcing governance and compliance, policy engines like Open Policy Agent (OPA) or Kyverno are key. These tools validate requests to Kubernetes clusters against organisational policies, ensuring security and compliance standards are upheld [6][17]. When it comes to managing secrets, avoid storing plain credentials in Git. Instead, use tools like Sealed Secrets (via kubeseal) to encrypt sensitive data into SealedSecret resources, which the cluster controller can decrypt into standard Kubernetes Secrets [18][19]. Alternatively, the External Secrets Operator integrates with cloud-native secret managers like AWS Secrets Manager or Azure Key Vault, offering another secure option [18].
Consistent configuration is only part of the equation - centralised artefact management also plays a critical role in maintaining reliability across clusters.
Artefact Management and Security
In multi-cluster setups, building container images once and promoting them across environments ensures consistency. This approach eliminates the infamous it works on my machine
problem, as the same artefact tested in staging is deployed to production.
Use a central registry, such as Google Artifact Registry or a private registry accessible to all clusters, to store your container images. Avoid using the latest tag in production, as it can lead to unpredictable deployments. Instead, opt for Git tags or semantic versioning (e.g. v1.0, v2.0) to maintain control over rollouts [6][19]. This practice not only simplifies deployments but also enhances security by ensuring that only tested and verified images are used.
Building the CI Layer Across Hybrid Clusters
With a standardised infrastructure and centrally managed artefacts in place, the next step is creating a Continuous Integration (CI) layer that works seamlessly across all clusters. Your pipelines should be designed to avoid vendor lock-in while maintaining security and performance. This builds on the foundation of your infrastructure and artefact management, ensuring smooth CI execution.
Designing Cloud-Agnostic CI Pipelines
By leveraging your standardised configurations, you can design CI pipelines that deliver consistent results across clusters. The key is to centralise pipeline logic while enabling distributed execution. Host the orchestration logic in a neutral control plane, such as a SaaS CI/CD platform or a self-managed hub cluster. This ensures your build and deployment templates remain uniform across environments without tying you to a specific cloud provider [20][16].
To enhance performance and reduce latency, deploy CI runners within each environment. These runners also handle local secrets, ensuring sensitive data stays secure [20]. A hub-and-spoke model works well here: centralise the configuration while delegating build tasks to local agents. As noted in the Jenkins X documentation:
The multi cluster setup of Jenkins X is designed around... having no development tools installed: no tekton, lighthouse, container registries and no images are built in production [1].
This approach keeps production clusters clean, focusing solely on running workloads, while development and build activities are handled elsewhere.
Secrets Management and Security in CI
Securing secrets across hybrid environments is critical. Avoid using long-lived static tokens. Instead, adopt OpenID Connect (OIDC) to enable your CI/CD systems to authenticate with cloud providers using short-lived ID tokens [21][16]. According to GitGuardian, this strategy significantly reduces risks: even if a token is compromised, its short lifespan limits potential damage [21].
A centralised secrets manager - like HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault - should serve as your single source of truth [21][22][20]. Tools like the External Secrets Operator can sync secrets from these managers into Kubernetes clusters as native Secret objects. This allows applications to access them without needing direct integrations with the secrets provider [23][16]. For added security, restrict CI runners and service accounts to only the permissions they require, and automate secret rotation to minimise exposure windows [21][22].
Once your CI operations are secure, the focus shifts to promoting artefacts across environments.
Promoting Artefacts Across Environments
Consistent image promotion is essential for maintaining deployment integrity in a multi-cluster setup. GitOps workflows are ideal for handling this process. After your CI pipeline builds and tests an image, it pushes the artefact to a central registry and updates the image tag in your repository [20].
Promoting an artefact from staging to production usually involves creating and merging a pull request in your GitOps repository [1]. This step acts as an approval gate, offering full deployment visibility. In multi-tenant environments, ensure your GitOps instances are scoped to specific managed clusters or namespaces. This ensures teams can only deploy to their authorised environments [16][4]. Separating CI (build and test) from CD (deployment and state management) keeps pipelines streamlined and production environments secure [16][20].
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Implementing Multi-Cluster Continuous Deployment
Once artefacts are built and promoted through CI, the Continuous Deployment (CD) phase takes over. This is where GitOps workflows come into play, making it easier to manage deployments across hybrid cloud clusters. With Git as the single source of truth, CD tools ensure that the desired state defined in your repository is continuously reconciled with the actual state running in your clusters.
Keeping CI and CD Separate
Separating CI and CD processes is key to maintaining a secure and scalable architecture. Allowing CI to directly handle deployments introduces unnecessary risks. As outlined in the Stakater Playbook:
The CI pipeline should not directly deploy... we essentially maintain separate repositories for the application code, and the cluster configuration [24].
In this setup, the CI pipeline focuses on building and testing artefacts. It then updates a dedicated configuration repository. From there, GitOps operators like Argo CD or Flux detect the changes and handle deployment via pull-based reconciliation. This approach eliminates the need to store cluster credentials, as the operators run within each cluster, monitoring Git and applying changes locally. This not only reduces the attack surface but also prevents the control plane from becoming a single point of failure. Separating responsibilities in this way also allows for more customised deployment strategies across multiple clusters.
Strategies for Multi-Cluster Kubernetes Deployments
While standard Kubernetes Deployment objects support rolling updates, more advanced strategies like canary releases and blue-green deployments are better suited for complex environments [7][26]. Blue-green deployments run two versions of an application simultaneously, switching traffic only when the new version is confirmed to be stable. This approach prioritises safety but requires additional resources. Canary releases, on the other hand, gradually shift traffic to the new version, offering a more resource-efficient alternative [26].
In hybrid setups, these strategies can be extended across clusters by tweaking Service selectors or leveraging tools like Ingress controllers and Service Meshes (e.g., Istio, Linkerd) to handle traffic routing [26]. For organisations managing hundreds of clusters, ArgoCD ApplicationSets become a game-changer. They use templates to generate application manifests for new clusters automatically, significantly reducing deployment times. For example, DigitalOcean managed to cut its multi-cluster deployment time from over 30 minutes to just 5 minutes - a reduction of 83% [25].
Once your deployment strategy is in place, it’s crucial to establish strong observability and rollback mechanisms.
Observability, Rollbacks, and Traffic Management
To monitor deployments effectively, set up observability tools like Prometheus for metrics collection, paired with global aggregation solutions such as Thanos or Cortex. Centralise logs using Fluent Bit or Fluentd, and implement distributed tracing with OTLP, exporting data to tools like Jaeger or Grafana Tempo [27].
Rollbacks in a GitOps model are refreshingly simple. If something goes wrong, all you need to do is revert the problematic commit in your Git repository. The CD tool will then reconcile the cluster to its previous state [7][28]. This declarative model not only simplifies rollbacks but also ensures that every deployment is auditable and repeatable.
For traffic management, tools like Multi-Cluster Ingress (MCI) provide global load balancing, while the Multi-Cluster Services (MCS) API enables service load balancing across clusters in a managed clusterset [4][5]. During upgrades or maintenance, you can drain traffic from one cluster and redirect it to others, ensuring uninterrupted service [5].
To prepare for unexpected outages or planned downtime, consider N+1 or N+2 capacity planning. This means maintaining one or two additional clusters beyond your baseline capacity to ensure resilience. In hybrid environments, where infrastructure is often described as disposable
and there to serve a purpose
, this approach is invaluable for maintaining service reliability [5].
Addressing Challenges and Optimising Operations
Building on the established multi-cluster CI/CD framework, this section dives into tackling operational hurdles in hybrid environments. These setups often bring unique challenges like interoperability issues, rising costs, and ongoing maintenance demands that need careful attention.
Interoperability Challenges and Solutions
When juggling hybrid environments, interoperability challenges are almost inevitable. Common issues include fragmented IAM roles, disparate access keys, inconsistent Kubernetes versions, and diverging networking models across providers [10][29]. Managing clusters across AWS, Azure, and on-premise systems often results in configuration drift due to varying authentication systems and API behaviours.
To address this, cloud-agnostic abstractions can be a game-changer. Tools like Terraform allow you to manage resources across multiple providers using a unified workflow, eliminating the need for provider-specific configurations [10]. For networking complexities, a service mesh federation using tools like Consul with mesh gateways can simplify secure, encrypted mTLS communication and service discovery across environments - no need for complicated VPN or peering setups [10].
Consistency across on-premise and cloud clusters can be maintained with GitOps tools such as ArgoCD or Config Sync [6][4]. Additionally, creating cluster landing zones based on trust boundaries - like network zones, geographical regions, or business units - helps manage identity and data sovereignty while standardising multi-cluster lifecycle management [4].
To simplify onboarding, provide pre-configured starter repositories that meet interoperability standards [6]. Keep in mind that Kubernetes releases minor updates roughly every three months, maintaining support for only the latest three minor versions [5]. This means clusters older than nine months may need API updates during upgrades, so plan ahead.
Once interoperability is under control, the focus shifts to managing costs in hybrid CI/CD setups.
Cost Optimisation in Hybrid CI/CD
Managing costs in hybrid CI/CD environments requires careful monitoring of compute, storage, and data transfer expenses. Data egress costs, in particular, can quickly become a significant expense when moving data between cloud providers or regions. Minimising cross-cloud transfers is a key strategy to keep costs in check.
In 2022, a European fintech company achieved a 35% reduction in cloud costs within six months. Under the leadership of CTO James O'Connor, the team implemented automated scaling with Kubernetes and conducted regular cost audits using Prometheus and Grafana dashboards. They also transitioned to a multi-cloud setup using Crossplane for unified resource management, which sped up deployment cycles [29]. Similarly, a global fintech firm managed workloads across AWS and Azure using Kubernetes and Crossplane, cutting operational costs by 40%, improving resource usage by 30%, and reducing downtime per incident from two hours to less than five minutes [30].
Spot instances or preemptible VMs can slash compute costs by up to 90% for fault-tolerant CI/CD tasks. Tools like HPA (Horizontal Pod Autoscaler) and VPA (Vertical Pod Autoscaler) help adjust resources dynamically, preventing over-provisioning. Scheduling automatic shutdowns for development and testing environments during off-peak hours can also eliminate idle resource costs.
Resource tagging - categorising resources by project, environment, and team - is vital for tracking expenses. Intelligent scheduling and bin packing technologies can further maximise the use of each paid instance by increasing pod density on nodes. To avoid unexpected costs, set up multi-threshold budget alerts and use cost anomaly detection tools to catch misconfigurations early.
| Optimisation Strategy | Primary Benefit | Implementation Tool |
|---|---|---|
| Spot Instances | Up to 90% compute savings | AWS Spot, GCP Preemptible |
| Autoscaling (HPA/VPA) | Prevents over-provisioning | Kubernetes Native |
| Cloud Arbitrage | Leverages lowest regional pricing | Cloud Service Brokerage (CSB) |
| Resource Tagging | Granular cost tracking | Terraform, CloudWatch, Grafana |
| Bin Packing | Higher resource density | Kubernetes Scheduler, CloudNatix |
Day-2 Operations and Maintenance
With infrastructure now standardised, clusters can be treated as disposable infrastructure, simplifying maintenance. This approach enables blue/green cluster upgrades - provisioning a new cluster with the latest version and shifting traffic to it, avoiding risky in-place upgrades.
For planned maintenance, ensure you have at least one extra cluster (N+1) available to handle traffic overflow. For even greater resilience during unplanned outages, consider N+2 planning [5]. Rolling upgrades - where one cluster is drained, upgraded, and then brought back online - are cost-effective but can lower resilience during the process. On the other hand, blue/green upgrades offer higher resilience and easy rollback options, though they temporarily double resource costs [5].
To avoid disruptions during critical periods, implement maintenance exclusions using tools like GKE to define windows when automated updates are prohibited, such as during major business events like Black Friday [5]. Automate security, compliance, and cost policies across clusters using frameworks like Open Policy Agent (OPA) or Cloud Custodian.
Keep detailed runbooks for common incidents, including cluster failures, network issues, and certificate expirations. Regularly test disaster recovery procedures, not just for ideal scenarios but also for complex, real-world failures. Document and practise processes for draining and spilling
traffic across clusters during maintenance, ensuring your networking layer can handle redirection across cloud boundaries [5].
Conclusion
Carefully structuring your environments into distinct clusters for development, staging, and production ensures a secure and isolated setup, laying the groundwork for efficient and agile operations across your pipeline [31].
Adopting a mindset where infrastructure is treated as disposable [5] and building container images once during CI allows the same tested artefact to be consistently promoted across all environments [31]. As Red Hat aptly puts it:
In continuous delivery, every stage - from the merger of code changes to the delivery of production-ready builds - involves test automation and code release automation [3].
For UK businesses, hybrid cloud CI/CD offers tangible advantages. It enhances resilience with N+1 or N+2 capacity planning [5], simplifies compliance by aligning with cluster landing zones [4], and optimises costs through smarter resource allocation and traffic management [5].
To keep developers productive, aim for CI pipelines that finish within 10 minutes, enabling quick iterations. At the same time, integrate security measures like vulnerability scanning and static analysis early in the pipeline to address potential issues proactively [31]. This blend of speed and security supports the robust, scalable framework discussed earlier.
FAQs
How can I maintain data compliance when using multi-cluster CI/CD pipelines in hybrid cloud environments?
To ensure data compliance within hybrid cloud environments, it's essential to align your processes with major regulations such as GDPR, ISO 27001, and PCI DSS. Start by implementing a centralised Identity and Access Management (IAM) system. This should include least-privilege roles, multi-factor authentication (MFA), and automated provisioning to maintain secure and controlled access.
It's equally important to consolidate and regularly review audit logs across all clusters. This enables continuous monitoring and simplifies compliance audits. To further reduce risks, set up automated policies for data handling and retention, ensuring your organisation consistently meets regulatory requirements.
What are the benefits of using GitOps tools like Argo CD for managing multi-cluster deployments?
GitOps tools like Argo CD make multi-cluster deployments easier by using declarative, version-controlled configurations as a single source of truth. This approach ensures that changes are automatically synced across clusters and can be reverted if necessary, which boosts reliability and reduces the need for manual adjustments.
With Argo CD, you can manage multiple clusters from a centralised dashboard. This setup promotes consistent policies, improves scalability, and strengthens security. By automating key processes and cutting down on operational complexity, Argo CD simplifies deployments across hybrid cloud environments, saving both time and effort for DevOps teams.
How can I select the best cluster topology for a hybrid cloud CI/CD pipeline?
Choosing the right cluster topology for your hybrid cloud CI/CD pipeline begins with identifying your specific needs. Think about factors such as latency requirements, data sovereignty regulations, and fault tolerance. For example, latency-critical services may need to operate close to users in the UK, while compliance rules might demand that certain workloads stay on-premises.
The decision largely hinges on the scale of your workloads and the environments you’re managing. A multi-zone node pool can help maximise resource usage and minimise downtime, while a hub-and-spoke model makes it easier to centrally manage multiple clusters. If your organisation faces strict compliance requirements, a landing-zone architecture provides a secure and repeatable framework across cloud platforms.
To choose wisely, start by cataloguing your workloads, estimating network traffic, and factoring in costs within a £-based budget. Testing small-scale prototypes of different topologies can give you insights into their performance and reliability. For tailored guidance, Hokstad Consulting offers expertise in designing, implementing, and fine-tuning topologies to meet UK-specific requirements.