
Looking to cut cloud costs by up to 91%? AWS Spot Instances and Google Cloud Preemptible VMs offer heavily discounted compute resources, but they come with trade-offs like potential interruptions. Spot Instances have no runtime limit but can be reclaimed with a 2-minute warning. Preemptible VMs, on the other hand, are capped at 24 hours and provide a 30-second shutdown notice. Both are ideal for fault-tolerant tasks like batch processing, CI/CD pipelines, and big data analytics.
Key Differences:
- Maximum Discount: AWS Spot up to 90%, Google Preemptible up to 91%.
- Runtime Limit: Spot Instances have none; Preemptible VMs are capped at 24 hours.
- Pricing: Spot prices fluctuate every 5 minutes; Preemptible prices are fixed for 24 hours.
- Billing: Both use per-second billing, but Google offers a 1-minute free preemption window.
Best for: Low-priority workloads that can handle interruptions. Use strategies like checkpointing and auto-scaling to minimise data loss and downtime.
Quick Comparison:
| Feature | AWS Spot Instances | Google Preemptible VMs |
|---|---|---|
| Maximum Discount | Up to 90% | Up to 91% |
| Runtime Limit | None | 24 hours |
| Pricing Updates | Every 5 minutes | Every 24 hours |
| Free Preemption Window | None | No charge if preempted within 1 minute |
For UK businesses, these options can significantly reduce cloud costs when paired with fault-tolerant systems. Want to save more? Focus on automation, regional pricing, and workload flexibility.
::: @figure 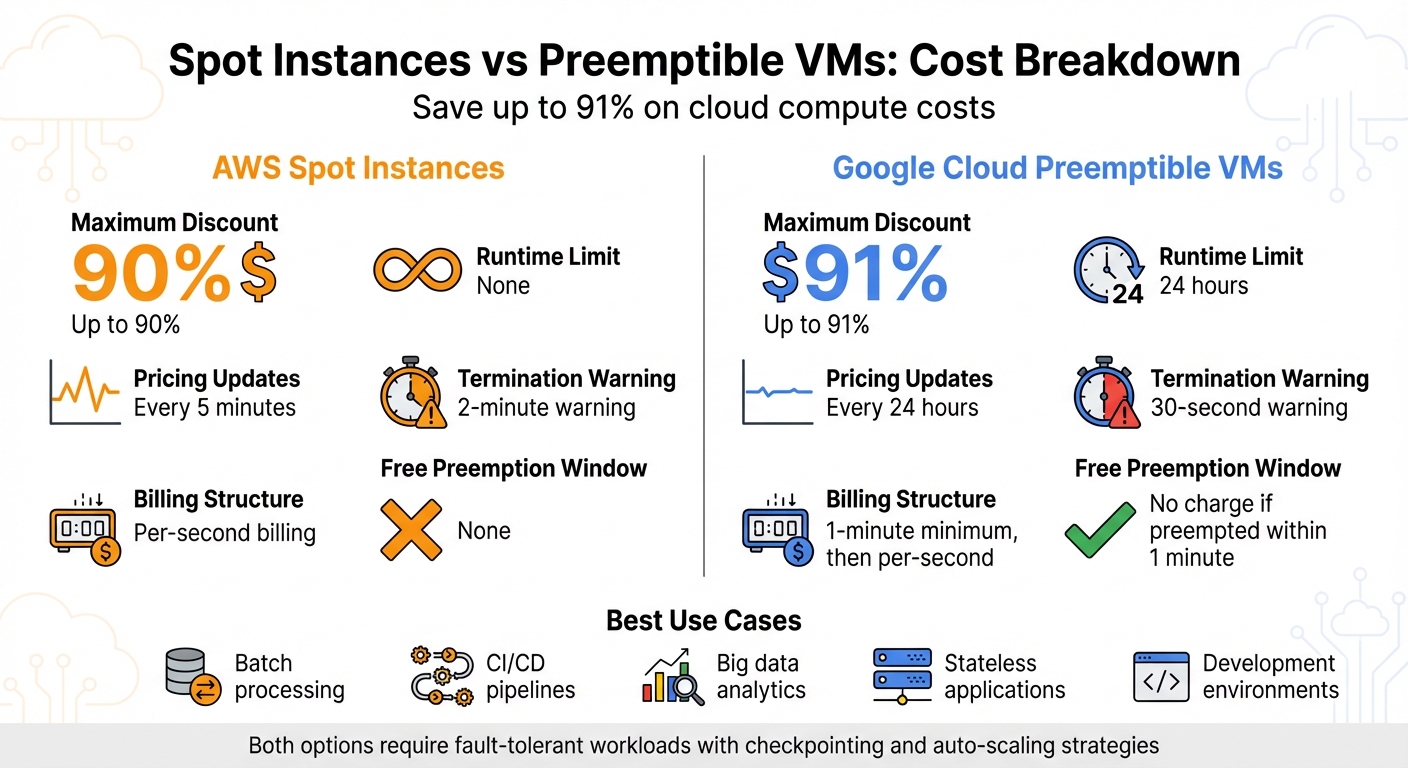 {AWS Spot Instances vs Google Preemptible VMs Cost Comparison}
:::
{AWS Spot Instances vs Google Preemptible VMs Cost Comparison}
:::
What Are Spot Instances?
Definition and Features
Spot Instances offer a cost-effective way to access surplus compute capacity, delivering the same Amazon EC2 resources as standard instances but at heavily reduced rates compared to On-Demand pricing [7]. However, AWS can reclaim these instances at any moment with just a two-minute warning. To help users manage this, AWS provides a rebalance recommendation
signal when the likelihood of interruption increases [7]. Despite this, AWS data shows that interruptions occur less than 5% of the time across regions [9].
These instances are perfect for applications that can handle interruptions, such as big data analytics, containerised workloads, CI/CD pipelines, or high-performance computing (HPC) [6]. Large organisations have seen impressive savings by integrating Spot Instances into their operations. For example, since 2014, the NFL has saved over $20 million by using Spot Instances to handle the complex computations needed to create the league's season schedule [6].
Leveraging Spot Instances to build the season schedule has enabled the NFL to save over $20 million since 2014.
This combination of cost savings and flexibility makes Spot Instances an appealing option, particularly for workloads that don’t require continuous availability. The dynamic pricing model, explained below, further enhances their appeal.
Pricing Structure
Unlike the fixed hourly rates of On-Demand instances, Spot prices fluctuate based on long-term trends in supply and demand for unused capacity [7][8]. AWS updates these prices every five minutes for each instance type and region [7][8]. There’s no bidding involved - you simply pay the current Spot price for the duration your instance runs [6][8].
Spot Instances are grouped into pools
based on the instance type and Availability Zone [7]. To increase the chances of securing Spot capacity and to reduce costs, flexibility in instance selection is key. Using attribute-based instance type selection (ABS) allows you to define requirements like vCPU count and memory instead of specifying exact instance types, which improves the likelihood of finding available capacity [9]. For short-term workloads using T4g or T3 Spot Instances, launching them in standard mode
rather than unlimited
can help avoid unexpected charges for extra CPU credits [8].
The savings can be dramatic. Lyft cut its monthly compute costs by 75% by making just four lines of code changes to integrate Spot Instances [6]. Similarly, Delivery Hero reduced its Kubernetes cluster costs by 70% by switching to Spot capacity [6]. Salesforce also benefits from Spot Instances, saving over £800,000 each month [6].
What Are Preemptible VMs?
Definition and Features
Preemptible VMs are a budget-friendly option offered by Google Cloud's Compute Engine. These instances make use of surplus capacity and operate just like standard VMs, but with a few key differences: they can be reclaimed at any time and have a strict runtime limit of 24 hours. Once this cap is reached, the instance is automatically terminated [2].
When a Preemptible VM is reclaimed, it receives a 30-second ACPI G2 Soft Off signal, allowing users to perform any necessary clean-up or save the current state. It's important to note that these instances are not covered by Compute Engine Service Level Agreements (SLAs) and lack features like live migration or automatic restarts [2].
One of their biggest draws is the cost savings - up to 91% compared to standard instances. Additionally, if a Preemptible VM is terminated within its first minute of operation, no charges are applied. Over a typical calendar quarter, the average preemption rate remains below 10%, making them a reliable option for many workloads [11].
Pricing Structure
Unlike AWS Spot Instances, which rely on a bidding system, Preemptible VMs come with a fixed pricing model. Google sets these prices, ensuring they remain stable for at least 24 hours. However, prices can be adjusted based on market trends and demand [2][3]. The pricing is broken down into components - vCPUs, memory, GPUs, and Local SSDs - all offered at significantly reduced rates when paired with Preemptible VMs. That said, charges for premium operating systems, such as Windows Server, remain at standard rates [2].
To illustrate the savings, Piyush Kalra from Pump.co shared an example in August 2025. He ran a data processing pipeline using 10 n2-standard-8 instances for 12 hours daily. At the standard rate of £0.4320 per hour, the monthly cost was £1,555.20. By switching to Preemptible VMs, priced at £0.109 per hour, the cost dropped to just £392.40 - a 74.8% reduction, saving £1,162.80 [11].
This straightforward pricing model not only simplifies cost management but also makes Preemptible VMs an appealing choice for businesses looking to cut expenses without sacrificing performance.
Cost Savings Comparison
Comparison Table
When it comes to cutting costs, both AWS Spot Instances and Google Cloud's offerings stand out, delivering impressive discounts. AWS Spot Instances can save businesses up to 90% compared to On-Demand pricing [8]. Meanwhile, Google Cloud's Spot and Preemptible VMs take it a step further, offering discounts of up to 91% [3].
The way these savings are calculated, however, varies between the two. AWS adjusts its Spot prices gradually, based on long-term supply and demand trends, with updates occurring every five minutes [8]. Google Cloud, on the other hand, uses a dynamic pricing model where prices are reviewed and potentially adjusted once every 24 hours [3]. This approach provides more predictability, which can be helpful for budget planning. Both providers offer per-second billing, but Google Cloud has a one-minute minimum charge before switching to per-second increments [4]. If a Google Cloud VM is preempted within the first minute, no charges apply [2]. The table below highlights these differences:
| Feature | AWS Spot Instances | Google Spot/Preemptible VMs |
|---|---|---|
| Maximum Discount | Up to 90% [8] | Up to 91% [3] |
| Pricing Updates | Gradual changes; updated every 5 minutes [8] | Changes once every 24 hours [3] |
| Billing Granularity | Per-second [8] | 1-minute minimum, then per-second [4] |
| Maximum Runtime | None [7] | 24 hours (for Preemptible VMs) [2] |
| Free Preemption Window | None | No charge if preempted within 1 minute [2] |
These pricing models have been tested in real-world scenarios, and the results confirm substantial savings for businesses looking to optimise infrastructure costs.
Regional Cost Variations
Regional pricing differences play a big role in determining overall cost efficiency. Costs can vary significantly depending on the location, making it essential to choose the right region for maximising savings. For instance, Google Cloud provides specific Spot pricing data for regions like London (europe-west2) and Iowa (us-central1). In Iowa, an N2 Standard instance costs approximately £0.00988 per vCPU per hour and £0.001321 per GiB of memory per hour with Spot pricing [3]. GPU costs also vary: an NVIDIA T4 GPU is priced at around £0.14 per hour, while an L4 GPU comes in at roughly £0.2231 per hour in the same region [3].
It's worth noting that premium operating systems are charged at standard rates, regardless of whether Spot or Preemptible instances are used [2]. Additionally, these discounted instances are not eligible for further savings through AWS Savings Plans or Google Cloud's Sustained Use and Committed Use Discounts [7].
To accurately estimate costs, users should rely on tools like the Google Cloud pricing calculator, ensuring they select Spot (Preemptible VM)
for precise projections [3]. For AWS, keeping an eye on the Spot pricing table - which updates every five minutes - can help identify the most cost-effective regions for specific workloads [8]. By combining regional pricing insights with free preemption windows, businesses can strategically reduce expenses across various locations.
Availability and Interruption Risks
Interruption Policies
Preemptible VMs come with a strict 24-hour runtime limit, meaning tasks must either finish or save their progress within that timeframe. On the other hand, Spot VMs can run indefinitely, provided there’s enough capacity to support them [1][12]. Both types of VMs send a 30-second ACPI G2 Soft Off signal as a best-effort warning before shutdown, making it critical to have automated processes in place to prevent data loss [1]. Since neither option includes an SLA, they aren’t suitable for workloads requiring strict uptime guarantees or time-sensitive production environments [1][2]. These policies lay the groundwork for understanding how often interruptions occur, as outlined in the next section.
Reclamation Frequency
Reclamation rates are unpredictable and can vary depending on the day, zone, and type of resource being used. While the overall likelihood of preemption is relatively low, workloads involving GPUs, TPUs, or Local SSDs might face higher risks [1][2][3]. Reclamations occur when Compute Engine reallocates resources for standard on-demand VMs or during system events. Rather than causing complete failures, these interruptions typically result in slower batch jobs or manageable delays - often ranging from 15 minutes to an hour - for processes like CI/CD pipelines [1][13][14].
As noted by Google Cloud's Customer Engineers Paul Brouwers and Stefan Salandy:
Spot VMs enable our customers to make the most of our idle capacity where and when it is available[13].Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Suitability for Workloads
Best Use Cases
Spot Instances and Preemptible VMs are ideal for fault-tolerant workloads. For example, batch processing tasks like media encoding, rendering, or financial modelling can handle interruptions - if a VM is preempted, the process may slow down, but it won’t fail entirely [1][2]. Similarly, stateless applications are a great fit since they don’t rely on local data and can easily be redistributed across available instances [10].
CI/CD pipelines and development environments can also leverage spot capacity for cost-effective and rapid deployments, which is particularly appealing to UK-based development teams [10][7]. Additionally, big data analytics and background processing tasks thrive in this environment. By distributing large-scale data analysis across many low-cost instances, you can speed up completion while significantly cutting costs [7].
If your workloads are fault-tolerant and can withstand possible VM preemption, Spot VMs can reduce your Compute Engine costs significantly[1].
For tasks without strict deadlines - like non-critical or background jobs - spot capacity is an excellent choice. These tasks can run whenever capacity is available, ensuring you pay the lowest possible price [7].
These examples underline the importance of fault tolerance, which is explored further in the next section. Choosing the right workloads and implementing fault-tolerant strategies can help you maximise savings.
Strategies for Fault Tolerance
One of the key strategies for managing interruptions is checkpointing. This involves saving the state of your workload at regular intervals, so if a VM is preempted, the process can resume from the latest checkpoint rather than starting over [1]. You should also configure shutdown scripts to handle the preemption signals - 30 seconds on Google Cloud or 2 minutes on AWS - allowing time for cleanup and data preservation [1][5][7].
Using Managed Instance Groups or Auto Scaling groups is another effective approach. These systems automatically replace preempted instances, ensuring your workload maintains its required capacity even when individual VMs are reclaimed [1][2][7]. Resource diversification is also crucial - spreading workloads across different machine types and zones reduces the likelihood of a significant portion of your fleet being reclaimed at once [1].
For Kubernetes environments, tools like nodeSelector or node affinity can help. You can configure these to assign fault-tolerant pods to spot nodes using labels such as cloud.google.com/gke-spot=true, while critical system components remain on standard on-demand instances [10]. This ensures efficient resource allocation without compromising essential operations.
Conclusion
Key Takeaways
The comparison above sheds light on the main differences and advantages of Spot VMs and Preemptible VMs. Both options can provide savings of up to 91%, but they differ in how they operate. Spot VMs can run indefinitely until reclaimed, making them ideal for long-running batch jobs. On the other hand, Preemptible VMs are automatically terminated after 24 hours, which makes them better suited for short-term tasks or legacy applications that benefit from a forced daily restart [1][2][12].
The success of either option hinges on deploying workloads designed to handle interruptions. Workloads like batch processing, stateless applications, CI/CD pipelines, and big data analytics can perform exceptionally well when paired with spot capacity, provided they are set up with checkpointing and automated recovery mechanisms [1]. For UK businesses, selecting the right instance type offers a clear opportunity to cut cloud costs while maintaining operational effectiveness.
How Hokstad Consulting Can Help

Hokstad Consulting specialises in helping businesses reduce cloud expenses by designing architectures that make the most of Spot and Preemptible VMs. They focus on creating fault-tolerant systems, automating recovery processes, and developing intelligent scheduling solutions. These strategies can help UK businesses lower their cloud costs by 30–50%, all while maintaining reliability.
Given that over 60% of organisations fail to achieve the cloud cost savings they expect and up to 90% report waste in their cloud spending [15], expert guidance is more important than ever. Hokstad Consulting leverages proven methods, like those discussed in this article, to build cost-efficient and reliable cloud infrastructures. They even offer flexible engagement models, such as a No Savings, No Fee
arrangement, ensuring businesses see measurable results. Whether you need a detailed cloud cost audit, strategic migration planning, or ongoing DevOps support, Hokstad Consulting ensures your spot capacity is used effectively, avoiding pitfalls like inadequate fault tolerance.
Spot Instances Explained: Save Up to 90% on Cloud Costs | Preemptible VMs Guide
FAQs
How can you effectively handle interruptions when using Spot Instances and Preemptible VMs?
To effectively manage interruptions with Spot Instances and Preemptible VMs, think of them as a temporary layer of capacity, not your main compute resource. Automation plays a crucial role here - your systems should be set up to handle everything from provisioning to graceful shutdowns, and they must be able to seamlessly switch to On-Demand resources when needed. Tools that monitor termination notices and replace interrupted instances can help ensure your workloads stay available.
On AWS, combining Spot Instances with Auto Scaling groups or EC2 Fleet is a smart move. Using a price- and capacity-optimised allocation strategy ensures your workloads are spread across the most cost-efficient and available zones. For Google Cloud, Spot VMs (formerly Preemptible VMs) can be managed through instance groups that automatically recreate any interrupted VMs. Additionally, using flexible instance types and zones can significantly lower the risk of losing capacity.
From an application perspective, workloads should be designed to be fault-tolerant and stateless. Incorporate periodic state-saving mechanisms so jobs can pick up where they left off if interrupted. Automatic retries and graceful termination scripts can help drain tasks before instances are reclaimed. For Kubernetes users, features like pod disruption budgets and node auto-recovery ensure services remain stable, while fallback On-Demand instances can handle critical tasks without disruption. By following these practices, you can transform the unpredictability of Spot and Preemptible resources into a cost-efficient and reliable part of your cloud infrastructure.
What are the pricing and runtime differences between AWS Spot Instances and Google Preemptible VMs?
AWS Spot Instances offer a cost-effective solution by pricing based on the current Spot market rate, with potential savings of up to 90% compared to standard On-Demand prices. These instances come with the flexibility of no fixed runtime limit, allowing them to run as long as capacity is available. However, there’s a catch: AWS can interrupt these instances at any moment.
On the other hand, Google’s Preemptible VMs have transitioned to Spot VMs, which deliver similar savings of up to 91% compared to regular Compute Engine prices. Unlike AWS Spot Instances, Google’s Spot VMs have a strict 24-hour maximum runtime per instance. Once this time limit is reached, the instances are automatically terminated. This defined runtime cap is the main distinction in how the two services handle instance availability.
What types of workloads are ideal for Spot Instances and Preemptible VMs?
Spot Instances and Preemptible VMs are a great fit for workloads that are fault-tolerant, stateless, or batch-based, especially if they can manage occasional interruptions. Common use cases include media rendering, data processing, analytics, CI/CD pipelines, and machine learning training.
These instances come at a much lower cost compared to standard options, making them perfect for non-critical tasks where interruptions won't have a significant impact. To make the most of these cost savings, it's essential to design your applications to handle pre-emptions gracefully, ensuring operations continue smoothly even when resources are reclaimed.