
Latency is a critical factor for cloud performance, especially for applications like gaming, trading, and AI workloads. This article evaluates AWS, Azure, GCP, OCI, and DigitalOcean based on latency metrics, network infrastructure, and optimisation features, with a focus on UK-specific performance. Here's a quick summary:
- AWS: Strong DNS resolution (4 ms median) and sub-millisecond intra-zone latency. However, it relies on the public internet for data transfer, impacting consistency.
- Azure: Utilises a private backbone for predictable performance. UK South to UK West latency averages 7 ms. Offers tools like Proximity Placement Groups for optimisation.
- GCP: Lowest average global latency (14.6 ms) with a robust private fibre network. Premium Tier ensures smooth routing via its private backbone.
- OCI: Excels in consistency with minimal jitter. UK South to Frankfurt latency is 12 ms, outperforming AWS by 29%.
- DigitalOcean: Competitive in local SSD performance but lags behind major providers in cross-region latency due to reliance on the public internet.
Quick Comparison
| Provider | Key Strengths | UK Latency Highlights | Notable Weaknesses |
|---|---|---|---|
| AWS | Sub-ms intra-zone latency, extensive tools | 9–15 ms (London to Frankfurt) | Relies on public internet |
| Azure | Private backbone, predictable performance | 7 ms (UK South to UK West) | Slower API services in some cases |
| GCP | Lowest latency globally, strong edge infra | ~70 ms (UK to Europe routes) | Higher costs for Premium Tier |
| OCI | Consistent performance, minimal jitter | 12 ms (UK South to Frankfurt) | Limited global presence |
| DigitalOcean | Affordable, strong local SSD performance | 85 ms (New York to London) | Slower cross-region latency |
Key Takeaway
Choosing the right cloud provider depends on your workload and geographic needs. GCP leads in low latency, while Azure offers stable performance with hybrid options. AWS provides extensive tools but has less predictable latency. OCI is ideal for consistency, and DigitalOcean suits budget-conscious users with moderate latency needs.
::: @figure 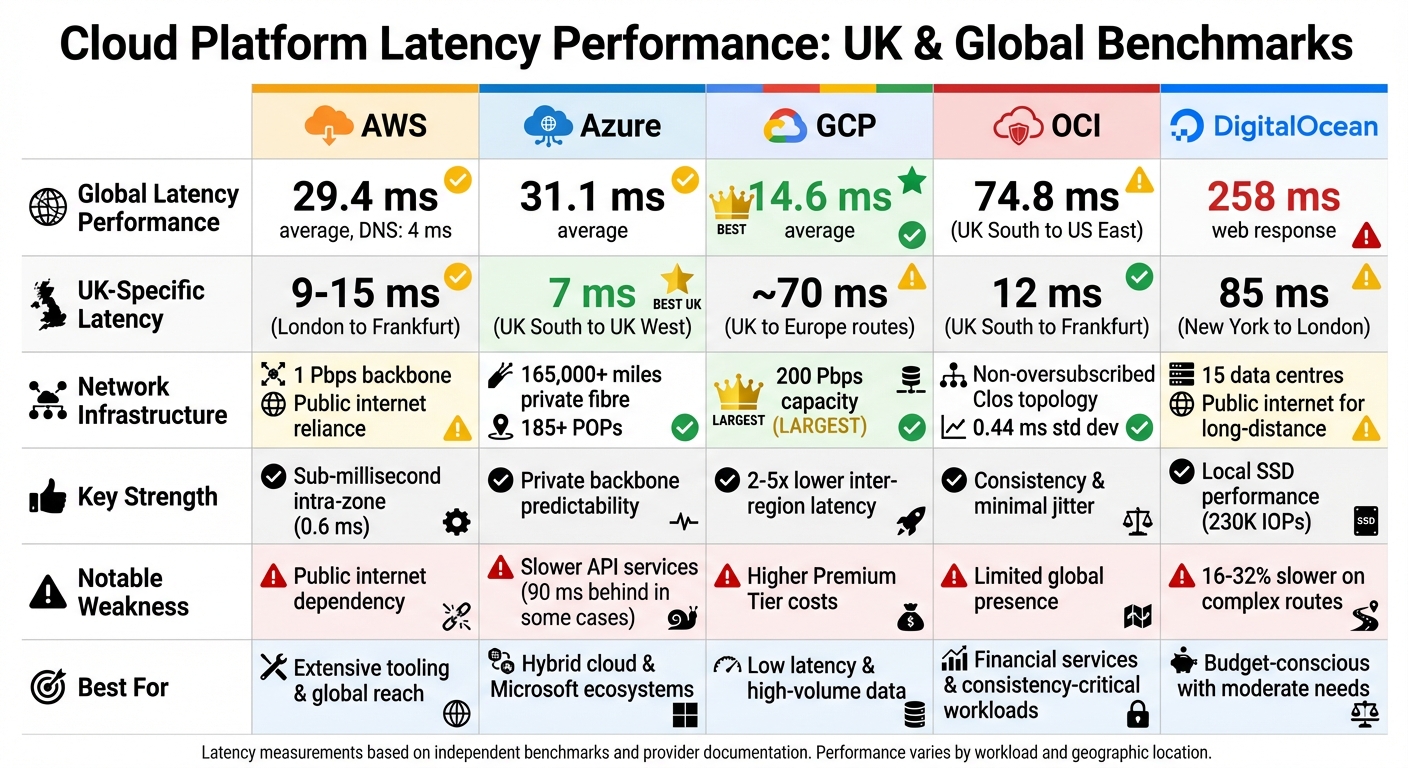 {Cloud Platform Latency Performance Comparison: AWS vs Azure vs GCP vs OCI vs DigitalOcean}
:::
{Cloud Platform Latency Performance Comparison: AWS vs Azure vs GCP vs OCI vs DigitalOcean}
:::
1. AWS
Global Latency
AWS consistently delivers impressive latency metrics. Its median DNS resolution time is around 4 milliseconds, outperforming both Azure and Google Cloud in this area [7]. Dr Paul M Cray from API.expert has also highlighted AWS's steady performance, confirming its median DNS time of ~4 ms since March 2020 [7].
Inter-region latency, however, varies depending on the route. For example, connections from London to Frankfurt typically range between 9–15 milliseconds, while routes from US-East (N. Virginia) to US-West (Oregon) show latency between 60–64 milliseconds [5][8]. Despite these strong metrics, AWS's reliance on the public Internet for data transfer impacts performance predictability. Archana Kesavan, Director of Product Marketing at ThousandEyes, notes:
When compared to Azure and GCP, [AWS] still has lower performance predictability due to its extensive reliance on the Internet rather than leveraging its own backbone for delivery [6].
These figures highlight the importance of AWS's network architecture, which plays a critical role in maintaining performance.
Network Infrastructure
AWS demonstrates strong performance within its infrastructure. Traffic within the same availability zone achieves sub-millisecond latency, averaging around 0.6 milliseconds, while cross-zone traffic sits at approximately 1.1–1.2 milliseconds [10]. AWS's backbone capacity is estimated at 1 petabit per second (Pbps), supported by 10,000 links, each with 100 Gbps capacity [12].
For latency-sensitive workloads, VPC Peering is a better choice than Transit Gateway. While Transit Gateway simplifies management, it introduces an additional overhead of more than 1 millisecond, which can impact performance [10]. Keeping workloads within the same availability zone is essential for achieving optimal latency.
Optimisation Features
AWS offers a range of tools and features to maximise performance and reduce latency further.
- AWS Global Accelerator: By routing traffic through AWS's private network, this service enhances throughput by up to 60% [13]. Lever shared an example where enabling Global Accelerator reduced one multinational customer's mean app load times by 51.2% [13].
- AWS Local Zones: These bring compute resources closer to users in major population centres, enabling millisecond-level latency. Couchbase, for instance, reduced latency by 80% after adopting Local Zones [13].
- Cluster Placement Groups: These group instances within a single availability zone, minimising delays between instances.
- Enhanced Networking (ENA Express): Offers up to 25 Gbps single-flow performance using the Scalable Reliable Datagram protocol [13].
- CloudWatch Internet Monitor: Tracks network performance in real time and suggests routing improvements [9].
- Gateway Endpoints: Designed for S3 and DynamoDB, these endpoints cut internal latency while also eliminating NAT Gateway charges [13].
These features demonstrate AWS's commitment to fine-tuning its network for high performance, especially for latency-critical applications.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
2. Azure
Global Latency
Azure takes a unique approach to network routing compared to AWS. Instead of relying heavily on the public internet, Azure directs user traffic into its private backbone at the point closest to the user. This strategy significantly reduces variability in performance [6]. According to ThousandEyes:
Azure continues its strong network performance based on extensive use of its own backbone to carry user traffic to cloud hosting regions.[6]
This backbone-first method delivers tangible results. For example, Azure has demonstrated strong performance predictability in Asia. ThousandEyes reports that Azure continues to lead in performance predictability in Asia when compared to the other cloud providers
[6]. Performance benchmarks in Sydney showed a 50% improvement, though India experienced a 31% decline [6]. That said, Azure has historically underperformed in certain areas, trailing AWS and Google by about 90 milliseconds for specific API services over a 24-month period ending in 2021 [7].
Within Europe, Azure's inter-region latency also stands out. Connections from UK South to UK West average just 7 milliseconds, while UK South to France Central averages 11 milliseconds [14]. Transatlantic routes, such as East US to UK South, measure around 79 milliseconds, and routes to Southeast Asia reach 155 milliseconds [14]. By relying less on the public internet, Azure achieves greater consistency across regions.
This performance is supported by an advanced network infrastructure, detailed below.
Network Infrastructure
Azure's network infrastructure includes over 165,000 miles of lit fibre optic and undersea cables, along with more than 185 global network Points of Presence (POPs) [15].
Within Azure regions, traffic within the same availability zone experiences latency of about 0.9 milliseconds. Cross-zone traffic within a single region averages 1.5 milliseconds, while cross-region communication is slower - approximately 5.9 times slower than same-zone communication, with cross-region latency measured at 5.3 milliseconds compared to 0.9 milliseconds for same-zone traffic [17].
Azure's infrastructure is powered by SONiC (Software for Open Networking in the Cloud), an open-source switch operating system that facilitates quick updates and high reliability across thousands of switches [15]. For hybrid setups, Azure ExpressRoute provides private connectivity at speeds of up to 100 Gbps [15]. Additionally, Azure's partnership with Oracle supports the OCI–Azure Interconnect, enabling private, low-latency connections typically ranging between 1–2 milliseconds for multicloud environments [16].
Optimisation Features
Azure builds on its strong network foundation with tools designed to optimise performance. Azure Front Door and Azure CDN leverage its global edge network to route traffic into Microsoft's private backbone as close to the user as possible [18]. The Rules Engine adds flexibility by allowing customisation of caching, URL redirects, and header injections at the edge, which reduces the load on origin servers [18].
Proximity Placement Groups combined with Accelerated Networking further improve performance, cutting round-trip times by approximately 27–33% [18]. Azure Edge Zones extend the network into densely populated urban areas, enabling latency-sensitive workloads like IoT and containerised applications to operate closer to users [15]. For monitoring, Azure Monitor and Network Watcher provide real-time insights into latency and help identify network bottlenecks [18].
3. GCP
Global Latency
When it comes to latency, GCP stands out from the competition. Independent tests reveal that GCP delivers an average latency of 14.6 milliseconds, significantly better than AWS at 29.4 milliseconds and Azure at 31.1 milliseconds [12]. In fact, GCP offers 2–5 times lower latency between regions compared to AWS [12].
This difference becomes even more apparent in serverless environments. GCP consistently demonstrated the best performance with an average of 1.14 seconds in serverless benchmarks [11]. Additionally, GCP achieved a network throughput of 9.35 Gb/s, nearly double AWS's 4.97 Gb/s [11].
The key to this performance lies in Google's traffic routing approach. The Premium Tier service ensures user traffic enters Google's network at the closest edge Point of Presence, then travels entirely on Google's private backbone to the destination [19][20]. By bypassing the unpredictable public internet, GCP provides smoother and faster connectivity. As Urs Hölzle, SVP Infrastructure at Google, explains:
The company runs backbone links at only ~40% capacity to leave substantial headroom. This prevents unpredictable congestion spikes causing higher queuing latency.[12]
On top of these metrics, GCP enhances its latency advantage through advanced edge and network strategies.
Edge Performance
Google's edge infrastructure plays a massive role in improving performance. Google Front Ends (GFEs), located at the network edge, terminate TCP and SSL sessions close to users, cutting down connection overhead. For instance, a user in Germany accessing US-Central1 benefits from an External Application Load Balancer that reduces Time To First Byte from 230 milliseconds to 123 milliseconds [19]. In some cases, ping latency to the nearest GFE can drop to as low as 1 millisecond [19].
GCP's reach extends further with Cloud CDN, which operates across over 200 locations. By caching content near users, it eliminates around five round trips per request [12][19]. Features like HTTP/2 and QUIC protocols also help reduce latency by up to 33%, thanks to improved connection multiplexing and zero-round-trip connection resumption [12][19].
Network Infrastructure
Google's private global fibre network is another major differentiator. With a total capacity of around 200 Pbps, it far surpasses the scale of its competitors, including AWS, whose backbone capacity is 100 times smaller [12].
The network's use of Anycast IP addressing ensures that a single IP address can be served from multiple locations simultaneously [12]. This automatically routes users to the nearest healthy endpoint, reducing latency within and across regions. Additionally, GCP supports Jumbo Frames with a maximum transmission unit (MTU) of up to 8,896 bytes, though 4,082 bytes is recommended for optimal CPU efficiency [21][23].
Optimisation Features
GCP offers several features to optimise latency-sensitive workloads. Compact Placement Policies allow Compute Engine instances to be physically collocated, minimising inter-instance delays for workloads that require tight coupling [23]. For TCP workloads, GCP enables users to reduce the Minimum Retransmission Timeout from 200 milliseconds to just 5 milliseconds and supports Fair Queueing to efficiently pace traffic [21].
Tools like the Network Intelligence Centre provide real-time latency metrics, helping users quickly identify and address bottlenecks in cross-zonal traffic or internet-to-GCP paths [22]. Meanwhile, Cloud Trace aids in reducing latency for inter-service RPC calls [19].
4. OCI
Global Latency
BCC Group International conducted a comparison of OCI and AWS performance across key financial hubs. Steven Riley, Senior Cloud Architect, highlighted that OCI maintained an average latency of 74.8 milliseconds on the UK South to US East route, compared to AWS's average of approximately 78 milliseconds [25].
The differences are even more noticeable on certain routes. For instance, the latency between UK South and Frankfurt was 12.0 milliseconds on OCI, while AWS recorded 17 milliseconds, marking a 29% improvement [25]. On routes to the Middle East, the gap widened further, with OCI averaging 70 milliseconds, compared to AWS's 120 milliseconds [25].
What makes OCI stand out is its consistency. It has a standard deviation of just 0.44 milliseconds, significantly better than AWS's 3.00 milliseconds [25]. Steven Riley explains the impact of this:
OCI's tighter standard deviations and lower peak values make its network both faster and more reliable - key for workloads like market data distribution that depend on microsecond‑level timing accuracy.[25]
This level of performance highlights why a cloud provider's network architecture is so critical for latency-sensitive applications. OCI's results reflect a carefully designed system, as detailed in the next section.
Network Infrastructure
OCI's second-generation network is built using a non-oversubscribed, n-tier Clos topology, which ensures consistent performance with minimal jitter [25]. This flat network design eliminates bandwidth bottlenecks at aggregation points.
Private connectivity is delivered through FastConnect, which provides dedicated, low-latency links between data centres and OCI [16][27]. To maintain reliability, multiple dark-fibre cables connect the data centres, ensuring seamless performance [16]. Additionally, network bandwidth scales predictably with compute capacity - each OCPU typically delivers 1 Gbps of bandwidth [25].
For multi-cloud setups, the OCI-Azure Interconnect offers round-trip latencies in the 1–2 millisecond range for most interconnected regions [16]. In Ashburn, tests showed TCP/UDP round-trip times as low as 691 microseconds [16]. Niranjan Mohapatra, Senior Principal Product Manager at Oracle, comments:
The OCI-Azure Interconnect network latency is sufficient for over 95% of applications built on Oracle databases overall. The TCP and UDP round-trip network latency and ICMP round-trip network latency are in the 1–2 ms range for most of the OCI-Azure interconnected regions.[16]
With this dependable infrastructure as a foundation, OCI implements advanced features to further reduce latency.
Optimisation Features
OCI incorporates several tools to enhance latency. SR-IOV enables direct VM access to network hardware, cutting down on overhead, while FastPath in Azure ExpressRoute Gateway bypasses unnecessary gateway hops when connecting OCI to Azure [16][26][27]. In the London region, intra-cloud latency is reduced to just 0.30 milliseconds for ICMP and 0.08 milliseconds for TCP/UDP traffic [26]. In October 2019, OCI Solution Engineer Ben Haworth demonstrated that enabling FastPath reduced round-trip latency from 2–3 milliseconds to between 1 and 2 milliseconds [27]. Further testing in London showed ICMP latency dropped from 2.91 milliseconds to 1.79 milliseconds [26].
For workloads that need proximity to specific data sources, OCI offers a Dedicated Region solution, allowing customers to deploy OCI regions near critical infrastructure, such as stock exchanges, to minimise data travel time [25]. Additionally, the Inter-Region Latency dashboard provides 30-day historical data on round-trip times, aiding in data transfer planning and disaster recovery [24].
These tailored enhancements demonstrate OCI's commitment to delivering reliable, low-latency performance for demanding applications.
5. DigitalOcean
Global Latency
DigitalOcean runs 15 data centres worldwide, but its cross-region latency tends to lag behind major cloud providers like AWS and Azure [4]. For instance, the New York–London route clocks in at 85 ms with DigitalOcean, which is about 16% slower than Azure’s 73 ms [1]. This difference boils down to infrastructure: while AWS and GCP use extensive private fibre networks for traffic routing, DigitalOcean relies more on the public internet for long-distance traffic [1][4]. As the Hathora Technical Blog points out:
The providers that are able to route packets over their private networks vastly outperform those that are at the mercy of the public internet.[1]
That said, DigitalOcean holds its own in areas that matter for many users. Its web server response times average around 258 ms, comparable to AWS and GCP [3]. For storage-heavy tasks, DigitalOcean’s local SSDs shine, delivering random read speeds that are 100–200 times faster than block storage options from AWS and GCP [2]. Their compute-optimised instances hit 230,000 4K Read IOPs, and even the smallest 1 vCPU instance achieves 100,000 IOPs [2].
These performance metrics highlight the trade-offs in DigitalOcean's design, which are discussed further in its network infrastructure overview.
Network Infrastructure
While DigitalOcean leans on the public internet for long-distance traffic, its private backbone ensures reliable connections between its data centres. This backbone uses dark fibre and wavelengths, bypassing the public internet for inter-region transport [28]. Luca Salvatore, Manager of the Networking Engineering Team, explains:
Latency is predictable and stable, and packet loss is nonexistent \[on DO-owned links\].[28]
The platform employs a Layer-3 MPLS/BGP network with a Clos topology, where each hypervisor acts as a default gateway [30][31]. This setup avoids broadcast storms, reduces CPU usage, and supports high bandwidth with 40G networking, scalable to 80G or even 160G aggregation [31]. Virtual Private Cloud (VPC) networking further reduces internal latency by cutting down on hops
between services [29][4]. DigitalOcean also guarantees a 99.99% uptime SLA for both Droplets and Block Storage [4].
Optimisation Features
DigitalOcean includes several features to boost performance. Premium Memory-Optimised and Storage-Optimised Droplets offer up to 10 Gbps of outbound data transfer - five times more than standard Droplets - and Global Load Balancers direct users to the nearest healthy data centre, reducing latency [33][29]. Managed Databases use pre-configured connection pools to reduce the overhead of repeated queries [29].
In July 2025, ad-tech company NoBid transitioned from AWS to DigitalOcean, successfully handling 200 billion auctions per month (equivalent to 100,000 per second). Leveraging Kubernetes, VPC networking, and Global Load Balancers, they cut their costs by 20–30% while maintaining the responsiveness needed for real-time bidding [32]. CIO Shawn Petersen shared:
The price DigitalOcean came back with was literally 20 to 30% cheaper than what we had been paying at AWS.[32]
Additionally, DigitalOcean’s low egress costs (£0.01 per GB) make it an attractive option for high-traffic, latency-sensitive applications [4][32].
Kentik Cloud Latency Map Video Tutorial
Strengths and Weaknesses
Cloud platforms tackle latency in distinct ways, with varying results depending on their infrastructure choices. Both Google Cloud Platform (GCP) and Azure rely on private backbone networks to reduce latency, whereas AWS primarily uses public Internet routes, which can increase operational risks. Archana Kesavan from ThousandEyes highlights this contrast:
While Google Cloud and Azure rely heavily on their private backbone networks... AWS and Alibaba Cloud rely heavily on the public Internet for the majority of transport, resulting in greater operational risk.[6]
When comparing performance, the differences in latency can be substantial. On some routes, latency gaps can surpass 30% [1]. For example, DigitalOcean, which uses standard enterprise ISPs like Cogent, experiences 16–32% higher latency on complex land routes compared to providers with private backbone networks [1]. A clear illustration of this can be seen on the NYC to Seattle route: while undersea routes like NYC to London achieve approximately 79% efficiency across all providers, transcontinental land routes reveal a 32% performance disparity between private-network providers and those relying on public Internet [1].
Regional performance varies widely too. Latin America and Asia often show the greatest fluctuations in latency, where even small delays can severely impact user engagement. In contrast, North America tends to maintain more consistent performance [6]. Some regions, particularly in Asia and Africa, experience bimodal latency patterns - where routes alternate between two distinct paths - causing spikes that exceed 100 ms [35]. Inter-cloud routing also plays a part; for instance, traffic between Sydney and Tokyo from GCP or Azure to AWS can be 20 ms slower compared to other combinations, as inter-cloud latency is typically higher than intra-cloud latency [35].
Another factor influencing latency is edge infrastructure. Edge servers significantly outperform standard cloud data centres, delivering sub-10 ms latency to 58% of users, compared to just 29% for traditional cloud setups [34]. In fact, 92–97% of end-users experience reduced latency when edge servers are used instead of standard cloud providers [34]. At the infrastructure level, GCP demonstrated a single-stream throughput of 9.35 Gb/s, almost double AWS's 4.97 Gb/s. However, AWS maintained a slight edge in round-trip network latency, achieving 60 μs compared to GCP's 67 μs [11].
These findings highlight the importance of thorough latency benchmarking when choosing a cloud platform, as performance can vary significantly depending on the provider and region.
Conclusion
Selecting the right cloud platform depends heavily on your specific workload requirements and geographic considerations. In the UK, Google Cloud Platform shines with a latency of approximately 70 ms, making it ideal for tasks involving large volumes of data, frequent API calls, or scenarios requiring rapid virtual machine deployment. AWS, on the other hand, leads in global network speed and offers extensive coverage with 117 Zones, though it relies more on public internet routing. Microsoft Azure demonstrates strength in hybrid setups and is particularly beneficial for organisations already entrenched in Microsoft ecosystems, offering dependable performance on routes like Europe-to-Singapore. These benchmarks highlight distinct performance characteristics across the platforms.
Even small differences in performance - such as a 20–30 ms gap - can have a noticeable impact on real-time applications and user experiences. For businesses aiming for global scalability, AWS’s expansive edge infrastructure might be the best fit. Meanwhile, organisations leveraging Microsoft tools can take advantage of Azure's features like Proximity Placement Groups and Accelerated Networking. These measurable distinctions emphasise the importance of not just choosing the right platform but also fine-tuning it for maximum performance.
Achieving optimal cloud performance involves more than just picking a provider - it requires tailored configurations and vigilant cost management. Direct connection options like AWS Direct Connect, Azure ExpressRoute, or Google Cloud Interconnect can deliver consistent performance, though managing these connections effectively can be complex.
This is where expert guidance can make a difference. Hokstad Consulting helps businesses optimise cloud infrastructure and reduce hosting costs by 30–50% through strategic cloud migration, DevOps transformation, and cost engineering. Their customised solutions enable organisations to select the best platform, implement performance-boosting configurations, and maintain continuous optimisation. Whether you’re managing a hybrid setup, targeting ultra-low latency, or looking to cut cloud expenses, their expertise ensures you get the most out of your cloud investment. Tailored strategies and smart migrations are key to unlocking the full potential of your chosen platform.
FAQs
How should I benchmark latency for my UK users?
To evaluate latency for users in the UK, assess network performance between their locations and your cloud infrastructure. Use tools like ping and traceroute for basic checks, or opt for more advanced solutions like Netperf or SockPerf for detailed analysis. Conduct latency tests across UK regions, such as UK South and UK West, using small data packets over prolonged durations. Focus on critical metrics like Round-Trip Time (RTT) and Time to First Byte (TTFB) to fine-tune performance for users in the UK.
What causes jitter, and which workloads are most affected?
Jitter happens when network conditions fluctuate, causing inconsistencies in how data packets are delivered. This can stem from issues like network congestion, limited bandwidth, wireless signal interference, or unstable connections - such as when devices switch between access points while roaming.
It’s particularly troublesome for activities that rely on real-time data. Think VoIP calls, video conferencing, live streaming, online gaming, or remote desktop applications. In these cases, uneven packet delivery can lead to lag, interruptions, or a noticeable drop in quality.
When is a private link (Direct Connect/ExpressRoute/Interconnect) worth it?
A private link, like Azure PrivateLink or AWS Direct Connect, becomes essential when low latency, strong security, and consistent connectivity are top priorities. These dedicated connections avoid the usual delays and risks associated with public internet traffic, ensuring faster and more dependable performance.
They’re particularly well-suited for hybrid cloud environments or applications that demand real-time data processing, secure financial operations, or compliance with rigorous regulations like GDPR. This is especially important in industries such as finance, healthcare, and manufacturing, where reliability and security are non-negotiable.