
Scaling stateful applications is challenging but essential for businesses running databases, messaging systems, or session-based services. Unlike stateless systems, stateful apps require persistent storage, stable identities, and strict sequencing when scaling. By 2026, Kubernetes has become the standard for managing these workloads, with over 80% of organisations expected to run databases on it.
Key strategies for scaling include:
- Vertical Scaling: Add resources to a single server (e.g., CPU or memory upgrades). Simple but limited by hardware capacity.
- Horizontal Scaling: Add more servers or nodes, ideal for cloud-native systems. Requires sharding, load balancing, and data synchronisation.
- Sharding: Distribute data across multiple servers for better performance and resilience. Choosing the right sharding key is critical.
- Replication: Create data copies across nodes for high availability and disaster recovery. Balance between synchronous (strong consistency) and asynchronous (lower latency).
Kubernetes StatefulSets are crucial for managing stateful apps, offering features like unique pod identities and persistent storage. Tools like Prometheus for monitoring, dynamic provisioning for storage, and autoscalers (HPA/VPA) optimise scaling. However, scaling must follow best practices, including monitoring, resource allocation, and graceful updates, to avoid downtime or inefficiencies.
Scaling stateful systems requires expertise to handle complexities like data integrity and cost management. Hokstad Consulting supports UK businesses with tailored solutions, helping optimise performance, cut costs, and integrate tools like AI for predictive scaling.
Running Stateful at Scale: Scalable SQL Databases on Kubernetes | CockroachDB Webinar
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Core Strategies for Scaling Stateful Applications
::: @figure 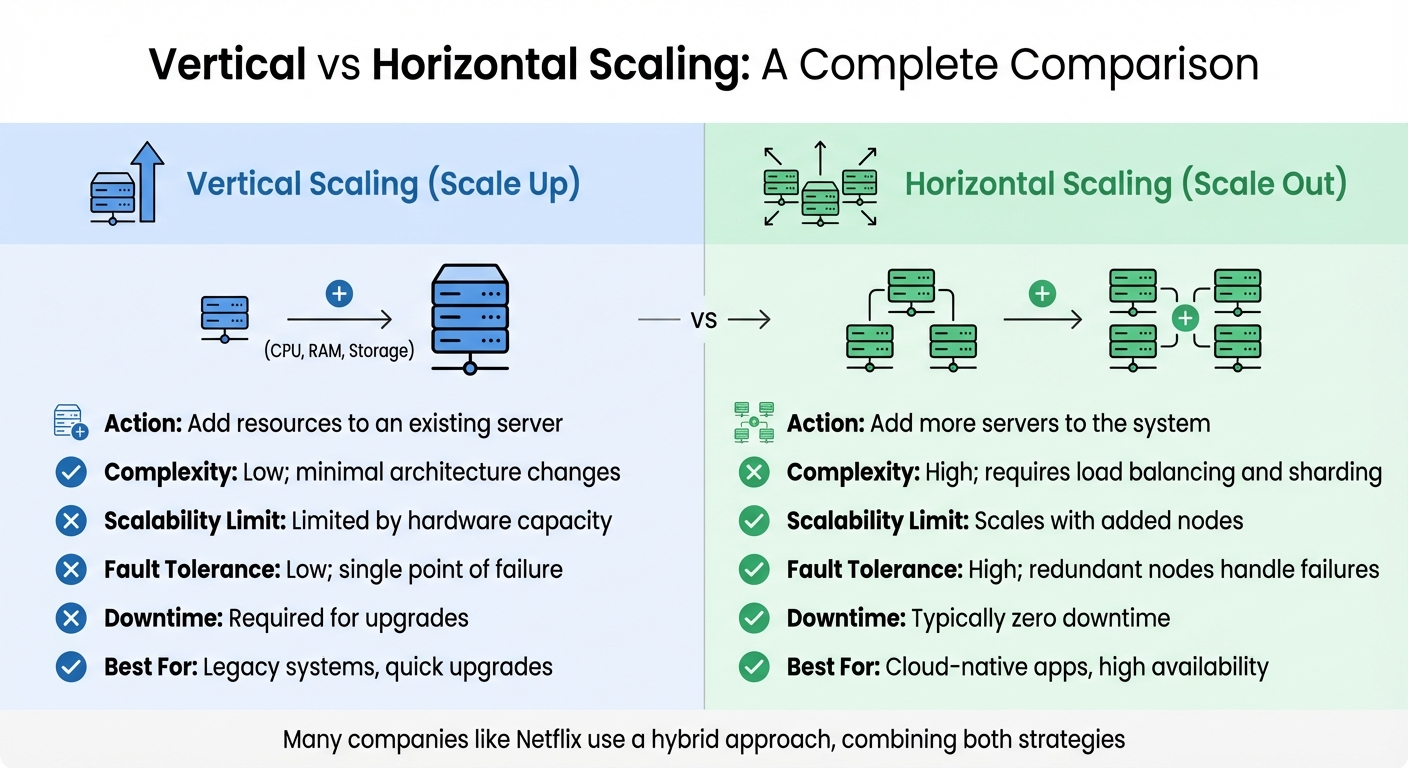 {Vertical vs Horizontal Scaling for Stateful Applications Comparison Chart}
:::
{Vertical vs Horizontal Scaling for Stateful Applications Comparison Chart}
:::
Scaling stateful applications effectively involves three primary strategies: vertical scaling, horizontal scaling with sharding, and replication. Each method addresses specific needs related to performance, availability, and cost. The right choice depends on your application's architecture, traffic patterns, and tolerance for downtime.
Vertical Scaling vs Horizontal Scaling
Vertical scaling (scaling up) increases the capacity of a single server by upgrading its CPU, memory, or storage. It’s a straightforward approach, requiring minimal changes to the application. This method is ideal when partitioning isn’t an option [4][3].
On the other hand, horizontal scaling (scaling out) adds more servers or nodes to distribute the workload. This approach provides greater scalability and fault tolerance but introduces challenges like load balancing and data synchronisation [4][6]. As Microsoft Azure explains:
Scalability is measured by the ratio of throughput gain to resource increase. Ideally in a well-designed system, both numbers are proportional[5].
When deciding between these two, consider your specific needs. Horizontal scaling is best suited for cloud-native designs that need to handle unpredictable traffic surges or rapid growth. Vertical scaling works well for applications requiring consistent, high-resource demands where partitioning the database isn’t feasible [4][3]. Many companies, such as Netflix, use a hybrid approach, blending both strategies to manage global content and large datasets [4]. For horizontal scaling, externalising session state - storing it in a distributed cache or database instead of in-memory on individual servers - can simplify implementation [3].
| Feature | Vertical Scaling (Scale Up) | Horizontal Scaling (Scale Out) |
|---|---|---|
| Action | Add resources to an existing server | Add more servers to the system |
| Complexity | Low; minimal architecture changes | High; requires load balancing and sharding |
| Scalability Limit | Limited by hardware capacity | Scales with added nodes |
| Fault Tolerance | Low; single point of failure | High; redundant nodes handle failures |
| Downtime | Required for upgrades | Typically zero downtime |
| Best For | Legacy systems, quick upgrades | Cloud-native apps, high availability |
Beyond hardware scaling, optimising data distribution through sharding can further boost performance.
Sharding and Partitioning Data
Sharding splits a large database into smaller, more manageable parts (shards) distributed across multiple servers. This approach bypasses the physical limits of a single database and improves performance, especially for applications handling high concurrency [6][7][8]. By enabling parallel operations across shards, throughput is significantly enhanced [7].
The success of sharding depends on choosing the right sharding key. A good key ensures an even workload distribution. Avoid common attributes like the first letter of a name, as they can lead to uneven hot
partitions. Instead, use something like a hashed customer ID [7][8]. Additionally, design your schema to keep frequently accessed data within a single shard, as cross-shard joins are inefficient and often require complex logic at the application level [7].
Partitioning also improves system resilience. If one partition fails, only that specific data subset is affected, while the rest of the system remains functional [7]. You can store different partitions on various hardware or storage tiers based on how they are used. For instance, older data can be archived on more cost-effective storage [7]. Services like Azure Cosmos DB and SQL Elastic Pools simplify this process by offering built-in sharding with automatic rebalancing [7].
Replication for High Availability
Replication involves creating multiple copies of your data across different nodes to ensure the system remains operational even if the primary node fails [2]. This approach addresses issues like data consistency and storage reliability. Geographically distributed replicas can also reduce latency for users in different regions and improve disaster recovery [10]. A common setup is to designate a cluster leader (writer) for handling all write operations, while read replicas manage read requests to enhance performance [9].
The choice between synchronous and asynchronous replication impacts both consistency and speed. Synchronous replication ensures strong consistency by writing data to all replicas before confirming an operation, but this can increase latency. Asynchronous replication, on the other hand, acknowledges writes immediately, allowing replicas to update later. While faster, it comes with the risk of temporary inconsistencies.
To protect replicas from sudden traffic spikes, use a load manager or proxy [9]. Also, design your application to handle node shutdowns gracefully. This can be achieved by monitoring shutdown events and using message queues to prevent data loss during processing [5].
Tools and Technologies for Scaling Stateful Applications
Scaling stateful applications can feel like a challenge, but the right tools can make it manageable. Modern orchestration platforms and storage systems provide the backbone for running databases, message queues, and distributed caches effectively.
Using Kubernetes StatefulSets
StatefulSets are Kubernetes' go-to solution for managing stateful applications. Unlike Deployments, they assign each pod a unique, persistent identity - like web-0, web-1, web-2 - that stays consistent even if pods are rescheduled across nodes [1]. Pods are deployed in a specific order, ensuring that dependencies are respected. For example, a database's primary node (web-0) must be operational before replicas (web-1, web-2) can initialise. This OrderedReady policy is essential for applications with strict startup requirements [1]. As Plural.sh puts it:
StatefulSets excel with stateful applications: Choose StatefulSets when your application requires persistent storage, stable network identities, and ordered deployments[11].
Each pod in a StatefulSet gets its own PersistentVolumeClaim (PVC) through volumeClaimTemplates. If a pod fails, it can reattach to its volume upon rescheduling, keeping data intact [1]. Additionally, StatefulSets rely on Headless Services to manage network identities. Instead of a single cluster IP, headless services create individual DNS records for each pod (e.g., mysql-0.mysql.default.svc.cluster.local), enabling direct communication between pods - critical for distributed databases [1].
A practical example from October 2024 involved deploying MySQL with a StatefulSet. The setup included three replicas: a primary node (mysql-0) for write operations and two replicas (mysql-1, mysql-2) using Percona XtraBackup to clone data. When the cluster scaled from three to five replicas, new nodes seamlessly initialised with existing data, while the mysql-read service handled read traffic across healthy replicas [14].
One key point: deleting a StatefulSet doesn’t automatically remove its PVCs. Kubernetes documentation highlights:
Deleting and/or scaling a StatefulSet down will not delete the volumes associated with the StatefulSet. This is done to ensure data safety[1].
To avoid unused storage costs, you’ll need to manually clean up PVCs unless you configure the persistentVolumeClaimRetentionPolicy for automatic deletion. For production environments, use the ReadWriteOncePod access mode to ensure that only one pod can write to a volume at a time [1].
| Feature | StatefulSet | Deployment |
|---|---|---|
| Pod Identity | Unique and persistent (ordinal) | Interchangeable and random |
| Storage | Dedicated volume per pod | Shared or ephemeral storage |
| Scaling Order | Sequential (ordered) | Parallel (unordered) |
| Network ID | Stable DNS per pod | Single ClusterIP for the set |
| Best Use Case | Databases, Distributed Systems | Web servers, Stateless APIs |
Next, let’s look at storage options that complement StatefulSets for reliable data management.
Persistent Volumes and Storage Solutions
Persistent Volumes (PV) and PersistentVolumeClaims (PVC) abstract storage management, allowing developers to request storage without worrying about the underlying infrastructure. This abstraction supports a variety of backends, from local SSDs to cloud-based block storage.
With dynamic provisioning, volumes are created automatically based on storage classes. For instance, you can configure high-performance SSDs for primary databases and more economical HDDs for archival data. This tiered approach balances performance and cost, moving less critical data to cheaper storage as needed.
Since Kubernetes v1.32, the persistentVolumeClaimRetentionPolicy feature has been stable, letting you decide whether PVCs should be deleted or retained when scaling down or deleting a StatefulSet [1]. Additionally, implementing Pod Disruption Budgets (PDBs) ensures a minimum number of replicas remain available during planned disruptions, like maintenance.
When paired with dynamic provisioning, distributed databases become even more scalable and reliable.
Distributed Databases and Data Stores
Distributed databases such as Cassandra, CockroachDB, etcd, and MongoDB are built to take advantage of StatefulSets. These systems rely on stable identities and persistent storage to maintain consistency and replicate data efficiently. For example, Cassandra and CockroachDB use peer-to-peer architectures to handle high concurrency across geographically distributed nodes, enabling any node to handle both reads and writes. Similarly, systems like etcd and ZooKeeper focus on coordination, while tools like Kafka and Redis provide high-throughput messaging and in-memory caching, respectively.
The KATE Stack - short for Kubernetes, ArgoCD, Terraform, and External Secrets Operator - has become a popular framework for managing stateful workloads [13]. Tools like Strimzi simplify Kafka operations by automating cluster provisioning, scaling, and upgrades while maintaining the guarantees required for stateful applications.
These tools not only simplify scaling but also improve performance, cost management, and resilience. However, keep in mind that StatefulSets can’t be scaled down if any managed pods are unhealthy. All pods must be running and ready before scaling down can proceed [12]. Monitoring readiness probes is crucial to ensure that every instance is fully prepared to handle traffic.
Best Practices for Scaling Stateful Applications
Scaling stateful applications isn't just about throwing more resources at the problem. It's about doing it smartly - balancing performance, cost, and reliability while sidestepping common pitfalls that could lead to downtime or unnecessary expenses.
Monitoring and Observability
Without proper monitoring, issues can remain hidden until they cause serious disruptions. Abhilash Warrier from eG Innovations highlights this risk:
If you forget the monitoring angle and leave your Kubernetes environment unmonitored, you will know about the problems/issues only after they have occurred.– Abhilash Warrier, eG Innovations
For Kubernetes environments, Kube-State-Metrics plays a crucial role. James Walker from Spacelift explains its importance:
Kube-State-Metrics is a key component to include in your Kubernetes monitoring strategy because it lets you make decisions based on the states of objects you've created.– James Walker, Spacelift
To ensure your monitoring tools run smoothly, set proper CPU and memory limits. Walker adds:
The CPU limit setting is especially important, as low limits will cause throttling that prevents Kube-State-Metrics from processing its work queue fast enough.– James Walker, Spacelift
When assessing database performance, focus on latency consistency rather than averages. Pure Storage points out:
Latency consistency matters more than average latency. A database with a 500-microsecond average latency but occasional 50-millisecond spikes performs worse than one with consistent 1-millisecond latency.[16]
Key metrics to track include pod readiness, PVC attachment times, and replication lag. For those using Amazon EKS, remember that as of 5th September 2023, its logs qualify as Vended Logs, which are eligible for volume discount pricing in CloudWatch.
Effective monitoring sets the stage for the next critical step: allocating resources accurately to maintain both scalability and efficiency.
Optimising Resource Requests and Limits
Accurate resource allocation is essential to avoid bottlenecks and ensure smooth scaling. The Horizontal Pod Autoscaler (HPA) depends on defined resource requests to make scaling decisions. If requests aren’t specified, the HPA won’t scale based on CPU usage for that container [19]. Explicit resource requests are necessary for every container in a StatefulSet.
The HPA operates with specific parameters:
- It checks metrics every 15 seconds and includes a 10% tolerance to avoid unnecessary scaling actions [19].
- It waits 5 minutes before scaling down to prevent wasteful up-and-down cycles (known as
flapping
) [18][19]. - During application startup, Kubernetes ignores CPU samples for the first 5 minutes to avoid triggering scaling due to warmup spikes, which are common in Java applications [19].
If you’re looking for more advanced tuning, the Vertical Pod Autoscaler (VPA) can adjust CPU and memory requests based on historical usage. However, it needs at least 24 hours of data to provide reliable recommendations [21]. To avoid conflicts, use the VPA for resource requests and the HPA for custom metrics or other resources [21].
| Feature | Horizontal Pod Autoscaler (HPA) | Vertical Pod Autoscaler (VPA) |
|---|---|---|
| Scaling Method | Adjusts replica count [19][20] | Modifies CPU and memory requests [20][21] |
| Best Use Case | Predictable, steady demand [21] | Unpredictable, fluctuating demand [21] |
| Metric Focus | Resource utilisation or custom metrics [19][21] | Historical usage patterns [21] |
| Conflict Risk | High if used with VPA on the same metric [21] | High if used with HPA on the same metric [21] |
A clever tactic to handle sudden scaling needs is deploying pause pods. These low-priority pods reserve buffer space and can be evicted when high-priority workloads need to scale up. This method avoids delays caused by provisioning new nodes and helps manage costs effectively. For example, persistent storage typically costs between £0.08 and £0.16 per GB per month, so it's worth right-sizing your volumes [16].
Once resource requests are optimised, the focus shifts to ensuring that scaling and updates happen smoothly, without service interruptions.
Implementing Graceful Scaling and Updates
Scaling down a StatefulSet only happens when all pods are healthy [12]. To ensure a smooth shutdown, use terminationGracePeriodSeconds and preStop lifecycle hooks. These settings give stateful processes enough time to finish critical tasks like flushing databases, writing caches, or committing transactions before shutting down [15][17][18].
To avoid rushing through updates, use minReadySeconds. This setting ensures the control plane waits for a pod to remain stable and ready for a specific duration before continuing with a rollout [1]. It’s particularly useful when combined with startup probes, which account for slow initialisation times in applications like databases or those with large caches.
For highly responsive scaling, consider the Kubernetes Event-Driven Autoscaler (KEDA). It can scale StatefulSets down to zero when no events are pending and supports advanced scaling formulas through Scaling Modifiers
[15][18]. An example of efficient scaling is Aerospike’s XDR, which can recover 10 million records in just 20 to 50 seconds with less than a 3% increase in CPU usage [15].
To further enhance reliability:
- Run stateful workloads in dedicated node pools to avoid resource competition with system daemons.
- Regularly compare total pod resource requests with allocatable cluster resources to ensure enough headroom for scaling operations [21].
How Hokstad Consulting Can Help You Scale

Scaling stateful applications demands hands-on expertise in DevOps, cloud infrastructure, and cost management. Hokstad Consulting offers UK businesses tailored solutions to handle the complexities of managing state in distributed systems.
Tailored Solutions for DevOps and Cloud Optimisation
Hokstad Consulting addresses the challenges of scaling by focusing on practical DevOps transformations. They specialise in automating CI/CD pipelines, implementing detailed monitoring systems, and building infrastructure optimised for stateful workloads. Whether it’s managing databases on Kubernetes StatefulSets or refining persistent storage across various cloud environments, their customised development and automation services ensure quicker deployment cycles without sacrificing data integrity.
Their expertise also extends to strategic cloud migrations, prioritising zero-downtime transitions to maintain data consistency. With experience across public, private, hybrid, and managed hosting environments, they help businesses choose infrastructure models that align with both regulatory needs and performance goals. This strong foundation not only supports scalability but also creates opportunities for cost savings.
Cutting Costs While Scaling
Scaling stateful applications can come with hefty expenses, but Hokstad Consulting tackles this through cloud cost engineering, delivering savings of 30–50%. Their No Savings, No Fee
model ensures you only pay a percentage of the savings achieved, capped at predictable fees. Key services include detailed cloud cost audits, optimised hosting setups, and ongoing performance adjustments. By right-sizing resources, introducing advanced caching strategies, and eliminating unnecessary spending, they help businesses achieve cost-effective scalability without compromising performance.
Expertise in Scaling and AI Integration
Scaling strategies are evolving, with AI playing an increasingly important role. Hokstad Consulting brings expertise in AI-driven solutions, integrating algorithms that predict usage patterns and enable systems to scale proactively before traffic surges.
As Mario Camaj highlights in his analysis of the TechTonic Shift:
AI isn't just a workload running on these platforms, it's increasingly driving how they operate.[22]
Hokstad Consulting applies AI to enhance self-healing pipelines using tools like ArgoCD, which automatically fix configuration drift. They also utilise AI agents to optimise costs by fine-tuning memory and timeout settings across distributed systems. Predictive autoscaling, coupled with prewarming techniques, helps eliminate latency during traffic spikes. With 98% of organisations now running data-heavy workloads on cloud-native platforms, they ensure efficiency and security by integrating tools like Sysdig for real-time monitoring and protection [22].
For UK businesses navigating the challenges of scaling stateful applications, Hokstad Consulting offers the technical expertise to support every step of the journey. Their retainer model provides ongoing services like infrastructure monitoring, security audits, and performance optimisation. This ensures your scaling strategy remains adaptable and aligned with your evolving business needs, seamlessly transitioning from planning to execution.
Conclusion
Summary of Strategies and Tools
Scaling stateful applications is all about finding the right balance between performance, cost, and reliability. This guide has explored key strategies like vertical and horizontal scaling, sharding, replication, and the use of Kubernetes StatefulSets - all aimed at expanding capacity while maintaining data consistency. With Kubernetes becoming a go-to solution for stateful workloads, it's clear how important the right tools are for managing these complex systems effectively.
Stateful applications bring unique challenges, such as the need for ordered scaling, stable network identities, and persistent storage - issues that don’t arise with stateless systems. Tools like StatefulSets, Operators, and distributed databases form the backbone of these solutions, while strong monitoring systems ensure problems are caught early, preventing user disruptions and keeping operational costs in check.
Understanding these strategies is a first step, but implementing them effectively often requires expert insight.
Why Expert Guidance Matters
Even with the right tools, scaling stateful applications can be tricky. Poorly planned scaling can result in cloud costs increasing by as much as 32%, or cause performance issues due to slow data migrations [9]. Expert guidance ensures that scaling strategies are tailored to your specific workloads, avoiding such pitfalls while optimising both performance and costs.
Hokstad Consulting offers hands-on expertise in automating lifecycle management, fine-tuning resource allocation, and integrating AI-driven predictive scaling. Their approach ensures you’re not just adding capacity but doing so in a way that preserves data integrity, minimises waste, and keeps pace with changing demands. With their retainer model, you’ll also benefit from ongoing monitoring, security checks, and performance enhancements - addressing both the technical and financial sides of scaling stateful systems.
With expert advice, the path to effective scaling becomes clearer. Here’s how you can take action.
Next Steps for Your Business
Start by auditing your infrastructure to pinpoint bottlenecks in databases, storage, or architecture. Choose replication methods based on your needs: go for synchronous replication when accuracy is critical, and asynchronous replication for systems that prioritise speed and low latency. For workloads requiring persistent storage, implement Kubernetes StatefulSets, and set up monitoring tools like Prometheus to track key metrics such as latency, traffic, and error rates.
Schedule quarterly disaster recovery tests to ensure your systems can handle unexpected failures, and review scaling thresholds monthly to adapt to growth or seasonal changes. These practical steps align with the strategies discussed earlier, helping you move smoothly from planning to execution.
If you're ready to streamline your DevOps processes and cut cloud costs, reach out to Hokstad Consulting. They can conduct a detailed cloud cost audit and create a scaling strategy tailored to your stateful application needs.
FAQs
How do I choose between vertical and horizontal scaling for my database?
Choosing between vertical scaling and horizontal scaling comes down to your application's structure, growth expectations, and available resources.
Vertical scaling (or scaling up) involves boosting the capacity of a single machine. It's a good fit for workloads that are steady and predictable, but it has limits tied to the hardware of that machine.
Horizontal scaling (or scaling out) means adding more machines to share the workload. This approach improves redundancy and availability, making it ideal for dynamic applications with fluctuating or heavy traffic.
When deciding, think about your workload's demands, your budget, and how scalable you need the system to be in the long run.
What’s the best sharding key to avoid hot partitions?
When choosing a sharding key to avoid hot partitions, opt for a high-cardinality, stable column - something like a customer ID or account number works well. This key should be present in all sharded tables and consistently used in joins. Doing so ensures data is evenly distributed and helps prevent workload bottlenecks.
How can I scale a Kubernetes StatefulSet without downtime or data loss?
To safely scale a Kubernetes StatefulSet while avoiding downtime or data loss, make sure your cluster is running version 1.5 or later. Once verified, you can scale the StatefulSet using the following methods:
Run the command:
kubectl scale statefulsets <stateful-set-name> --replicas=<new-replicas>Alternatively, manually update the
.spec.replicasfield in the StatefulSet's manifest file.
Scaling is designed to happen one Pod at a time, ensuring the system remains stable throughout the process. Keep a close eye on the scaling operation to confirm that everything runs smoothly and your application remains available.