
Post-release risk reviews are essential for identifying issues after a deployment. They focus on system performance, risks, and inefficiencies without blaming individuals. By reviewing metrics like downtime or resource usage within 24–48 hours, teams can prevent recurring problems, reduce costs, and improve reliability.
Key takeaways:
- Collaboration: Involve diverse teams to identify risks effectively.
- Metrics: Collect data on performance, recovery times, and resource use.
- Risk Prioritisation: Balance technical and business needs to address critical issues.
- Action Plans: Address findings promptly with measurable goals.
- Automation: Use monitoring tools for faster issue detection and resolution.
This process ensures deployments are smoother, costs are managed, and systems remain stable.
::: @figure 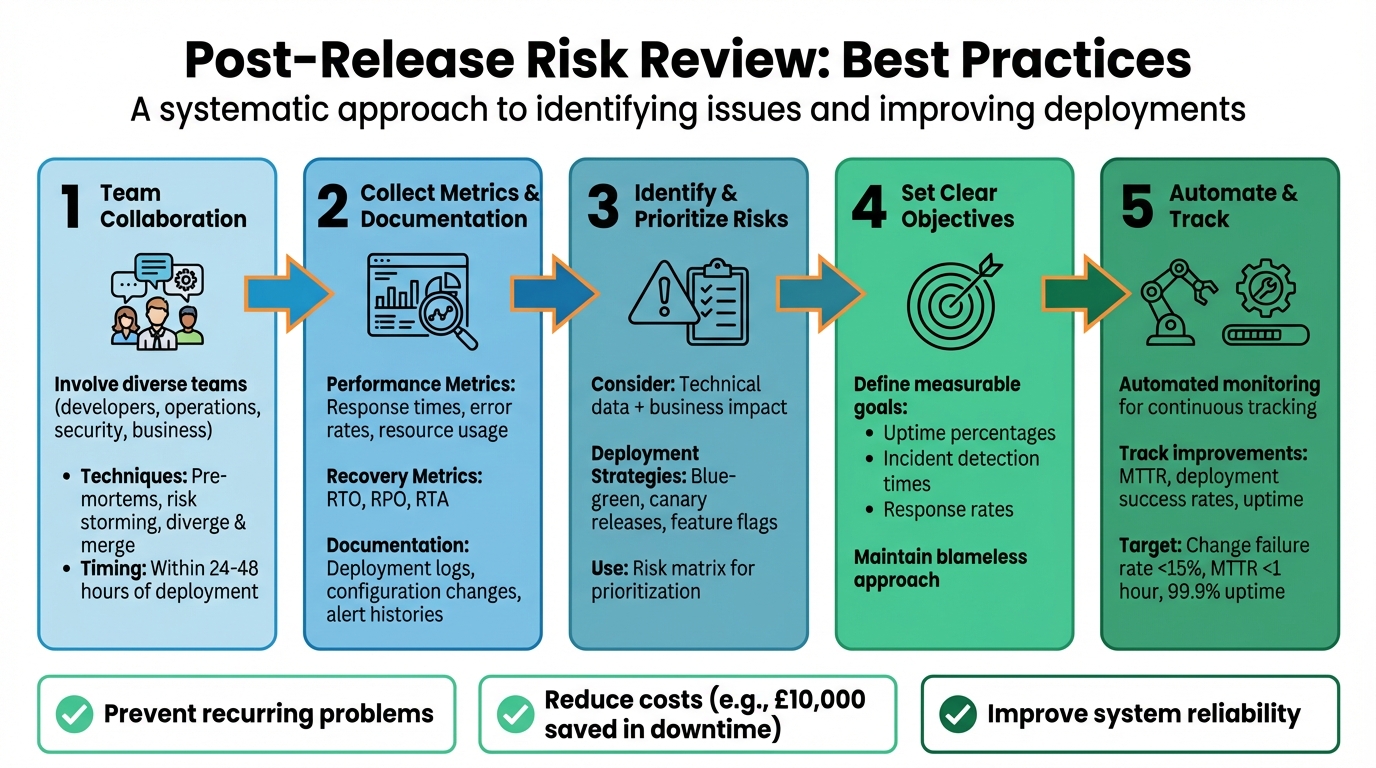 {Post-Release Risk Review Process: 5 Essential Steps for DevOps Teams}
:::
{Post-Release Risk Review Process: 5 Essential Steps for DevOps Teams}
:::
Core Elements of a Post-Release Risk Review
Team Collaboration and Communication
Post-release reviews thrive on diverse input. By involving developers, operations, security, business, and domain experts, teams can uncover risks that might be overlooked from a single perspective. This diversity helps combat common issues like groupthink or overly optimistic evaluations. To make these sessions more effective, teams often rely on collaborative techniques. For instance, pre-mortems encourage teams to think backwards from a hypothetical failure, while risk storming uses quality attributes to identify potential vulnerabilities. Another useful approach is the diverge and merge format, where team members independently draft their observations before sharing them, ensuring a wider range of perspectives. A more creative method is the nightmare headline game, where teams imagine their software making negative headlines, shifting focus towards identifying critical vulnerabilities [1].
Hindsight is actually little more than a convenient narrative based on poorly remembered facts.– Scott Logic [1]
This collaborative approach lays the groundwork for detailed documentation and accurate risk analysis.
Documentation and Metrics Collection
Collaboration needs to be backed by systematic data collection. Without accurate data, reviews risk becoming guesswork. Start by gathering performance metrics like response times, error rates, and resource usage. Recovery metrics, such as RTO (Recovery Time Objective), RPO (Recovery Point Objective), and RTA (Recovery Time Actual), are also essential for identifying performance gaps. For example, differences between planned and actual recovery times can highlight process inefficiencies.
Comprehensive documentation is equally important. This includes deployment logs, configuration changes, alert histories, and details of manual interventions. Such records ensure the review is based on facts rather than unreliable recollections.
Risk Identification and Prioritisation
Once collaboration and documentation are in place, the focus shifts to identifying and prioritising risks. This process should consider both technical data and the broader business impact. It's not just about addressing immediate technical issues but also understanding how they align with business priorities, particularly during critical periods.
Different deployment strategies come with varying levels of risk. For example, blue-green deployments allow for instant rollbacks but require more resources. Canary releases offer a gradual rollout, balancing risk and control, while feature flags provide instant, low-risk rollback options. Prioritising risks involves weighing both technical and business factors to ensure the most critical issues are addressed effectively.
Best Practices for Post-Release Risk Reviews
Set Clear Objectives and Success Metrics
For any post-release review to be effective, you need to start with well-defined, measurable goals. Instead of vague aims like better system stability
, focus on specific performance indicators. These could include metrics like uptime percentages, incident detection times, or response rates. The key is to align these indicators with business priorities - such as ensuring revenue retention during peak periods or improving customer experience during critical transactions.
Metrics should cover multiple areas:
- System infrastructure: Things like CPU usage and memory consumption give insight into resource efficiency.
- Application health: Metrics such as error rates or database query speeds help assess technical reliability.
- User experience: Factors like page load times or transaction success rates directly affect customer satisfaction.
- Business outcomes: Conversion rates and revenue per visitor connect technical performance to financial results.
When teams know exactly what they're measuring, the review process becomes much more focused and actionable. Also, maintaining a blameless approach ensures that discussions remain constructive and centred on improvement rather than assigning fault [2].
Once you've set your objectives, scheduling the review promptly is crucial to capturing valuable insights while they're still fresh.
Schedule Reviews Immediately After Deployment
Timing is everything when it comes to post-release reviews. Conducting the review within 24 to 48 hours of deployment ensures that the details, context, and monitoring data are still fresh. Waiting too long risks losing critical context, archived data, and the sense of urgency needed to address potential issues. Early reviews also help teams spot and resolve problems before they escalate.
To make the most of the review, use monitoring data to reconstruct an accurate timeline of events. Identify when issues were detected, how quickly the team responded, and how long resolution took [3]. This evidence-based approach shifts the focus from guesswork to actionable insights, allowing teams to address root causes rather than surface-level symptoms.
Use Automated Monitoring and Alerts
Automated monitoring is an essential tool for filling gaps that manual checks might miss. These systems continuously track system performance, flag anomalies, and send alerts when certain thresholds are crossed. This ensures that critical issues are identified and flagged during the crucial early hours after a release.
To get the most out of automation, integration is key. Configure monitoring tools to feed data directly into your review process. For example, when an alert is triggered, the system should automatically log relevant metrics, system states, and events. This pre-collected data allows teams to clearly understand what happened, when it happened, and whether automated responses were effective. By eliminating guesswork, this approach enables teams to focus on targeted solutions.
Combining clear objectives, timely reviews, and automated monitoring creates a solid foundation for post-release analysis. These practices ensure teams can take meaningful follow-up actions and keep improving with every deployment.
Follow-Up Actions and Continuous Improvement
Create Action Plans from Review Findings
A thorough review is only as good as the actions it inspires. To make the most of your findings, turn them into specific, measurable tasks. Instead of vague objectives, set clear goals like: assigning a team member to implement synthetic monitoring alerts for third-party API latency by 5 March 2026, with success defined as alerts triggering within two minutes of a 500ms latency spike.
Timing is crucial - draft action plans within 24–48 hours of the review to ensure the details remain fresh. For each action, include essential details: the risk being addressed, the root cause (using methods like the 5 Whys), the person responsible, a deadline, and a clear success metric. For example, if untested code led to failures, assign a DevOps lead to enforce pre-release testing within seven days, aiming for zero failures in future deployments. Use a risk matrix to prioritise tasks, focusing on issues with the greatest likelihood and business impact. High-impact, high-likelihood risks should always take precedence.
Tracking these tasks is just as important as creating them. Use tools like Jira or similar project management platforms to ensure every action is monitored and completed. This approach keeps everyone accountable and ensures that plans don’t remain just words on a page. The result? Improved system performance and cost savings.
Track Improvements Over Time
To see the real impact of your efforts, monitor key metrics over time. Dashboards in tools like Grafana or Prometheus can help you track monthly indicators such as incident frequency, mean time to recovery (MTTR), deployment success rates, and uptime percentages. Set clear targets - for instance, aiming for a change failure rate below 15% and an MTTR of under one hour.
Compare data from before and after implementing fixes to confirm whether the changes are delivering real benefits. For example, if automated testing was introduced to reduce deployment failures, check whether incidents dropped from 15% to 5% in the following quarters. Measure the financial impact too - like saving £10,000 in downtime over six months. Automated monitoring systems can also provide real-time insights, alerting you if critical thresholds, such as maintaining 99.9% uptime, are at risk. This creates a feedback loop, ensuring continuous improvements in release performance.
Conclusion
Summary of Best Practices
Post-release risk reviews play a crucial role in maintaining system reliability and managing costs effectively. This guide has highlighted key practices that underpin successful risk management, such as conducting reviews promptly, using detailed metrics, and ensuring follow-up actions are practical and measurable. Collaboration is a central theme - teams should feel safe to share insights and address root causes without fear of blame. Comprehensive documentation provides a foundation for tracking progress and identifying areas for improvement, while automated monitoring helps maintain critical thresholds. Regular monthly meetings to review incidents allow organisations to spot trends, resolve outstanding issues, and ensure lessons are applied across the board. These structured methods reduce the likelihood of incidents, speed up resolution times, and foster a culture of ongoing learning, contributing to long-term operational stability.
How Expert Guidance Can Help
Adopting these best practices requires the right mix of tools and expertise. This is where specialised support can make a difference. Hokstad Consulting focuses on DevOps transformation and cloud infrastructure optimisation, offering tailored solutions to integrate these frameworks and metrics into deployment pipelines. Their services include custom automation to accelerate deployment cycles and cut cloud expenses. Whether your organisation operates in public, private, or hybrid cloud environments, expert guidance can help establish consistent review templates, adopt AI-driven monitoring aligned with continuous improvement, and achieve tangible results like quicker recovery times and fewer failed changes. By collaborating with specialists who understand both the technical and cultural challenges of modern DevOps, businesses can turn post-release reviews into proactive opportunities to drive innovation and enhance reliability.
FAQs
What should we review in the first 48 hours after a release?
In the first 48 hours after release, it's crucial to review automated post-deployment validation results, keep an eye on system performance and error rates, and verify that rollback procedures are functioning as expected. These steps help ensure the deployment process runs smoothly and reliably. Prioritise spotting and resolving any major issues quickly to keep the system stable.
Which metrics best prove whether a release actually improved reliability?
Key metrics to determine whether a release has boosted reliability include deployment success rate, change failure rate (CFR), and mean time to recovery (MTTR). These indicators offer a clear picture of the release's stability and performance, enabling teams to pinpoint issues and maintain consistent reliability.
How do we turn review findings into actions that get done?
To make the most of your review findings, start by clearly documenting the lessons learned. Then, prioritise tasks based on their impact and assign specific responsibilities, complete with deadlines. Incorporating automation can help simplify follow-ups, while regular reviews ensure progress stays on track. Lastly, embed these lessons into your everyday workflows to encourage ongoing improvement. These steps help ensure that insights are applied effectively, driving meaningful and lasting changes.