
AI is reshaping disaster recovery for pipelines by enabling systems to detect issues early, automate responses, and reduce downtime. While traditional methods rely on manual intervention and static plans, AI-driven solutions use predictive analytics, anomaly detection, and automated recovery processes to minimise disruptions and costs. However, challenges like data quality, false positives, and over-reliance on AI highlight the need for balanced human oversight.
Key Points:
- AI predicts failures with over 90% accuracy, reducing detection times from days to minutes.
- Automated recovery resolves up to 90% of common issues autonomously.
- Cost savings include up to 22% reduction in operational expenses and improved asset performance.
- Risks involve AI's difficulty handling rare incidents, reliance on accurate data, and potential erosion of human expertise.
The best approach combines AI's capabilities with human judgement to ensure effective and reliable disaster recovery.
::: @figure 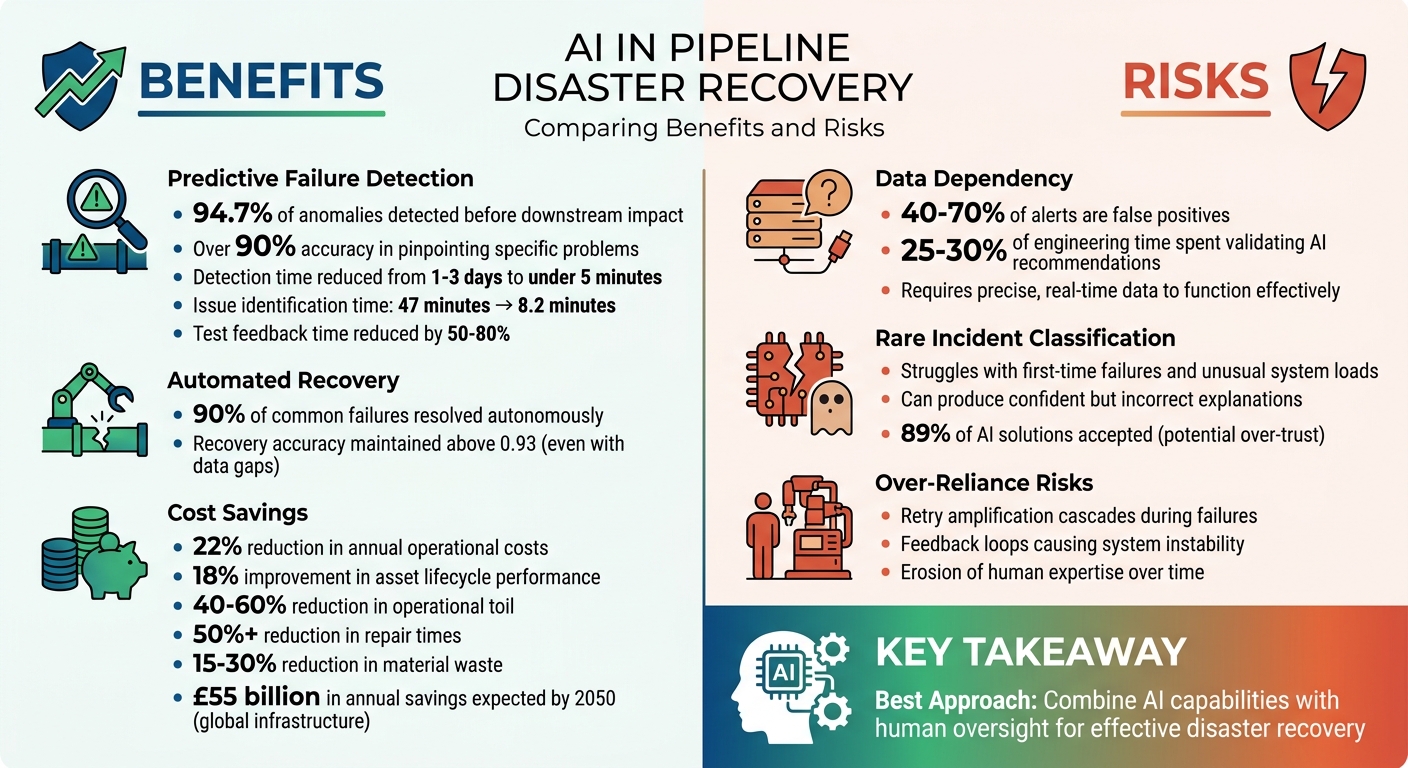 {AI in Pipeline Disaster Recovery: Key Benefits and Risks Comparison}
:::
{AI in Pipeline Disaster Recovery: Key Benefits and Risks Comparison}
:::
AWS re:Invent 2025 - AI-powered resilience testing and disaster recovery (COP420)
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Benefits of AI in Pipeline Disaster Recovery
AI is reshaping how delivery pipelines handle failures, moving away from static, manual processes to systems that can learn and respond autonomously. Through concepts like the SAPAL loop - Sense, Analyse, Predict, Act, Learn - pipelines can anticipate potential issues, act with precision, and continuously improve their responses based on past experiences [1].
Predictive Failure Detection
One of the standout capabilities of AI is its ability to identify failures before they escalate. With robust observability, AI-driven systems can detect 94.7% of anomalies before they impact downstream operations, achieving over 90% accuracy in pinpointing specific problems [3]. This shift from reactive monitoring to proactive detection means teams can address issues early, avoiding the chaos of post-failure fixes.
Traditional methods often take one to three days to detect anomalies. In contrast, AI systems can reduce detection times to under five minutes [4]. For instance, a system enhanced with AI-based tracing cut the average time to identify issues from 47 minutes to just 8.2 minutes [3]. Additionally, machine learning techniques for test selection have been shown to reduce feedback times by 50–80% [1]. This proactive approach not only speeds up detection but also sets the stage for automated resolutions.
Automated Recovery Processes
AI doesn't stop at detection - it also drives recovery. Modern self-healing pipelines can autonomously resolve up to 90% of common failures without human involvement [3]. Even in cases of sensor failures or data gaps, advanced models like PDO-BiGRU-GAN maintain recovery accuracy above 0.93, ensuring uninterrupted structural health monitoring [6].
Dynamic updates to runbooks further enhance recovery. AI continuously tracks changes in infrastructure, migrations, and application dependencies, ensuring disaster recovery procedures remain up-to-date [2]. By storing remediation logic in version-controlled YAML or JSON files, site reliability engineers can easily review and refine automated actions [3]. This streamlined process reduces recovery times, cutting costs and minimising risks along the way.
Cost Savings and Risk Reduction
The financial impact of AI-driven recovery solutions is immense. For example, a global oil and gas company used an AI-powered Integrity Management System across 150,000 miles of pipeline. By employing drone imagery and real-time telemetry to detect corrosion, they reduced annual operational costs by 22% and improved asset lifecycle performance by 18% [4].
Real-time visibility and predictive insight have shifted our maintenance culture from reactive firefighting to proactive optimisation. This is the future of industrial asset management.
– Linzy Sherin, Founder, Aligned Automation [4]
AI also reduces repetitive troubleshooting tasks - known as operational toil - by 40–60% [7]. Post-disaster inspection tools can slash repair times by over 50% while cutting material waste by 15–30% [5]. Looking ahead, AI-enabled infrastructure is expected to prevent approximately 15% of global infrastructure losses from natural disasters, equating to roughly £55 billion in annual savings by 2050 [5]. Transitioning from time-based to condition-based maintenance strategies further enhances asset durability while lowering overall costs [4].
These advancements illustrate how AI is revolutionising pipeline management, delivering faster recovery and greater resilience. However, while these benefits are impressive, it’s just as important to consider the risks that come with these technologies.
Risks and Challenges of AI in Pipeline Disaster Recovery
While AI offers promising tools for disaster recovery, it also introduces risks that can weaken operational resilience. These risks often arise from the way AI systems process data and make decisions, particularly in high-pressure situations.
Data Dependency and Accuracy
AI systems rely on precise, real-time data to function effectively. When the data is incomplete or contains errors, the system's accuracy drops significantly. Interestingly, organisations that have adopted AI-driven incident response have reported an increase in operational workload - from 25% to 30% of engineering time. This is largely due to the need for engineers to validate AI recommendations before taking action, adding a verification layer
to their processes [10].
Every day, engineers are inundated with thousands of alerts, with 40–70% of these being false positives [10]. This flood of information makes it harder to identify the genuinely useful insights from the noise. Such data challenges also make it difficult for AI to recognise and respond to entirely new types of incidents.
Rare Incident Classification
AI models are great at spotting patterns in historical data, but they falter when faced with situations they've never encountered before. First-time failures, unusual system loads, or unexpected third-party issues often fall outside the scope of the model's training, leading to errors. Large language models (LLMs), in particular, can produce confident-sounding explanations even when they're uncertain or wrong [8][9][10].
Useful AI handles assembly. Dangerous AI handles judgment– Devrim Ozcay, software engineer [9]
A case in point is Meta's misdiagnosis of an NCCL error, which highlights the difficulty AI has with classifying new issues [10].
The fluency of a response correlates with how well the model was trained on similar text, not with whether the answer is correct for your specific infrastructure– Tian Pan, engineer-founder [10]
Interestingly, engineers accept 89% of AI-proposed solutions, which shows a growing reliance on AI. However, this also raises concerns about whether these suggestions are being scrutinised thoroughly enough [8].
These limitations point to the dangers of depending too heavily on AI for critical decision-making.
Over-Reliance on AI in Critical Decisions
Relying too much on AI during emergencies can lead to risky failure modes. For instance, retry amplification cascades
occur when AI systems trigger repeated retries during failures, causing overloaded systems to spiral further out of control [10]. Another issue is the feedback loop, where AI systems interpret their own previous actions - such as rerouting traffic - as new data, leading to instability or flapping
[11].
Microsoft's Azure SRE Agent, which has handled over 35,000 incidents across more than 1,300 internal agents as of April 2026, mitigates these risks through a bounded autonomy
approach. This model allows AI to diagnose issues independently but requires human approval for any action that could alter production systems [8].
Perhaps the most concerning risk is the erosion of human expertise. When teams become overly reliant on AI, they may lose the skills needed to manage complex situations without it, creating a dangerous dependency [11].
Maintaining a balance between automation and human oversight is critical for building resilient recovery processes.
Comparing Failure Modes: Traditional Automation vs AI-Driven Recovery
| Feature | Traditional Automation | AI-Driven Recovery |
|---|---|---|
| Failure Mode | Stops after a single failure (deterministic) | May continue retrying due to reasoning(stochastic) [10] |
| Risk | Errors in scripts | Misleading outputs and inability to handle new patterns [8][10] |
| Human Role | Follows predefined runbooks | Validates AI-generated recommendations [10] |
AI Techniques Used in Pipeline Disaster Recovery
AI plays a crucial role in disaster recovery for pipelines, relying on three main techniques. These methods work together to detect issues early, analyse sensor data in real-time, and automate recovery tasks.
Machine Learning for Anomaly Detection
Machine learning algorithms continuously monitor telemetry data - metrics, logs, and traces - to spot unusual patterns before they escalate into failures. Online anomaly detectors, like Half-Space Trees, process this data in real-time and generate structured anomaly events when scores exceed a specific threshold [3]. A classification layer, powered by Large Language Models, categorises these events (e.g., OOM kills, crash loops, or network issues) and determines whether automated remediation is safe [12].
This approach can achieve over 90% precision in identifying pipeline issues. It also enables the detection of 94.7% of anomalies before they impact downstream systems, thanks to robust observability [3]. Modern monitoring tools can handle up to 1.2 million metric evaluations per minute, with alerting latencies under 10 milliseconds [3]. By combining various anomaly detection methods - such as schema monitoring and time-series baselines - false positives can be reduced by 79.3% [3].
A self-healing data pipeline is a pipeline that can detect, diagnose, and remediate many classes of failures autonomously, using rich telemetry, ML-based anomaly detection, and orchestrated recovery flows.– Debanjan Dey [3]
To avoid overreacting to transient issues, wait for a minimum number of events (e.g., count ≥ 3) before initiating a deeper investigation [12]. For autonomous actions, set a high confidence threshold (e.g., 0.90); anything below this level should be deferred for human review [12].
Building on these detection methods, real-time sensor analysis sharpens pipeline monitoring by interpreting continuous physical data streams.
Real-Time Sensor Analysis
Real-time sensor analysis ensures constant monitoring of a pipeline's structural health, identifying early risk indicators that manual inspections might miss [6]. AI processes data from sources like fibre-optic sensors, acoustic detectors, and pressure monitors to establish normal behaviour baselines and flag deviations [6][14].
A collaboration between the British Pipeline Agency and Klarian demonstrated that combining physics-based insights with machine learning enhances anomaly detection in pipelines [14].
Machine-learning in isolation is no replacement for engineering and physics expertise, so delivering physics-based insights overlaid with machine-machine learning is the best and most practical approach.– Klarian / British Pipeline Agency [14]
Advanced deep learning models, such as PDO-BiGRU-GAN, can recover missing monitoring data with an accuracy (R²) consistently above 0.93 [6]. Fibre-optic systems are particularly effective for long-distance, continuous monitoring, offering high sensitivity at a lower cost compared to traditional electrical sensors [6].
While sensor analysis highlights risks in real-time, agentic AI systems act on these insights to automate recovery processes.
Agentic AI for Automated Remediation
Agentic AI systems use event-driven architectures to execute immediate, autonomous recovery actions when failures are detected [16][17][19]. These systems often deploy specialised agents for different tasks: a Diagnoser analyses logs and suggests solutions, a Validator checks proposed fixes for safety and compliance, and a Remediator implements approved fixes with rollback protection [16][18].
In March 2026, Western Governor's University's SRE team used the AWS DevOps Agent to address a production service disruption. By integrating the agent with Dynatrace, they reduced the resolution time from an estimated two hours to just 28 minutes - a 77% improvement in MTTR. The agent identified and resolved an undocumented AWS Lambda configuration error [19].
If \[agents\] can't recover from errors on their own, you've lost half the value of using agents in the first place.– Antigravity Lab [15]
To enhance safety, include a classification step to categorise the failure (e.g., OOM kill or configuration error) before initiating remediation. High-risk actions, like cordoning nodes or updating resource limits, should always require human approval, regardless of AI confidence [12]. Maintain an audit trail by logging every agent action, decision, and confidence rating in an immutable record to ensure traceability and reversibility [17][19].
Case Studies and Metrics from Research
These examples show how advancements in AI are delivering measurable benefits to pipeline resilience and operational efficiency.
Predictive Maintenance in Action
Shell teamed up with C3 AI and Microsoft Azure to monitor over 10,000 pieces of equipment worldwide. With an impressive 85–90% accuracy in predicting the remaining useful life of critical assets like valves and compressors, Shell achieved some major outcomes:
- 20% reduction in unplanned downtime
- 15–20% lower maintenance costs, saving an estimated £315 million annually
- Increased asset uptime from 93% to 98%
- A 15% drop in safety incidents caused by equipment failures [20][22][23].
Another notable example comes from a large energy company working with Aligned Automation. They implemented an AI-powered Integrity Management System across 241,000 kilometres of pipelines. This system slashed anomaly detection times from 1–3 days to under 5 minutes, enabling proactive disaster recovery instead of waiting for problems to escalate [4].
Failure Classification Success Rates
In June 2025, SuperAGI deployed an AI-driven monitoring system for a major oil and gas client. Using gradient boosting and random forest models trained on 12 years of data, the system achieved:
- Over 90% accuracy in predicting corrosion failures
- More than 80% accuracy in identifying equipment failures
These improvements led to 25% less downtime and 30% lower maintenance costs [21].
A study published in Frontiers in Artificial Intelligence in October 2025 introduced the PDO-BiGRU-GAN model, which excelled in recovering data with an R² exceeding 0.93, even when up to 20% of sensor data was missing [6]. Meanwhile, the Extra Trees algorithm demonstrated strong results with:
- An R² of 90.35% for predicting the timing of failures
- An F1 score of 85% for classifying failure intervals, leveraging climatic trends and historical incident data [24].
These findings not only showcase AI's predictive power but also emphasise the importance of careful integration to address potential challenges, as previously discussed.
Implications for DevOps Resilience
AI has become a cornerstone of a more proactive approach to DevOps practices. Research highlights how AI not only prevents failures but also fundamentally changes the way resilience is managed. This shift moves disaster recovery efforts towards proactive resilience, aligning perfectly with the principles of DevOps. Traditionally, DevOps has relied on automation, thorough monitoring, and quick feedback loops to ensure high availability and minimise downtime. AI takes these principles further by predicting potential failures, automating responses, and maintaining service continuity - even when parts of the infrastructure fail. This shift builds on earlier insights into AI's role in identifying and addressing disruptions before they escalate.
When integrated effectively, AI strengthens key DevOps functions. For example, intelligent alerting systems can filter out false positives, ensuring teams focus on real threats. Automated recovery processes can drastically cut mean time to recovery (MTTR) by executing predefined remediation actions. AI also enhances deployment strategies like blue-green deployments, canary releases, rolling updates, and feature flags. Imagine AI monitoring a canary deployment in real time: if it detects anomalies, it can automatically roll back changes. Or, it might predict which feature flags could cause resource conflicts before they are fully deployed. These capabilities help reduce risks associated with continuous delivery while maintaining the pace of deployments.
Hokstad Consulting demonstrates how AI can be seamlessly integrated into DevOps transformations. By combining automated CI/CD pipelines with AI-driven monitoring tools, they enable organisations to improve system reliability while cutting cloud costs by 30–50%. Their methods include predictive maintenance and intelligent recovery mechanisms, shifting teams from reacting to incidents to actively preventing them.
That said, human oversight remains essential. While AI excels in recognising patterns and responding quickly, some decisions - especially those involving customer-facing services or data integrity - still require human judgement. Organisations that use AI as a tool to augment their engineers’ expertise, rather than replace it, achieve the best results in terms of resilience and operational efficiency.
Conclusion
AI holds immense promise for pipeline disaster recovery, particularly in areas like predicting failures, automating recovery processes, and reducing costs. However, its success depends on acknowledging its limitations, such as reliance on data quality and limited training for rare, critical incidents[13].
The best results come from blending AI's predictive abilities with human oversight. This approach isn't just a suggestion but a reinforcement of the balanced strategy discussed earlier.
Successful implementation goes beyond technology alone. The 10/20/70 rule[25] highlights that 70% of success depends on people, organisational culture, and effective change management. To make the most of AI, organisations need to invest in training, create clear evaluation frameworks, and foster an environment where both automation and human judgement are valued.
Hokstad Consulting supports businesses in navigating these challenges with tailored AI-driven solutions. Their methods integrate automated CI/CD pipelines with intelligent monitoring tools, delivering measurable cost savings and stronger operational performance. By respecting both the strengths and limitations of AI, they help organisations develop practical disaster recovery strategies that are proactive and effective.
FAQs
What data do we need before using AI for pipeline disaster recovery?
To apply AI in pipeline disaster recovery, you'll need a solid foundation of data. This includes details about recovery objectives, system configurations, logs, metrics, and patterns of failures. With this information, AI can effectively simulate scenarios, monitor systems, and conduct automated testing. These capabilities ensure the recovery process is supported in a smooth and efficient manner.
How do we keep humans in control of AI-driven remediation?
To maintain human oversight in AI-driven remediation processes, it's crucial to use human-in-the-loop systems. These systems are designed to offer recommendations rather than taking independent actions. This way, operators can review and validate the AI's suggestions with all the necessary context before moving forward. This approach ensures that decisions remain secure, informed, and ultimately under human control.
What happens when AI encounters a rare or never-seen incident?
When AI encounters an unusual or entirely new situation, it has the capability to assess the scenario in real time, pinpoint potential risks, and initiate automated actions to stop problems from escalating. For instance, AI-powered systems have proven adept at spotting and addressing deployment risks early, preventing these from turning into major complications. This shows how AI can adjust and respond efficiently, even when facing unfamiliar challenges.