
AI is transforming DevOps by enabling automated, event-driven workflows that respond to real-time triggers. This approach eliminates manual processes and static schedules, replacing them with systems that predict and resolve issues before they escalate. Here’s what you need to know:
- Event-Driven Workflows: Automatically trigger actions based on system events like deployment completions or resource spikes.
- Predictive Capabilities: AI anticipates issues, such as resource shortages or test failures, using historical data and real-time telemetry.
- Real-Time Automation: AI agents handle tasks like scaling resources, detecting anomalies, and managing rollbacks without human intervention.
- Improved Metrics: Examples show reduced lead times (up to 25%), faster recovery (26% improvement), and lower error rates.
- Key Tools: Frameworks like LangChain, Microsoft AutoGen, and Dynatrace's Davis AI are driving this shift.
AI-driven DevOps workflows are becoming essential for faster deployments, reduced downtime, and optimised resource management. With tools and frameworks evolving rapidly, now is the time to explore these capabilities for your organisation.
Building AI Agents and Assistants for DevOps Workflows - Lee Faus - GitLab
AI-Powered Predictive Triggers
Predictive triggers are changing the game for how DevOps teams handle infrastructure. Instead of reacting to problems like CPU usage hitting 80% or memory running out, AI-driven systems predict issues before they happen. By analysing historical data and monitoring real-time telemetry - like logs, metrics, and traces - these systems can identify early indicators
of potential failures or resource shortages. This approach integrates seamlessly with modern CI/CD systems, making operations smoother and more efficient.
For example, in August 2025, a team led by Mohammad Baqar at Cisco Systems upgraded a React 19 frontend microservice, which supported 5,000 concurrent sessions, to an AI-enhanced pipeline. They used LLaMA 3-based agents alongside Argo Rollouts on Kubernetes. The result? Lead time decreased from 4.8 hours to 3.6 hours - a 25% improvement - and Mean Time to Recovery (MTTR) dropped from 65 minutes to 48 minutes. During canary phases, an AI Observability Agent detected Service Level Objective breaches, such as latency exceeding 200 milliseconds, and triggered rollbacks autonomously [3]. This example shows how predictive triggers bring real-time AI capabilities into DevOps workflows, improving both speed and reliability.
AI Models in CI/CD Pipelines
Today’s CI/CD pipelines rely on hybrid architectures that combine the reasoning abilities of large language models (LLMs) with the precision of traditional machine learning (ML) classifiers. For instance, XGBoost classifiers can identify flaky tests with 92% accuracy when trained on historical test data [3]. This is critical because flaky tests often delay deployments and add unnecessary workload for teams.
Modern software delivery has accelerated from quarterly releases to multiple deployments per day... human decision points interpreting flaky tests and choosing rollback strategies remain major sources of latency and operational toil.- Mohammad Baqar, Cisco Systems Inc [3]
Multi-agent systems, such as CrewAI, take this a step further. These systems assign specialised AI agents to different tasks - like security scans, observability monitoring, and test triage - allowing them to collaborate on complex workflows. For example, these agents can evaluate the health of a canary deployment, checking error budgets and deciding whether to promote, pause, or roll back a release. Safety is ensured through Policy-as-Code frameworks, like Open Policy Agent (OPA) with Rego, which enforce strict constraints. Actions are only taken if confidence levels exceed 0.8 [3]. Beyond improving testing, AI also optimises resource usage through proactive scaling.
AI for Proactive Scaling
Building on predictive analysis, AI-powered scaling algorithms adjust resources in advance, based on anticipated demand. These systems compare forecasts with Kubernetes resource limits to ensure smooth operations. In a 2025 workflow by Dynatrace's Observability Lab, Davis AI identified workloads, predicted limit breaches, and automatically created a GitHub Pull Request to update the maxReplicas value in the HorizontalPodAutoscaler manifest [2][1].
AI-enhanced pipelines not only cut lead times by 25% but also reduce MTTR by 26% [3]. Developers can activate specific workloads using metadata tags (e.g., predictive-kubernetes-scaling.../enabled: 'true'), allowing them to focus on higher-value tasks while maintaining the safety and stability required for production systems [1][3].
AI Methods for Real-Time Event Processing
Real-time event processing has advanced significantly, moving away from basic threshold alerts to systems that interpret intent, understand context, and act on their own. This evolution marks a shift from rigid, rule-based automation to intelligent orchestration. A clear example of this can be seen in serverless environments, where AI handles tasks ranging from detecting anomalies to managing self-healing workflows.
Machine Learning for Anomaly Detection
Static thresholds often fail to catch subtle signs of system failures. Machine learning, however, creates dynamic baselines by analysing patterns over hours, days, and weeks, making it far better at detecting critical deviations. Take Amazon DevOps Guru as an example - it identifies operational issues early by correlating metric anomalies with traces and log events across distributed microservices [5].
The Argos system offers an innovative approach by combining the explainability of large language models (LLMs) with the speed of traditional machine learning. During training, it generates Python-based anomaly detection rules, which are then used deterministically in production. This hybrid method improved F1 scores by up to 28.3% on Microsoft’s internal datasets and sped up inference times by 1.5x to 34.3x compared to directly using LLMs during runtime [10]. By separating training from inference, teams avoid the latency and unpredictability of relying on LLMs in critical production environments.
An explainable anomaly detection system will enable on-call engineers to easily improve any inaccuracies.- Yile Gu et al., University of Washington/Microsoft Research [10]
Safety remains a priority, and Policy-as-Code guardrails ensure that AI systems operate within strict boundaries. Tools like Open Policy Agent enforce constraints, such as blocking deployments with critical vulnerabilities or limiting autonomous actions to a small percentage of traffic. This balance between speed and control allows AI to act quickly while maintaining the reliability required in production [3]. These detection systems seamlessly integrate with fully automated corrective actions, creating a robust framework for real-time issue resolution.
AI-Driven Workflow Automation
Once issues are detected, AI agents now take the next step: automating complex workflows. These agents go beyond rigid rule-based paths by interpreting intent and dynamically selecting the right tools. For instance, a developer might request, “Duplicate the production environment for QA.” The AI agent handles everything - from provisioning infrastructure to configuring networking and deploying services - without the need for manual intervention [11].
Serverless architectures further enhance this capability. Multi-stage AI pipelines can chain tasks like optical character recognition, classification, and summarisation using orchestration tools such as AWS Step Functions. Each layer - Event Trigger, Processing, Inference, Decisioning, and Storage - operates independently, with resilience built in through mechanisms like Dead-Letter Queues. This ensures that failures in one component don’t disrupt the entire workflow [8][9]. These serverless AI workflows maintain resource utilisation at roughly 75%, while processing latency drops significantly - from 1.0054 seconds at 2 events per second to 0.5964 seconds at 10 events per second - thanks to reduced cold starts and optimised queuing [6].
An example of this is Qovery’s AI DevOps Copilot, trained on data from 25 million applications and over 30 million infrastructure operations. It deploys specialised agents for tasks like FinOps, DevSecOps, observability, provisioning, and CI/CD. These agents handle work that would traditionally take developers 10 or more hours each week [11]. This transition from static scripts to autonomous agents represents a major leap forward. AI systems now grasp why an error occurs, not just that it happened, enabling true automated recovery and a new level of operational efficiency.
Case Studies: AI in DevOps Applications
Hokstad Consulting's AI Strategy in DevOps

Hokstad Consulting has embraced event-driven automation to respond instantly to triggers like CPU spikes, storage warnings, and application errors. Their systems are designed to self-heal, automatically restarting offline servers and fine-tuning database connection pools. They've also integrated automated compliance workflows directly into their DevOps pipelines, ensuring that newly created virtual machines adhere to GDPR and security standards. This not only streamlines compliance but also cuts down on manual audit costs.
The impact of this automation is striking: monthly labour costs drop from £800–£3,200 to just £100–£400. Response times shrink dramatically, from 15 minutes–4 hours to an impressive 30 seconds–5 minutes. Error rates are reduced from 2%–8% to as low as 0.1%–1%, and compliance risks are lowered from medium-to-high to low, thanks to standardised processes. Hokstad Consulting operates on a No Savings, No Fee
model, taking on low-risk projects that show results within 30–60 days. Clients only pay when they see measurable savings, showcasing how AI can drive real-time optimisation in DevOps.
AI Agents in Major Cloud Platforms
In addition to internal innovations, major cloud platforms are pushing the boundaries of AI-driven automation. For example, in 2025, Microsoft introduced autonomous agents powered by GPT-4o to evaluate Troubleshooting Guides (TSGs) and run automated troubleshooting workflows, significantly reducing incident resolution times [13]. These agents integrate with management tools like ServiceNow and PagerDuty, automating tasks such as triage, root cause analysis, and mitigation, which helps cut down Mean Time to Recovery (MTTR) [15].
Azure SRE Agents are now capable of managing compute, storage, networking, and database services via CLI and REST APIs with minimal human intervention [15]. Similarly, Amazon Bedrock Agents use the Amazon Nova language model to handle cost enquiries and route them to optimisation workflows, drawing on real-time data from AWS Cost Explorer [12].
Unlike traditional rule-based orchestration tools like AWS Step Functions, which depend on predefined rules and fixed sequences, AI-native orchestration systems can process unstructured natural language inputs [7] and adjust dynamically [16]. This evolution towards AI-powered systems represents a shift from manual troubleshooting to autonomous agents that can run log queries and perform real-time root cause analysis [13].
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
AI Framework Comparison
::: @figure 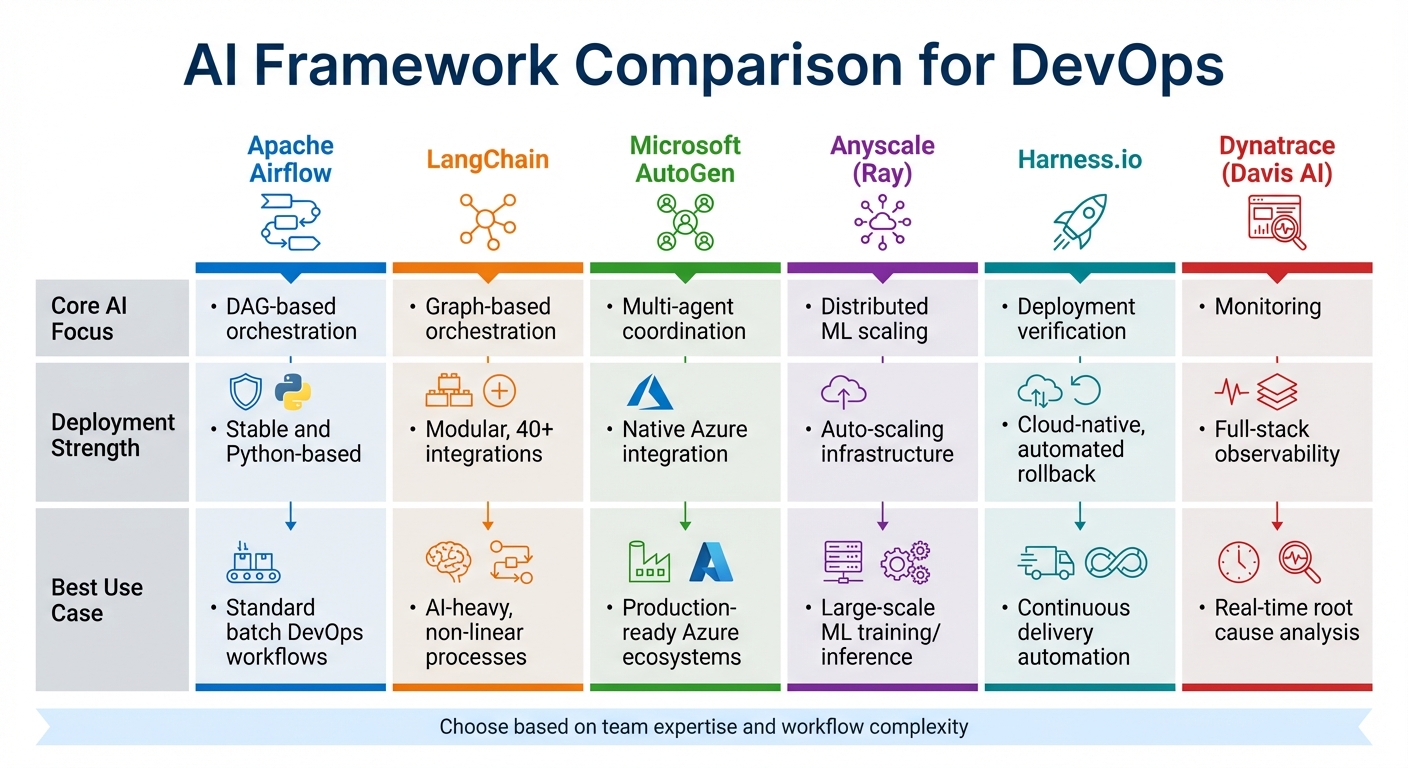 {AI DevOps Framework Comparison: Features and Best Use Cases}
:::
{AI DevOps Framework Comparison: Features and Best Use Cases}
:::
Choosing the right AI framework depends on your team's expertise and the complexity of your workflows. For teams proficient in Python and handling standard batch DevOps workflows, Apache Airflow is a dependable option. Its stability and focus on linear processes, organised as Directed Acyclic Graphs (DAGs), make it a go-to for predictable, structured tasks [18]. On the other hand, if you're tackling AI-intensive, non-linear, and dynamic workflows, LangChain is a better fit. It uses graph-based orchestration and integrates with over 40 tools, providing the flexibility needed for more complex scenarios [18].
For those working within the Azure ecosystem, Microsoft AutoGen and Azure AI Foundry are tailored solutions. They offer event-driven coordination, SOC 2 compliance, and managed identity security, making them ideal for production-ready environments. These frameworks excel in coordinating multi-agent systems, where specialised agents collaborate to address intricate tasks. Azure Logic Apps adds another layer of utility by distinguishing between autonomous agents (perfect for long-running governance tasks) and conversational agents (designed for human-in-the-loop workflows via chat interfaces). With over 1,400 connectors, it supports building robust tools for agent-based workflows [16][14].
The industry is also moving towards Agentic AIOps, where systems autonomously resolve incidents. This shift addresses the issue of tool sprawl - currently, 54% of developers juggle between 6 and 14 tools daily, leading to substantial coordination challenges [18]. By adopting fully autonomous, agent-driven workflows, organisations aim to streamline operations and reduce overhead [19].
These frameworks enhance real-time event processing and enable triggered actions, aligning with the broader AI-driven changes in DevOps. Below is a table summarising the key differences among these frameworks:
AI Framework Comparison Table
| Framework / Tool | Core AI Focus | Deployment Strength | Best Use Case |
|---|---|---|---|
| Apache Airflow | DAG-based orchestration | Stable and Python-based | Standard batch DevOps workflows [17][18] |
| LangChain | Graph-based orchestration | Modular, 40+ integrations | AI-heavy, non-linear processes [18] |
| Microsoft AutoGen | Multi-agent coordination | Native Azure integration | Production-ready Azure ecosystems [18] |
| Anyscale (Ray) | Distributed ML scaling | Auto-scaling infrastructure | Large-scale ML training/inference [18] |
| Harness.io | Deployment verification | Cloud-native, automated rollback | Continuous delivery automation [17] |
| Dynatrace (Davis AI) | Monitoring | Full-stack observability | Real-time root cause analysis [17] |
When incorporating AI into DevOps, it's wise to begin with smaller, high-impact areas like deployment verification or anomaly detection. Attempting to automate everything from the outset can be overwhelming. Instead, take an iterative approach, refining and expanding as your team gains experience [20]. For Python-focused teams managing standard workflows, Apache Airflow remains a solid choice. Meanwhile, LangChain offers the adaptability needed for more complex, AI-driven workflows. Ultimately, the framework you choose should align with your team's capabilities and the unique challenges you're aiming to solve [18].
Future Trends in Event-Driven DevOps and AI
Agentic AI Systems for Workflow Orchestration
DevOps is evolving from traditional rule-based automation to a more dynamic, AI-driven orchestration model. Here, specialised agents - like Triage, Security, and Observability agents - work together via event-based coordination to handle complex, multistep tasks across distributed systems. Instead of hardcoding every action, these agents operate based on intent and context, making workflows far more adaptive and intelligent [7][21][3].
To facilitate this shift, a dual-layer communication architecture is emerging. On one hand, EventBridge ensures deterministic and auditable event routing. On the other, AgentCore Memory and Agent-to-Agent (A2A) protocols enable semantic state sharing and capability discovery. This setup allows autonomous systems to adopt observe-thought-action
patterns, where they can independently identify issues, diagnose root causes, and take corrective actions in live production environments [7][22].
Orchestration is no longer just about rules, it's about intent interpretation, tool selection, and autonomous execution[7]
This approach builds on earlier AI automation breakthroughs, driving DevOps closer to fully autonomous operations.
The transition towards autonomy is being handled cautiously through a four-tier trust model:
- Observational: AI provides recommendations only.
- Approval-Gated: Human oversight is required before execution.
- Narrow Autonomy: AI operates within predefined boundaries.
- Conditional Autonomy: Full autonomy is granted, but with safety measures like kill-switches [3].
The market for AI-driven self-healing DevOps is expected to skyrocket, growing from £942.5 million in 2022 to £22.1 billion by 2032 [4].
Infrastructure Requirements for AI-Enhanced DevOps
While AI is transforming orchestration, strong infrastructure remains the backbone of these systems. For AI to function effectively, cross-layer fault tolerance must be in place, covering everything from hardware to applications. A unified observability stack that integrates logs, metrics, and traces is essential for accurate AI decision-making. Tools like Amazon CloudWatch help by correlating data across AWS resources and on-premises servers, breaking down silos that could otherwise hinder AI performance [7][22][5].
Container orchestration platforms like Kubernetes play a key role in enabling AI to manage tasks such as resource allocation, load balancing, and fault tolerance in real time. Similarly, Infrastructure as Code (IaC) tools like Terraform or OpenTofu ensure consistent environments, while an audit and logging layer tracks AI decisions for compliance and risk management.
Hybrid cloud environments add complexity, requiring advanced monitoring systems to oversee diverse setups. These systems must support continuous feedback loops, enabling AI to refine its decision-making processes based on post-execution results. A phased approach is recommended, starting with read-only AI recommendations. Once decision accuracy is validated, bounded autonomy can be introduced. For instance, decision thresholds of 0.80–0.85 can be set to determine when an agent can act independently without human intervention [3][4][3].
Conclusion
AI is reshaping event-driven DevOps workflows, shifting teams away from reactive problem-solving towards proactive, intelligent automation. The results speak volumes: organisations adopting these systems have seen a 55% reduction in mean time to recovery and, in advanced DevOps environments, an astonishing 208-fold increase in code deployment frequency [4]. Considering that service downtime can cost major cloud providers approximately £75 million per hour [22], these improvements bring not just operational efficiency but also substantial cost savings and enhanced reliability.
The industry is catching on to this potential. Predictions show that the market for AI-driven self-healing DevOps could expand from roughly £707 million in 2022 to an impressive £16.6 billion by 2032 [4], signalling widespread adoption across the sector.
However, achieving success involves more than just implementing AI models. Organisations need robust infrastructure that incorporates cross-layer fault tolerance, unified observability, and policy-as-code guardrails. These elements ensure AI operates safely within set parameters. The staged autonomy model - moving from offering recommendations to conditional full autonomy - provides a practical way for organisations to build trust in AI while maintaining oversight [3].
For businesses aiming to optimise their DevOps and cloud costs, AI isn't just an option - it’s quickly becoming a necessity. Hokstad Consulting offers expertise in AI strategies and DevOps automation, helping companies embrace this transformation with tailored cloud solutions. By combining predictive intelligence with autonomous responses, AI is solidifying its role as a cornerstone of modern DevOps.
FAQs
How does AI improve event-driven DevOps workflows with predictive triggers?
AI plays a key role in improving event-driven DevOps workflows through predictive triggers. These triggers use machine learning to spot patterns and predict issues like resource shortages, performance slowdowns, or system failures before they happen. This allows for automated actions - such as scaling resources or addressing incidents - before problems escalate. The result? Systems stay efficient, and downtime is kept to a minimum.
With predictive triggers in place, DevOps teams can automate tasks like adjusting resources, resolving incidents, and ensuring compliance. This cuts down on manual work, boosts efficiency, and helps lower operational costs. It also enables quicker deployment cycles, reduces errors, and fine-tunes cloud infrastructure - perfectly aligning with the modern DevOps aim of agility and reliability.
How do AI agents enhance automation in DevOps workflows?
AI agents bring a new level of automation to DevOps by enabling event-driven processes that can function without constant human oversight. These smart tools are capable of monitoring systems, analysing data, and performing tasks in real time. This cuts down on manual work and ensures operations run smoothly.
Some of their common uses include:
- Monitoring logs for anomalies
- Validating deployments
- Checking system health
- Responding to incidents automatically
By using techniques like predictive analytics and event orchestration, AI agents can foresee potential issues, such as resource shortages or security risks, and take action before they escalate. For example, they might suggest scaling resources to avoid bottlenecks or apply security patches automatically to safeguard systems.
This approach doesn’t just boost efficiency; it also minimises downtime and makes scaling operations easier. The result? Faster, more dependable DevOps workflows.
What are the best AI frameworks for enhancing event-driven DevOps workflows?
When you're working on improving event-driven DevOps workflows, a few AI frameworks stand out for their effectiveness. For instance, Argo Events works effortlessly with Kubernetes, enabling you to manage a variety of event sources and triggers with ease. On top of that, AI models, especially large language models (LLMs) and AI agents, are becoming increasingly pivotal in AIOps. These tools are being used to predict issues, automate fault detection, and enhance incident response.
By integrating these frameworks and tools, teams can automate repetitive tasks, boost system reliability, and cut down response times. This makes them a key asset for today’s fast-paced DevOps environments.