
Running stateful workloads in Kubernetes is challenging but essential for modern applications like databases, message brokers, and analytics tools. Why? Stateful services need to retain data and identities even when scaled or restarted, but Kubernetes pods are inherently temporary. This is where persistent storage comes in, ensuring data survives beyond a pod's lifecycle.
Key takeaways:
- PersistentVolumes (PVs) and PersistentVolumeClaims (PVCs): Kubernetes separates storage from pods, allowing data to persist even if pods are rescheduled.
- StatefulSets: Designed for stateful apps, ensuring stable pod identities, ordered scaling, and dedicated storage.
- StorageClasses: Automate storage provisioning and enable features like volume expansion and multi-zone availability.
Scaling stateful workloads requires careful orchestration to avoid data loss or corruption. Tools like readiness probes, replication, and access modes (ReadWriteOncePod) help maintain performance and availability. Common challenges include I/O bottlenecks, configuration drift, and storage inefficiencies, but solutions like monitoring tools and replication strategies can help.
Persistent storage and StatefulSets are vital for handling databases, messaging systems, and other stateful services in Kubernetes. However, scaling these workloads comes with risks like performance issues and unexpected costs, making expert guidance invaluable.
Day 45 - Kubernetes Statefulset Tutorial For Beginners (2025)
Persistent Storage in Kubernetes: Core Concepts
Kubernetes addresses the temporary nature of pods by separating storage from the lifecycle of the pod itself. PersistentVolumes (PVs) represent the actual storage resources available at the cluster level, while PersistentVolumeClaims (PVCs) are user-generated requests for those resources. This relationship is similar to how pods request CPU and memory resources from the cluster.[3]
As explained in the Kubernetes documentation:
The PersistentVolume subsystem provides an API for users and administrators that abstracts details of how storage is provided from how it is consumed.[3]
When a PVC is created, Kubernetes’ control plane searches for a compatible PV and establishes a one-to-one binding between them. This binding remains intact until the PVC is deleted. If no suitable PV is available, the claim remains pending.[3] Importantly, PVs are independent of a pod's lifecycle. This means that even if an application crashes or is rescheduled to a different node, the associated data remains intact.[3][7] This separation is the foundation for the storage mechanisms detailed below.
PersistentVolumes and PersistentVolumeClaims
PVs can be provisioned either manually by administrators (static provisioning) or automatically using StorageClasses (dynamic provisioning). Each PV supports specific access modes, which define how many nodes can connect to the volume and in what manner. The four main access modes are:
- ReadWriteOnce (RWO): A single node can mount the volume with read-write access.
- ReadOnlyMany (ROX): Multiple nodes can mount the volume, but only with read-only access.
- ReadWriteMany (RWX): Multiple nodes can mount the volume with read-write access.
- ReadWriteOncePod (RWOP): Access is limited to a single pod across the entire cluster.[3]
The ReadWriteOncePod access mode is particularly recommended when you want to ensure that only one pod can use a PVC at any time. This helps avoid issues like data corruption caused by simultaneous writes from multiple pods.[3][1] Additionally, when a PVC is deleted, the reclaim policy sets what happens to the underlying storage. The Retain
policy keeps the data for manual recovery, while Delete
removes both the PV and its associated physical storage.[3]
Kubernetes also incorporates Storage Object in Use Protection, a feature designed to prevent the accidental deletion of PVCs that are currently in use by pods or PVs bound to PVCs. This safeguard is essential for avoiding data loss during routine cluster operations.[3]
Dynamic Volume Provisioning with StorageClasses
StorageClasses streamline storage management by automating the creation and handling of PVs. Acting as blueprints, they abstract the specifics of the underlying storage provider:
StorageClasses are essentially blueprints that abstract away the underlying storage provider, as well as other parameters, like disk-type (e.g.; solid-state vs standard disks).[6]
When a PVC references a StorageClass, Kubernetes automatically provisions a new PV as needed. This feature became stable in Kubernetes 1.6 and is supported by major cloud platforms like AWS, GCP, and Azure, all of which include default StorageClasses.[6] A StorageClass can also include up to 512 parameters to define storage tiers - such as faster SSDs or slower HDDs - without exposing these details to developers.[4]
For stateful applications, the volumeBindingMode setting is particularly important. The WaitForFirstConsumer mode ensures that volume provisioning is delayed until a pod is scheduled. This ensures the storage is created in the same availability zone as the pod, reducing the risk of unschedulable pods in multi-zone clusters.[5][4] Furthermore, StorageClasses support volume expansion through the allowVolumeExpansion: true setting. This allows storage capacity to be increased simply by editing the PVC's storage request, eliminating the need to recreate the volume.[4][3]
Scaling Stateful Workloads with StatefulSets
::: @figure 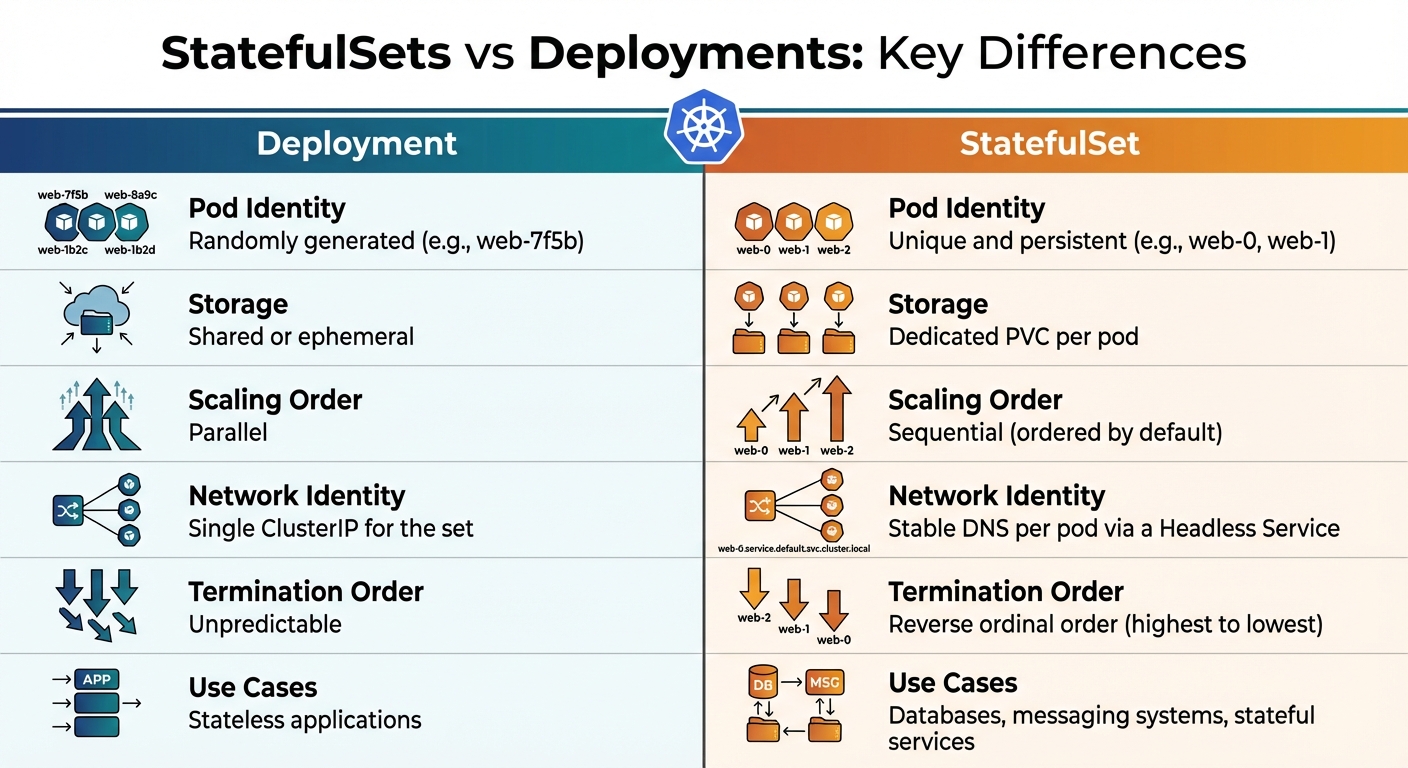 {StatefulSets vs Deployments in Kubernetes: Key Differences}
:::
{StatefulSets vs Deployments in Kubernetes: Key Differences}
:::
StatefulSets are Kubernetes' tailored solution for managing stateful applications that need stable identities and persistent storage. Unlike stateless workloads, where pods are treated as interchangeable, StatefulSets handle each pod as a distinct entity with its own dedicated storage. As Sealos Blog puts it:
In Kubernetes, we often talk about treating our application instances like cattle, not pets. Deployments are the perfect tool for this... A StatefulSet manages pets.[8]
Each pod in a StatefulSet is assigned a unique ordinal index (starting from 0 and increasing to N–1), which stays consistent even if the pod is rescheduled to a different node. This index determines the pod's hostname (e.g., web-0, web-1) and contributes to its stable DNS subdomain (e.g., web-0.nginx.default.svc.cluster.local). To achieve this, a Headless Service must be created alongside the StatefulSet.
Storage is managed on a one-to-one basis: each pod gets its own PersistentVolumeClaim (PVC), created from a volumeClaimTemplate. This ensures that even if a pod is deleted or rescheduled, its storage remains intact and reattaches to the new instance. Scaling is performed sequentially - adding pods in order from 0 to N–1 and removing them in reverse - ensuring the cluster remains stable.
StatefulSets vs Deployments: Main Differences
The key distinction between StatefulSets and Deployments is how they handle pod identity, storage, and scaling. Deployments treat pods as interchangeable, with randomly generated names (e.g., web-7f5b), while StatefulSets assign persistent identities (e.g., web-0), making them ideal for stateful applications.
Comparison Table: StatefulSets vs Deployments
| Feature | Deployment | StatefulSet |
|---|---|---|
| Pod Identity | Randomly generated (e.g., web-7f5b) |
Unique and persistent (e.g., web-0, web-1) |
| Storage | Shared or ephemeral | Dedicated PVC per pod |
| Scaling Order | Parallel | Sequential (ordered by default) |
| Network Identity | Single ClusterIP for the set | Stable DNS per pod via a Headless Service |
| Termination Order | Unpredictable | Reverse ordinal order (highest to lowest) |
| Use Cases | Stateless applications | Databases, messaging systems, stateful services |
These differences highlight why StatefulSets are the go-to choice for managing stateful workloads requiring consistent identities and storage.
Scaling StatefulSets with Persistent Storage
StatefulSets rely on persistent storage that is decoupled from pod lifecycles, combining stable identities with dedicated storage for each pod. This design ensures that scaling operations remain reliable, but it also requires careful attention to cluster health and storage management. Kubernetes will only scale StatefulSets when all pods are healthy. Before scaling up, ensure your StorageClass has enough capacity and supports volume expansion.
Readiness probes play a critical role in confirming that each pod is functioning properly before the next one is launched. This prevents performance bottlenecks. In production environments, it's a good idea to configure pod distribution rules to spread pods across different nodes, improving availability in case of node failures.
By default, StatefulSets use the OrderedReady pod management policy, which enforces sequential scaling. If your application doesn't depend on a strict startup order, you can switch to the Parallel policy, allowing all pods to launch simultaneously. During scale-down, PersistentVolumeClaims are retained by default to avoid data loss, though this could lead to additional storage costs. From Kubernetes v1.32 onwards, you can use the persistentVolumeClaimRetentionPolicy to automate PVC deletion during scale-down.
For controlled updates, the RollingUpdate partition field is a useful tool. It lets you update only pods with an ordinal equal to or greater than a specified partition value, enabling gradual rollouts or testing changes on a subset of replicas before a full deployment.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Challenges and Best Practices for Scaling Stateful Workloads
Scaling stateful workloads comes with its own set of hurdles. One of the major issues is configuration drift - this happens when the declared configuration in your manifest (like a database version) no longer matches the actual data stored in your PersistentVolumeClaim (PVC) [9]. This misalignment can cause failures during scaling or updates. Another challenge lies with workloads needing the ReadWriteMany access mode. Without proper coordination through distributed storage systems, simultaneous writes from multiple pods can corrupt your data [2]. Below, we’ll explore strategies to tackle these challenges effectively.
Data Consistency and Performance Bottlenecks
Beyond configuration issues, maintaining performance and data consistency is another critical challenge. Performance bottlenecks often stem from I/O latency, especially when storage backends struggle to manage high demand. For instance, in 2023, Salesforce addressed this by validating the StatefulSet PVC auto-delete feature (introduced in Kubernetes 1.32). This feature helped reduce costs by eliminating orphaned storage and minimising wastage [10].
To keep your data consistent, consider quiescing your application before taking snapshots. This involves pausing the application to ensure the data is in a stable state for protection [9]. Additionally, monitor for contention issues by using I/O controls to stop one application from hogging bandwidth and affecting others [9]. For faster access, you can use raw block volumes (set volumeMode: Block) to bypass the filesystem layer entirely [3].
Ensuring High Availability and Resilience
Resilience and high availability are essential for stateful workloads, requiring careful planning for replication and failover. A good option is regional persistent disks, which synchronously replicate data across multiple zones. These allow volumes to be quickly reattached to healthy nodes in other zones, ensuring no data loss if a node fails [12]. A notable example comes from 2025, when a German bank, managed by DXC, implemented Portworx synchronous replication. This solution helped them meet strict regulatory requirements, achieving near-zero data loss and a Recovery Time Objective (RTO) of under 60 minutes for their containerised workloads [9].
To enhance resilience further, use robust readiness probes like mysqladmin ping for MySQL. This ensures traffic is routed only to fully synchronised replicas [13]. In production environments, the ReadWriteOncePod access mode is a safer choice, as it guarantees that a PVC is accessed by only one pod, preventing consistency issues during scaling [1]. Finally, keep an eye on storage usage by monitoring metrics with Prometheus. Setting alerts for when volume usage exceeds 80% can prevent application crashes caused by running out of space [11].
Hokstad Consulting: Expert Solutions for Stateful Workload Optimisation

Hokstad Consulting specialises in helping businesses navigate the complexities of managing stateful workloads in Kubernetes. With a focus on persistent storage, scaling challenges, and managing cloud costs, they offer tailored solutions designed to deliver tangible results. By blending technical expertise with a results-driven approach, they help organisations streamline their infrastructure and reduce unnecessary expenses.
Custom Solutions for Kubernetes and Persistent Storage
Stateful workloads often come with hidden inefficiencies that can quietly inflate cloud costs. Hokstad Consulting identifies and addresses these issues, such as over-provisioned replicas and inefficient data transfer configurations. Their team conducts in-depth audits to pinpoint these inefficiencies and implements tiered storage strategies to move nonessential data to more economical options.
Additionally, they excel in strategic replication planning, ensuring a balance between zero data loss and improved throughput, all while keeping costs in check. They also tackle cross-region replication charges by optimising batch sizes and leveraging data compression techniques to minimise expenses.
Benefits of Partnering with Hokstad Consulting
Hokstad Consulting’s solutions deliver clear benefits in both cost savings and performance enhancements. Their expertise in cloud cost engineering typically results in a 30–50% reduction in expenses. This is achieved by fine-tuning auto-scaling policies based on actual usage patterns, avoiding both over-provisioning and the risk of downtime during traffic surges.
Their flexible engagement model makes it easy to get started. They offer a 30-minute, no-obligation consultation to provide personalised advice on cutting cloud costs. Projects operate on a no-savings, no-fee basis, with fees capped as a percentage of the savings achieved. Whether you’re looking for DevOps transformation, strategic cloud migration, or ongoing infrastructure support, their success is directly tied to your results.
Conclusion
Scaling stateful workloads in Kubernetes demands a different strategy compared to stateless applications. Persistent storage plays a key role by separating data from temporary pods, while StatefulSets ensure stable identities and ordered scaling - perfect for databases and distributed systems. Tools like StorageClasses make dynamic provisioning more straightforward, especially at scale.
That said, challenges like maintaining data consistency, avoiding I/O bottlenecks, and ensuring high availability remain significant. Tackling these issues requires careful planning - such as fine-tuning replication, leveraging access modes like ReadWriteOncePod, and routinely testing recovery procedures. These hurdles highlight Kubernetes' transformation from a stateless orchestrator into a go-to platform for enterprise backend services. However, they also reveal hidden risks, like performance dips and unexpected cost surges.
The technical demands of scaling stateful workloads can often mask inefficiencies that drive up expenses. Over-provisioning replicas, poorly configured data transfers, and inefficient replication are just a few examples of how costs can spiral out of control. Addressing these inefficiencies is critical to ensuring both optimal performance and cost management.
Expert advice becomes invaluable in navigating these complexities. Specialists can pinpoint inefficiencies and recommend solutions that balance performance, availability, and cost. In fact, expert input often leads to 30–50% reductions in cloud spending - a significant saving.
Whether you’re focused on migration, optimisation, or scaling, consulting with experts can yield tailored strategies that improve both cost and reliability. Even a short 30-minute consultation can uncover actionable steps to cut cloud expenses while keeping your stateful workloads running smoothly.
FAQs
When should I use a StatefulSet instead of a Deployment?
When deploying applications that require stable network identities, persistent storage, or ordered deployment and scaling, a StatefulSet is the way to go. This makes it ideal for use cases like databases, distributed systems, or caches where consistency and persistence are critical.
On the other hand, if you're working with stateless applications that don't need these specific features, a Deployment is usually a better fit. It offers simpler management for workloads that don't rely on maintaining state.
How do I choose the right PVC access mode (RWO, RWX, RWOP) for my app?
When deciding on a PVC access mode, consider how your application interacts with storage and whether it requires sharing:
RWO (ReadWriteOnce): Allows read-write access from a single node, making it perfect for applications that need exclusive access to their storage.
ROX (ReadOnlyMany): Enables multiple nodes to access the storage in read-only mode, ideal for applications working with static datasets or shared configurations.
RWX (ReadWriteMany): Supports read-write access from multiple nodes, commonly used for shared storage systems like NFS.
RWOP (ReadWriteOncePod): Restricts read-write access to a single Pod, ensuring no other Pod can interfere with its storage.
What’s the safest way to scale a database without data loss or downtime?
Using Kubernetes StatefulSets with persistent storage is the most reliable way to scale a database without risking data loss or experiencing downtime. StatefulSets ensure each pod has a stable network identity and its own persistent storage, which keeps your data secure during scaling operations.
Before you begin scaling, double-check that both your cluster and application are in good health. Take a gradual approach to scaling, keeping a close eye on any potential issues. If you need to delete pods, do so in reverse order (starting from the highest number), as this approach helps reduce risks.