
Achieving high availability in edge computing is complex due to factors like unreliable connectivity, limited hardware, and geographic isolation. This guide breaks down five key architectural patterns to help you design systems that stay operational even when components fail:
- Thin Edge: Lightweight devices send data to the cloud for processing. It's cost-effective and scalable but relies heavily on stable network connections.
- Thick Edge: Powerful local devices process data independently, reducing latency. Ideal for time-sensitive tasks but comes with higher costs and complexity.
- Hybrid Edge: Combines local processing for critical tasks with cloud management. Balances performance and resilience but requires careful coordination.
- Hyperconverged Edge: Integrates compute, storage, and networking into unified systems. Offers strong fault tolerance and scalability but needs specialised hardware.
- Cloud-Adapted Edge: Focuses on reducing latency by handling tasks locally while leveraging the cloud for management. Cuts costs but demands precise workload distribution.
Quick Comparison
| Pattern | Scalability | Fault Tolerance | Latency | Cost | Complexity |
|---|---|---|---|---|---|
| Thin Edge | High | Low | High | Low | Low |
| Thick Edge | Moderate | High | Low | High | High |
| Hybrid Edge | High | High | Low | Moderate | Very High |
| Hyperconverged | High | High | Low | Moderate | Moderate |
| Cloud-Adapted | Very High | Moderate | Low | Low | Moderate |
The choice depends on your needs for latency, resilience, and budget. For instance, Thin Edge works well in large-scale sensor networks, while Thick Edge suits critical systems like robotics. Hybrid and Hyperconverged approaches shine in mixed environments, and Cloud-Adapted systems excel in cost-sensitive, latency-critical applications. Always plan for physical redundancy at the edge, as hardware failures can't be automatically fixed like in the cloud.
::: @figure 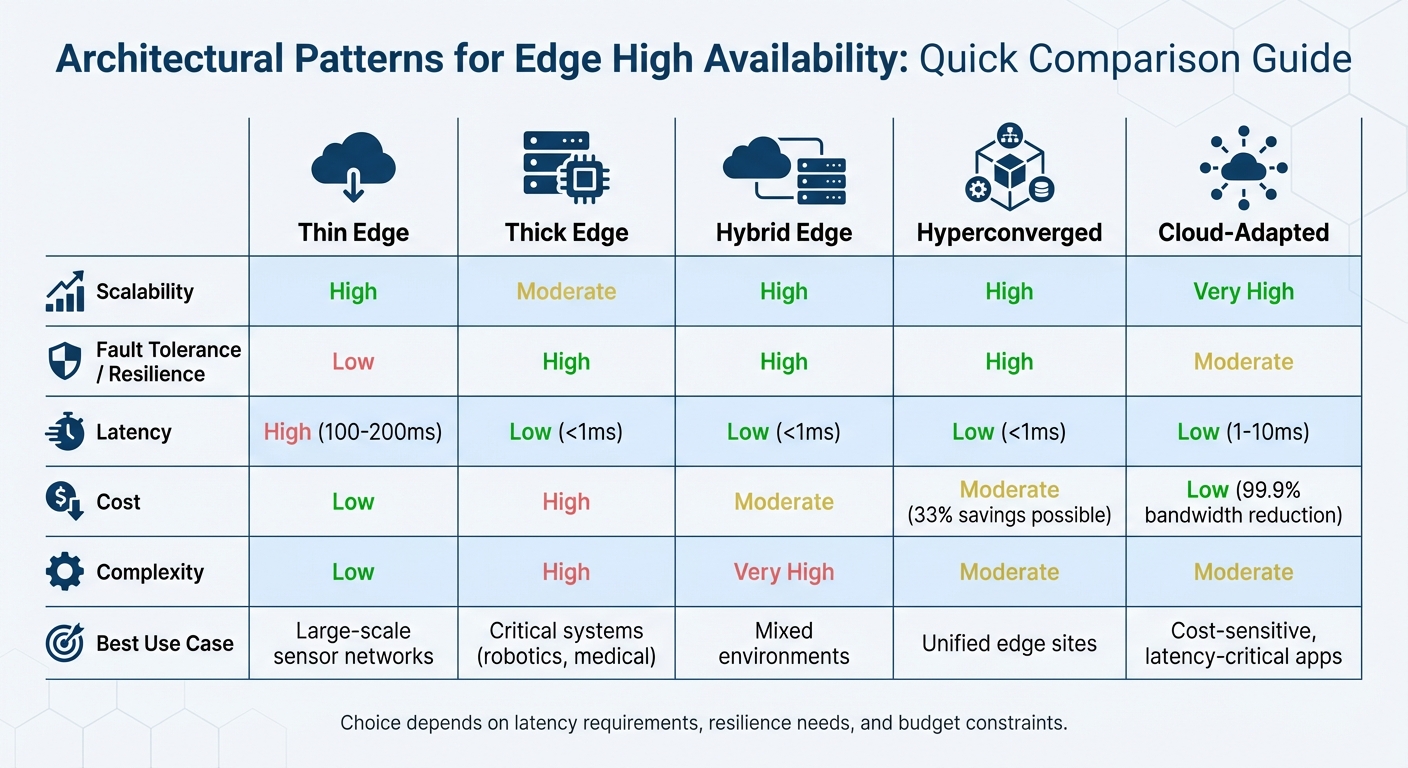 {Edge Computing Architecture Patterns Comparison: Scalability, Latency, Cost and Complexity}
:::
{Edge Computing Architecture Patterns Comparison: Scalability, Latency, Cost and Complexity}
:::
Edge Computing at the Extreme Edge: Hardware, AI, and High Availability with SNUCs Ed Barkhuysen
1. Thin Edge Architecture
Thin Edge Architecture relies on edge devices acting as basic sensors or transmitters, with all major processing, analytics, and decision-making handled by a centralised cloud system. These devices run minimal software and often use lightweight protocols like MQTT, CoAP, or LoRaWAN. As Chuck Durham, President and CTO at Seisan, succinctly states:
Thin Edge offers simplicity and scale [4].
This approach is ideal for large-scale sensor networks - such as utility metres, agricultural sensors, or environmental monitors - where stable cloud connectivity and latency in the range of hundreds of milliseconds are acceptable. By using simple microcontrollers like ESP32 or STM32, hardware costs stay low, and the devices benefit from low power consumption, enabling multi-year battery life. Below is a breakdown of its performance in key areas: fault tolerance, latency, cost, scalability, and complexity.
Fault Tolerance
Fault tolerance in Thin Edge is achieved by relying on standby hardware and cloud-based configuration management. Since the device’s intelligence
resides in the cloud, replacing a faulty unit is straightforward. A new device can be deployed and automatically retrieve its configuration from the central system. Kevin Saye, an Azure IoT Edge Specialist, notes:
Lowering the recovery time often increases the cost or complexity of most any solution [6].
However, the architecture's heavy dependence on constant network connectivity is a potential weak point. Advanced solutions like KubeEdge mitigate this by locally caching metadata - using tools like SQLite - so devices can continue operating during brief network outages, syncing with the cloud when connectivity resumes [7].
Latency
Since Thin Edge requires a round-trip to the cloud for processing, latency is higher compared to architectures with local processing. This makes it unsuitable for applications that demand near-instantaneous responses, such as autonomous vehicles or industrial robotics, where delays of even milliseconds can be critical.
Cost
The architecture shines in keeping capital costs low. With inexpensive hardware and extended battery life, Thin Edge is an economical choice for large-scale deployments.
Scalability
Thin Edge scales effortlessly across vast geographic regions. By centralising logic and decision-making in the cloud rather than distributing it across thousands of devices, it simplifies management and reduces operational overhead.
Complexity
On the device side, complexity is kept to a minimum. Lightweight communication protocols and simple firmware reduce the risk of local failures. However, this simplicity at the edge comes at the cost of requiring a robust and reliable cloud infrastructure to maintain consistent system availability.
2. Thick Edge Architecture
Thick Edge Architecture brings powerful computing capabilities directly to the edge, enabling devices to perform advanced tasks locally without relying on the cloud. These devices often employ high-performance CPUs, GPUs, or NPUs to handle complex workloads. Chuck Durham, President and CTO at Seisan Consulting, summarises its purpose succinctly:
Thick Edge offers autonomy and performance [4].
This setup is ideal for scenarios where local autonomy is crucial, such as power grid management, emergency response robotics, or medical diagnostic tools that need to operate reliably even without network access [4]. By processing data on-site, these systems remain functional during cloud outages, maintaining resilience. Like Thin Edge, Thick Edge is evaluated based on fault tolerance, latency, cost, scalability, and complexity. The localised processing not only boosts performance but also reshapes how fault tolerance is addressed.
Fault Tolerance
The strength of Thick Edge lies in its ability to function independently of cloud connectivity, ensuring uninterrupted operation during network failures [4]. For mission-critical systems, this autonomy is invaluable. However, achieving fault tolerance at the edge requires physical redundancy, such as backup cameras, extra power generators, or spare gateways [1]. Unlike cloud systems, where virtual machines can be deployed quickly, edge systems demand meticulous planning for on-site redundancy to maintain continuous service.
Latency
Thick Edge significantly reduces latency by cutting out the need for data to travel to and from the cloud. Decisions are made directly on the device or at a nearby gateway, making it perfect for applications where every millisecond counts - think industrial robots, autonomous vehicles, or real-time video analytics [4]. This immediate responsiveness ensures time-sensitive operations can run smoothly.
Cost
Localised processing comes with a higher price tag. The need for powerful processors, ruggedised hardware, and systems to manage power and cooling at multiple sites drives up capital expenditure [4][8]. Additionally, software licensing, often charged per CPU or node, adds to the costs as the number of devices increases [8].
One way to manage expenses is by shifting from traditional three-node high-availability clusters to two-node setups using raftless
key-value stores. This adjustment can lower hardware and licensing costs by 33% while maintaining resilience [8][9]. Another advantage is reduced bandwidth costs, as data is processed locally and only summarised insights or alerts are sent to the cloud, avoiding the need to stream raw data continuously [4].
Scalability
Scaling Thick Edge systems introduces unique hurdles. Managing thousands of smart devices requires efficient orchestration for tasks like software updates, security patches, and configuration changes across numerous sites [4]. Tools like lightweight Kubernetes distributions (e.g., K3s or MicroK8s) help manage these containerised workloads, while centralised cloud-based management platforms provide oversight [4][5]. However, the higher hardware costs mean scaling to large numbers of nodes demands careful financial planning compared to the simpler Thin Edge model [4]. A well-planned strategy ensures consistent performance as deployments grow.
Complexity
Thick Edge setups are inherently more complex to operate. Each device requires advanced orchestration, secure boot processes, local machine learning capabilities, and strategies for synchronising data [4][5]. Physical maintenance, hardware replacements, and on-site management across distributed locations add to this complexity. Skilled personnel and thorough planning are essential to ensure the infrastructure remains reliable and efficient, even as operational demands increase.
3. Hybrid Edge Architecture
The Hybrid Edge Architecture combines the strengths of both Thin and Thick Edge models, offering a blend of local responsiveness and centralised management. This approach splits responsibilities: critical tasks are processed locally, while the cloud handles management, persistent storage, and more resource-intensive operations [5]. At its core, this model ensures self-sufficiency, allowing systems to continue functioning even during internet outages, as the cloud connection is used primarily for management, not real-time transactions. As Google Cloud explains:
In an edge hybrid architecture, the internet link is a noncritical component that is used for management purposes... but isn't involved in time or business-critical transactions [5].
This architecture builds on the benefits of Thick Edge by maintaining local autonomy while leveraging the scalability of cloud resources.
Fault Tolerance
One of the standout features of the Hybrid Edge model is its ability to maintain operations even when cloud connectivity is disrupted. Critical workloads continue to run locally, ensuring uninterrupted functionality [5]. Fault tolerance can be enhanced through on-site backup systems, such as clustering, multi-node Kubernetes setups, or custom leader election mechanisms [6]. However, the success of this model depends on reducing dependencies between edge systems and the cloud, as each additional dependency can weaken overall reliability [5].
Latency
With local decision-making handled at the edge, latency is kept to a minimum. Time-sensitive actions happen on-site, avoiding the delays caused by round-trips to distant data centres [10]. Meanwhile, heavier computational tasks are shifted to regional or cloud resources. Adaptive caching strategies further improve response times by dynamically adjusting time-to-live (TTL) settings [10].
Cost
The Hybrid Edge model also seeks to balance costs by distributing workloads effectively. Expensive compute and storage tasks are offloaded to the cloud, particularly for bursty workloads and long-term data retention, while edge nodes manage immediate processing needs [10]. However, this setup does come with added expenses. Maintaining physical redundancy across multiple edge locations increases capital expenditure, and centralised management platforms often require additional licensing fees [5].
Scalability
Scaling the Hybrid Edge model requires seamless orchestration across distributed sites. Tools like Kubernetes or containerised workloads help abstract differences between edge and cloud environments, ensuring consistent operations [5]. A centralised cloud-based management plane provides oversight for monitoring, CI/CD pipelines, and security enforcement across all locations [5]. API gateways can act as a bridge between legacy systems and modern services, creating a unified operational layer [5]. The main challenge lies in coordinating updates and configurations across numerous physical sites while preserving local autonomy for critical tasks.
Complexity
While the Hybrid Edge model offers numerous advantages, it does introduce significant complexity. Teams must manage a dual environment that includes both physical edge systems and cloud-based infrastructure. This requires consistent CI/CD pipelines, unified identity management, and reliable data synchronisation across all environments [5]. Skilled personnel and robust automation are essential to ensure smooth operations. Additionally, determining which workloads should run locally versus in the cloud, and maintaining security policies across multiple sites, adds another layer of operational difficulty.
4. Hyperconverged Edge Architecture
Hyperconverged Infrastructure (HCI) combines compute, storage, and networking into a single software-driven system, making it perfect for edge environments where space is tight and IT expertise is limited [14]. Instead of using separate servers for different tasks, HCI nodes work together as a unified cluster, pooling resources efficiently. This design fits well with the overall goal of improving edge architectures for high availability.
HCI takes RAID concepts to the next level by applying them across multiple servers, a method known as Redundant Array of Independent Nodes (RAIN). This setup protects data not just from individual disk failures but also from complete node outages [11][12]. As Luke Pruen, HPE Hyperconverged Lead, puts it:
The powerful combination of RAID + RAIN allows HPE SimpliVity to lose disks in multiple nodes, experience a subsequent node failure, and still continue to provide data services for the VMs [12].
This distributed design ensures that if one node goes down, virtual machines automatically restart on the remaining nodes, keeping operations running smoothly without the need for manual intervention [11][12].
Fault Tolerance
HCI platforms are built with self-healing capabilities to maintain application availability. When a node fails, the system quickly redistributes workloads across the remaining nodes [11][12]. A three-node cluster provides enhanced fault tolerance, ensuring full data redundancy even if one node is offline. This approach is more resilient than traditional server pairs, which become vulnerable once the primary server fails [11]. Scale Computing highlights this autonomous functionality:
Scale Computing Platform architecture has been designed first and foremost to provide an autonomous IT infrastructure that ensures your applications keep running with little intervention, even as hardware components fail [11].
Latency
HCI also excels at low-latency operations by consolidating core functions locally. By keeping compute and storage at the edge, HCI ensures performance remains unaffected by remote network connectivity [11]. This is especially important for real-time applications like AI/ML inference and industrial automation [14]. Features such as inline deduplication and compression further improve performance by reducing write operations, cutting storage latency, and extending the lifespan of SSDs [12].
Cost
Traditional server setups often require significant upfront investment due to idle resources in active/passive configurations, leading to 100–120% higher capital expenditure [13]. HCI avoids this inefficiency by optimising resource use, allowing organisations to scale incrementally by adding nodes as needed, eliminating costly forklift upgrades
[13][14]. Operational costs for power, cooling, and maintenance can also drop by up to 50% compared to conventional setups [13]. However, some HCI software solutions demand high RAM and CPU resources, which may necessitate more substantial hardware investments to maintain performance [13].
Scalability
HCI’s modular approach makes it easy to expand by adding individual nodes as workload demands grow [13][14]. This scalability is driving industry adoption, with HCI edge deployments growing at a compound annual rate of 10.8%. Additionally, 67% of enterprises are increasing their investments in edge environments, with an average spending boost of 37% [14]. Gartner reports that over 75% of enterprise-generated data is now created and processed outside centralised infrastructures [14].
Complexity
While HCI simplifies traditional three-tier architectures, managing multiple distributed sites can still present challenges [11][14]. Modern HCI platforms address this with single-pane-of-glass
interfaces and policy-based orchestration, enabling remote deployment and monitoring without sending personnel on-site [14]. Features like automated virtual machine live migration allow for one-click
updates across clusters, ensuring maintenance doesn’t disrupt operations [11]. However, two-node clusters can be tricky, as they require specialised solutions to handle split-brain
scenarios where nodes disagree, often needing external tiebreakers or agents [8][9]. As Justin Barksdale, Principal Architect at Spectro Cloud, explains:
The industry consensus recommends a minimum of three nodes to ensure fault tolerance and create a baseline HA architecture [8].
In practice, automated failovers in HCI systems can happen in under 30 seconds, showcasing the reliability and maturity of these self-repairing systems [14]. This balance of modularity and ease of management ensures smooth integration across distributed edge environments.
5. Cloud-Adapted Edge Architecture
Cloud-adapted edge architecture is all about striking the right balance between local and cloud-based operations. It handles time-sensitive tasks locally to reduce delays while relying on the cloud for management and synchronisation. This setup can significantly improve performance and cut costs, but it requires thoughtful design to ensure the benefits of edge computing, especially latency, aren't lost [5].
Fault Tolerance
In cloud-adapted systems, fault tolerance is managed through techniques like circuit breakers, bulkheads, and timeouts. These methods work together to isolate problems and prevent them from escalating. Circuit breakers, for instance, monitor services and stop requests to those struggling, reducing the risk of widespread failures. Bulkheads keep resources separated, so a surge in one area doesn't drain resources from others. Timeouts ensure that services don't hang indefinitely when dependent systems slow down. This distributed approach means that even if edge hardware fails or the cloud connection falters, availability is maintained.
Latency
Latency is a key focus in cloud-adapted architectures, with efforts aimed at minimising reliance on the cloud. Keeping operations within edge platforms can limit latency to under 1 millisecond, while tasks requiring cross-continental cloud calls might face delays of 100–200 milliseconds [2]. As emphasised by a practitioner:
In 2026 the performance delta between cloud-centred inference and edge-deployed models is the difference between a failed user experience and a successful one in real-time features
– Midways.Cloud, 2026 [15]. To manage this, teams use latency budgeting, breaking down requests into smaller parts and setting measurable thresholds for each [15].
Cost
Cost savings are a major advantage of cloud-adapted architectures. By processing data locally and sending only essential metadata to the cloud, organisations can cut bandwidth usage by an impressive 99.9% [16]. For example, in visual inspection scenarios involving 50 cameras, the first-year costs drop from £300,000 with cloud-native setups to just £56,600 using edge or hybrid models [16]. As noted:
The combination of Egress Fees, Storage Costs, and Latency Penalties has made 'Cloud-Native' prohibitively expensive for video analytics and real-time inference
– Cloudatler [16]. Hardware like NVIDIA Jetson Orin offers server-grade performance for under £1,000, enabling a return on investment in as little as three months for high-data-use applications [16]. This approach makes it easier to scale workloads without breaking the bank.
Scalability
Cloud-adapted models excel at scaling by efficiently distributing workloads across edge nodes while reserving the cloud for less time-sensitive tasks. A tiered approach, such as the split-plane model, uses an edge control-plane for real-time routing, a regional data-plane for demanding tasks like video processing, and the cloud core for long-term storage [10]. This design allows organisations to scale edge capacity incrementally without overloading the cloud. With 97% of CIOs expected to have deployed or be planning to deploy edge AI by 2025, and with local hardware reducing inference costs by 30–40%, scalability is a driving force behind the growing adoption of this architecture [17].
Complexity
Managing cloud-adapted systems brings its own set of challenges. Teams must carefully define which tasks stay local and which go to the cloud, as poorly managed dependencies can hurt performance [5]. Modern platforms help by using service bindings that avoid delays caused by public internet routing, DNS lookups, and TLS handshakes [2]. Dynamic edge caching, which adjusts TTLs based on traffic patterns and error rates, reduces buffering without requiring manual adjustments [10]. Additionally, federated observability tools simplify monitoring by providing insights into latency across millions of endpoints, making it easier to manage distributed systems [15].
Advantages and Disadvantages
After examining fault tolerance, latency, cost, scalability, and complexity in various architectures, let’s break down their pros and cons.
Each architectural pattern comes with its own set of strengths and challenges, particularly in areas like scalability, resilience, and management complexity. Thin Edge architectures are appealing for their low hardware costs and straightforward deployment. However, their reliance on the cloud can lead to latency issues and reliability concerns [4][18]. On the other hand, Thick Edge patterns provide ultra-low latency and local autonomy by relying on robust on-site compute resources. The downside? These benefits come with higher hardware expenses and increased management complexity [4][18].
Hybrid Edge architectures aim to strike a balance by running critical tasks locally while offloading less important workloads to the cloud. This setup offers excellent resilience and cost-effective data synchronisation but introduces a significant level of complexity in managing the split between local and cloud environments [4][5][18]. Meanwhile, Cloud-Adapted patterns use serverless technologies and containerisation to achieve high scalability and flexibility. However, they rely heavily on modern infrastructure and a skilled workforce [2][18]. Lastly, Hyperconverged Edge architectures integrate compute, storage, and networking to optimise resource use, potentially cutting costs by up to 33% [8]. The trade-off lies in the need for specialised hardware integration.
The right pattern isn't the cleverest or most elegant; it's the one that makes your system boring. Predictable. Understandable. Debuggable by someone at 3am who's never seen the code.
– Architecting on Cloudflare [2]
Here’s a quick comparison to summarise the key points:
| Architectural Pattern | Scalability | Resilience | Management Complexity | Key Advantage | Main Drawback |
|---|---|---|---|---|---|
| Thin Edge | High | Low | Low | Low hardware cost | Cloud-dependent; higher latency |
| Thick Edge | Moderate | High | High | Local autonomy; ultra-low latency [4] | High hardware cost; complex local management [4] |
| Hybrid Edge | High | High | Very High | Balanced performance; cost-efficient synchronisation [18] | Complex synchronisation and management [18] |
| Hyperconverged | High | High | Moderate | 33% cost savings via 2-node clusters [8] | Requires specialised hardware integration |
| Cloud-Adapted | Very High | Moderate | Moderate | Seamless agility; uses cloud-native tools [18] | Dependent on modern stack/skills [2] |
Choosing the right architecture depends on your specific needs for latency, cost, and resilience. For example, if your system involves a strict latency requirement, it’s essential to consider the delays inherent in different setups. A Durable Object call, for instance, adds 5–10ms within the same region but can stretch to 100–200ms across continents [2]. Unlike virtualised redundancy in data centres, edge environments often require physical backup devices - like secondary cameras or generators - since edge assets exist in physical locations [1]. For mission-critical operations, such as power grids or medical devices, Thick Edge patterns ensure uninterrupted functionality, even if the network goes down [4].
Implementation Factors and Professional Support
Achieving high availability at the edge requires more than just selecting the right architectural pattern - it demands a unified and strategic implementation approach. Virtualisation plays a key role by abstracting hardware differences across various edge locations. This allows workloads to run consistently, regardless of the underlying infrastructure. Lightweight containers or hypervisors are particularly useful here, enabling multiple instances to operate on limited edge hardware. This setup not only provides redundancy but also simplifies failover when individual nodes fail [20]. Unlike the cloud, where resources are virtually limitless, edge deployments must carefully schedule replicas based on the constraints of fixed physical hosts [20].
Dynamic service migration is another critical factor, ensuring workloads can adapt seamlessly in the event of failures. For instance, Kubernetes enables service migration by evicting and rescheduling pods, facilitating smooth edge-to-cloud failover. This approach has proven to reduce operating costs in IoT projects by 30–50%, primarily through lower data transfer fees [5]. Additionally, content caching at the edge further reduces the need for migration by minimising backhaul data transfer. This leverages the edge's latency advantage, which typically ranges from 5–10 milliseconds compared to the cloud's 30–60 milliseconds [21].
Orchestration tools are indispensable for managing deployment, scaling, and failover across distributed systems. Kubernetes, combined with distributed control planes, simplifies workload movement and load balancing. Centralised dashboards further enhance this process, enabling remote provisioning even during network disruptions [5][19]. However, challenges like intermittent connectivity and diverse infrastructure often require streamlined network patterns instead of overly complicated software-defined solutions.
To make these implementations even more efficient, professional expertise is often necessary. Hokstad Consulting, for example, offers services that optimise DevOps transformations and automate edge deployments. Their solutions improve remote CI/CD pipelines, cutting mean time to recovery by up to 60%. They also specialise in hybrid configurations, allowing seamless failover between edge and cloud environments. By focusing on cost engineering, they help reduce expenses through efficient resource allocation - an essential consideration when dealing with fixed physical infrastructure. While edge hardware investments are typically around 10% higher than centralised setups, these costs are offset by the performance benefits [20].
In addition to technical strategies, mission-critical deployments should prioritise automatic failover to ensure workloads can shift instantly without manual intervention. Centralised management is vital for monitoring multiple edge devices remotely, while integrated security measures, such as network segmentation and zero-trust architectures, safeguard operations. Geographic distribution across multiple sites enhances resilience against localised outages, and continuous monitoring with alerts helps identify and address potential issues before they escalate into major failures.
Conclusion
When choosing an edge high availability pattern, it's all about aligning your decision with your specific needs and limitations. Thin edge architectures are ideal for situations with limited bandwidth and a preference for centralised control. On the other hand, thick edge patterns shine in scenarios where local autonomy and reduced reliance on the cloud are priorities. For organisations needing a mix of both, hybrid approaches provide a middle ground, while hyperconverged architectures simplify management by unifying multiple edge sites under consistent infrastructure.
To make the right choice, focus on three key factors: your availability Service Level Objectives (SLO), budget constraints, and the technical complexity involved [3]. Don’t forget to set a clear latency budget - real-time applications might require sub-100ms response times, whereas others can handle up to 2 seconds [2]. For mobile apps running on constrained networks, implementing an edge-based Backend for Frontend (BFF) can dramatically reduce latency, cutting it down from 720ms to 200ms by handling backend calls locally [2].
Unlike traditional data centres, edge deployments come with unique physical challenges. As Bob Reselman from mimik puts it:
When it comes to edge architectures, the devil is in the device. The takeaway is simple: have a physical backup on hand[1].
This highlights the importance of physical redundancy for edge devices, as software alone cannot fix hardware failures [1].
For organisations seeking expert help with edge deployments, Hokstad Consulting offers valuable support. Their expertise in DevOps transformation and hybrid configurations ensures smooth failover between edge and cloud environments. They also specialise in cost engineering, optimising resource allocation across distributed setups. This approach helps keep your edge deployment resilient and cost-effective.
FAQs
How do I choose the right edge HA pattern for my latency and availability SLOs?
To choose the right edge high availability (HA) pattern, think about your latency needs and how critical availability is for your system. If minimising downtime is a priority, active-active architectures are a strong option. They share workloads across multiple sites, allowing for quick failover. On the other hand, simpler setups like active-passive might work, but they often come with slower failover times. The key is to balance operational complexity, resource limits, and performance goals to create an architecture that aligns with your Service Level Objectives (SLOs) while remaining manageable and reliable.
What physical redundancy do I actually need at edge sites?
The level of physical redundancy needed at edge sites largely hinges on how critical the applications are and the specific operating conditions. Hardware redundancy plays a vital role here - using multiple edge devices can help maintain system reliability by eliminating single points of failure. On top of that, having backup power sources, such as UPS systems or generators, is essential, especially in regions where power outages are common. To ensure your setup aligns with operational requirements, match your redundancy measures to your system’s Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
How can I run edge HA with only two nodes without split-brain risk?
To ensure edge high availability (HA) with two nodes while avoiding the risk of a split-brain scenario, a leader-follower setup is the way to go. In this model, one node actively handles write operations, while the other remains in standby mode. Failover is controlled through health checks, ensuring a smooth transition if needed.
By relying on external storage solutions like Postgres rather than etcd, you eliminate the need for quorum. This simplifies the process and allows for seamless failover. If one node fails, the system promotes the standby node to leader status based on liveness probes, ensuring uninterrupted service.