
Managing secrets across multiple Kubernetes clusters is challenging and, if done poorly, can lead to serious risks. Here are the top seven issues you need to address to avoid common pitfalls:
- Inconsistent Secret Sources: Using multiple backends like AWS Secrets Manager or Kubernetes Secrets can result in governance issues and configuration drift. A centralised store with tools like External Secrets Operator (ESO) can help.
- Secret Duplication and Drift: Storing the same secret in multiple clusters increases risks and complicates rotation. Automation tools can streamline synchronisation and reduce errors.
- Weak Encryption: Kubernetes Secrets are only Base64 encoded by default, leaving them vulnerable. Enabling encryption at rest and using KMS v2 for advanced setups is essential.
- Over-Privileged Access: Misconfigured RBAC and overly permissive roles can expose secrets unnecessarily. Limit access with precise configurations and regular audits.
- Poor Secret Lifecycle Management: Static credentials and delayed rotations increase vulnerabilities. Automating rotation with tools like ESO or Vault ensures consistency and security.
- Insecure CI/CD Pipelines: Hardcoding secrets or exposing them via environment variables in pipelines leads to leaks. Use short-lived tokens and separate build-time and runtime secrets.
- Lack of Auditing: Without proper logging, breaches can go undetected. Consolidate logs from all sources and monitor for anomalies to ensure visibility and quick response.
Key takeaway: Centralisation, automation, and strict access controls are critical for securing secrets in multi-cluster environments while maintaining compliance and operational efficiency.
🔒 Kubernetes Secrets Are NOT Secure - Here's How to Fix Them
1. Inconsistent Secret Sources Across Clusters
When clusters rely on different backends for secrets - like AWS Secrets Manager, self-hosted HashiCorp Vault, or Kubernetes Secrets - it creates a fragmented system. This makes governance more challenging, as teams have to juggle multiple configurations, access controls, and rotation practices. The result? Configuration drift. Manual secret distribution causes staging and production credentials to fall out of sync, turning even simple API key rotations into a tedious, multi-step process. Over time, this can lead to what’s known as rotation fatigue
[2][3][9].
This fragmented approach doesn’t just complicate operations - it also makes it harder to maintain the clear, auditable trails required by UK GDPR, which can lead to compliance headaches.
Store secrets centrally, and let ESO synchronize them into every Kubernetes cluster automatically.- Victoria Bisova, DevOps and Cloud Engineer, ITGix [2]
To address this, adopt a centralised secrets store as your single source of truth. Tools like HashiCorp Vault or cloud-native services, paired with the External Secrets Operator (ESO), can automate the injection of Kubernetes Secrets across clusters. By configuring a refresh interval of 5–15 minutes in your ExternalSecret resources, you ensure that any rotated credentials are updated cluster-wide without manual effort. Additionally, ESO's PushSecret API allows hub-cluster secrets to be distributed to shared providers seamlessly [3][5][10].
| Tool | Multi-Cloud Support | Kubernetes Integration | Operational Complexity |
|---|---|---|---|
| HashiCorp Vault | Excellent | Native | High |
| AWS Secrets Manager | Limited | Good | Medium |
| External Secrets Operator | Excellent | Native | Medium |
| Sealed Secrets | Excellent | Native | Low |
| Kubernetes Secrets | Platform-agnostic | Native | Low |
This centralised approach doesn’t just resolve inconsistencies - it also creates a solid foundation for tackling other multi-cluster challenges.
2. Secret Duplication and Drift Between Clusters
Having the same secret stored across multiple clusters significantly increases your risk. If one environment is compromised, attackers can exploit gaps in access policies to move across your infrastructure. This is often called the unknown blast radius problem - when secret storage is fragmented, it becomes nearly impossible to quickly determine which services rely on a compromised credential.
The risks don't stop there. Operational challenges also play a role. Manually copying secrets between clusters leaves no audit trail and often results in configuration drift, where clusters end up running different versions of the same credential. When it's time to rotate secrets, such discrepancies can lead to application failures in clusters that haven't been updated yet.
Manual secret distribution fails to scale. You need automated secret synchronization that maintains security while enabling consistent secret values across your cluster fleet.- Nawaz Dhandala, OneUptime [3]
The solution? Stop treating each cluster as a separate consumer of secrets. Instead, use automation tools like the External Secrets Operator (ESO) with a refreshInterval to regularly sync with your central provider. Combine this with ClusterSecretStore resources so all namespaces in a cluster can reference a single global backend. This setup reduces redundant configurations and simplifies authentication processes [2][12].
When rotating duplicate secrets, use a dual-read/single-write strategy. Introduce the new credential alongside the old one, update all clusters to recognise both, and only retire the old key once every cluster has transitioned successfully. This approach ensures smooth rotations without downtime and avoids race conditions that could disrupt services mid-process [11].
Need help refining your multi-cluster secrets management? Reach out to Hokstad Consulting.
3. Weak or Misconfigured Encryption at Rest and in Transit
Kubernetes Secrets might sound secure, but they’re not. By default, they’re only Base64 encoded - which isn’t encryption at all. It’s a reversible process that offers no real protection.
A common but risky misconception is that Kubernetes Secrets are secure by default. In reality, they're only Base64 encoded. That means there's no cryptographic protection.- Plural.sh [13]
This makes robust encryption practices essential. Without encryption at rest, secrets stored in etcd remain as plaintext, leaving sensitive credentials exposed to anyone with access. A 2026 audit of over 50 production clusters revealed a startling fact: 73% of them had no encryption at rest enabled for etcd [4].
Even when encryption is enabled, misconfigurations can undermine its effectiveness. A key example is the order of providers in the EncryptionConfiguration file. If the identity provider is listed before your encryption provider, new secrets will still be stored as plaintext.
If you put the new key second, everything continues to be encrypted with the old key. Teams may mistakenly add a backup decryption key instead of properly rotating keys.- Aareez Asif, Senior Kubernetes Architect [14]
This makes proper configuration crucial, especially for multi-cluster setups. Keep in mind that enabling encryption at rest only protects new secrets created after the configuration. Existing secrets must be re-encrypted manually, using a command like:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
For production environments, advanced encryption methods are highly recommended. KMS v2, available since Kubernetes v1.29, is a strong option. It uses envelope encryption, where secrets are encrypted with a Data Encryption Key (DEK), which is then encrypted by a Key Encryption Key (KEK) managed by an external service like AWS KMS, Google Cloud KMS, or Azure Key Vault. Importantly, the KEK never leaves the provider, and it’s advisable to rotate it at least every 90 days [15]. Here’s a quick comparison of encryption providers:
| Provider | Key Location | Security Level | Best Use Case |
|---|---|---|---|
| identity | N/A | None | Testing or fallback |
| aescbc | Local file on control plane | Low/Medium | Small clusters with restricted node access |
| kms (v2) | External (AWS, GCP, Azure) | High | Production, multi-cluster, and compliance setups |
Encryption at rest is just one piece of the puzzle. Data in transit requires its own protection. For etcd, ensure TLS peer certificates are configured. To secure pod-to-pod communication, deploying a service mesh like Istio or Linkerd can enforce mutual TLS (mTLS), which is critical for securing traffic across cluster boundaries [6][7]. Addressing both at-rest and in-transit encryption is key to a secure Kubernetes environment.
4. Over-Privileged Access and RBAC Misconfiguration
Even with strong encryption in place, properly configured Role-Based Access Control (RBAC) remains the cornerstone of Kubernetes security. If permissions are overly generous, unauthorised users or services can exploit standard API calls to access sensitive information. While encryption protects secrets, precise RBAC configuration is essential to prevent unauthorised access across clusters.
A 2026 audit of over 50 production clusters revealed some alarming statistics: 67% had overly permissive RBAC settings, and 91% used default service accounts with access to secrets [4]. One frequent oversight involves RBAC verbs. Many engineers mistakenly believe that only the get verb is risky. However, granting permissions like list or watch can be equally hazardous. For instance, the list verb allows retrieval of all secrets within a namespace in one response, significantly increasing exposure. In essence, broad permissions for these verbs can be likened to handing over unrestricted access.
Beyond simple misconfigurations, more complex issues like the confused deputy problem can severely undermine security, particularly in multi-cluster setups. A notable example occurred in January 2026 with a critical vulnerability (CVE-2026-39961) in the Aiven Operator. Its ServiceAccount, which had a ClusterRole for secret operations, failed to validate user-supplied namespace references in Custom Resources. This flaw allowed users with limited access to extract production secrets from any namespace by specifying a target namespace in a ClickhouseUser custom resource. The issue was resolved in version 0.37.0 by introducing SubjectAccessReview checks to validate cross-namespace requests [18].
Minimise secret readers and reduce credential lifetimes.- Eng. Hussein Ali Al-Assaad, Cybersecurity Expert [8]
To address these challenges, organisations should implement the following measures:
- Use
resourceNameswithin RBAC Roles to limit access to specific secrets rather than granting blanket permissions across namespaces [17]. - When using a
ClusterSecretStore, apply anamespaceSelectorto define explicitly which namespaces can access it [16]. - Disable service account token automounting (
automountServiceAccountToken: false) for pods that don’t require API access. - Regularly run
kubectl auth can-i get secrets --all-namespacesto identify identities with cluster-wide secret access [4].
In multi-cluster environments, these RBAC missteps can magnify risks, making stringent access controls absolutely essential.
| RBAC Verb | Risk to Secrets | Recommended Restriction |
|---|---|---|
get |
Reads a specific secret's data | Limit to specific resourceNames
|
list |
Exposes all secrets in a namespace | Restrict to system-level components only |
watch |
Monitors secret changes in real time | Restrict to highly privileged system components |
escalate / bind
|
Allows self-granting of higher permissions | Deny for all non-admin users |
5. Poor Secret Lifecycle Management and Rotation
When secret lifecycle management is neglected, it worsens the risks already present in multi-cluster setups by leaving vulnerabilities exposed for longer periods.
Static credentials that aren't rotated are a major culprit, contributing to over one in three breaches [20]. In multi-cluster environments, this issue becomes even more dangerous. A single compromised credential could potentially provide access to every cluster that shares it.
The reluctance to rotate credentials often isn't due to technical challenges but rather the fear of causing disruptions.
The most common reason credentials don't get rotated is that the last time someone tried, something broke. ... So the 90-day rotation policy becomes a line in a document. And the credential sits unchanged for 18 months.- KubeWright Blog [1]
This hesitation to rotate credentials can have direct compliance implications. Regulations like GDPR, PCI DSS, and SOC 2 mandate regular credential rotation and the ability to maintain clear audit trails. When secrets are managed manually across clusters, these trails can become fragmented, making it nearly impossible to track who accessed what and when during an audit. Offboarding employees is another area prone to errors - without a central inventory of credentials, revoking access often becomes a guessing game.
Automation offers a scalable solution. Tools like External Secrets Operator (ESO) can be configured with a 15-minute refreshInterval, allowing updated secrets to be automatically pulled from a central store - such as HashiCorp Vault or AWS Secrets Manager - and distributed to all clusters without manual effort [3][11]. HashiCorp Vault's dynamic secrets feature adds another layer of security by generating unique, short-lived credentials for each workload, significantly narrowing the window of opportunity for attackers [3][11].
For rotation without downtime, deploy the new secret alongside the old one, update applications to recognise both, and retire the old secret only after confirming the new one works [11]. To catch sync issues early, set up a Prometheus alert for externalsecret_sync_calls_error > 0 [3].
If a cluster can't decrypt its secrets after a rushed key change, it could result in major outages - something no team wants to face.
Here’s a comparison of rotation methods and their associated downtime risks:
| Rotation Method | Mechanism | Downtime Risk |
|---|---|---|
ESO refreshInterval |
Polls external store on a schedule | Near-zero (eventual consistency) |
| Vault Dynamic Secrets | Generates unique credentials per pod/lease | Zero (unique per consumer) |
| Sealed Secrets | Requires re-sealing and Git commit | Requires rollout |
| SOPS | Requires re-encryption and Git commit | Requires rollout |
Managing the lifecycle of secrets effectively strengthens your overall multi-cluster security strategy, working hand in hand with centralised management and access control.
6. Insecure Secrets Handling in CI/CD Pipelines
When it comes to managing secrets securely, CI/CD pipelines often present significant challenges. These pipelines are a frequent source of secret exposure. In 2026 alone, 29 million secrets were discovered on public GitHub, with 28% of them still active at the time of discovery [19]. This underscores how critical it is to rethink how secrets are managed during the CI/CD process.
One of the biggest issues is the practice of hardcoding secrets into files like .env, values.yaml, or base64-encoded Kubernetes manifests. Base64 encoding provides no real security, and secrets committed to Git are essentially permanent. In fact, an audit conducted in 2026 revealed that 44% of production clusters had secrets stored in Git repositories [4]. Similarly, embedding credentials like API keys or service account tokens into container images during builds creates vulnerabilities that often remain undetected until it’s too late [19].
Environment variables are another common weak point. Secrets stored in these variables can easily end up exposed through crash dumps, logs, or process listings. Alarmingly, 82% of audited production clusters were found to expose secrets via environment variables [4]. A simple but effective mitigation strategy is to mount secrets as files with restricted permissions (e.g., 0400) to limit access [4][22].
Zero-trust is a philosophy, but secrets management is where it either lives or dies in practice. If you're still handing credentials to the applications through environment variables and relying on chance, this post is for you.- Zak Hassan, Staff SRE [22]
To address these vulnerabilities, moving from static credentials to short-lived identity tokens is one of the most effective solutions. By integrating clusters with an OIDC provider like AWS IAM or Okta, pipeline runners can assume temporary roles instead of relying on long-term keys. This approach reduces the exposure window from months or years to just minutes [19]. Additionally, aligning token TTLs (time-to-live) with the actual duration of jobs, rather than defaulting to a 24-hour period, makes compromised tokens nearly useless before they can be exploited [21].
Another important step is separating build-time secrets (e.g., registry tokens, signing keys) from runtime secrets (e.g., application credentials). This ensures that even if a build runner is compromised, production credentials remain safe [8]. Combining these measures with earlier strategies significantly reduces the risks associated with static secret distribution across clusters.
7. Lack of Auditing and Incident Response for Secrets
Many teams mistakenly believe that breaches will be obvious when they occur. However, in reality, 78% of audited production clusters lack audit logging for secrets access [4]. Without proper visibility, leaked credentials can go unnoticed for extended periods, often only being discovered after significant damage has been done. That’s why centralising and correlating logs is so important.
The problem is compounded by fragmented audit logs spread across Kubernetes API servers, Vault, AWS CloudTrail, and GitOps tools. Even with central SIEM integrations, investigating incidents can be painfully slow. For instance, tracing secret access over the last 90 days might take days of manual work [23]. To audit effectively, teams need to combine data from multiple sources - Kubernetes API audit logs, GitOps sync logs, secret provider trails, and runtime monitoring - and send it all to a central SIEM using an OpenTelemetry Collector [24][25]. Just like encryption and RBAC, proper auditing is a critical piece of comprehensive multi-cluster secrets management.
You can't protect what you can't see, and most organisations cannot see where their production secrets live.- Phillip (Tre) Bucchi, Founder, Valtik Studios [24]
Once audit trails are consolidated, even small anomalies should trigger immediate action. For example, a single token accessor reading an unusually high number of secrets, access from an unexpected IP, or the creation of a token with root privileges are all red flags that demand investigation [8][22].
| Monitoring Signal | Risk Indicated | Recommended Action |
|---|---|---|
| High error rates from one token | Credential stuffing or misconfiguration | Investigate the source IP and revoke the token if necessary [22] |
| Access to paths outside normal patterns | Lateral movement or compromised service | Review service account permissions and restrict access scope [22] |
| Token creation with root policy | Unauthorised administrative escalation | Alert immediately; this should only happen during break-glass scenarios [22] |
| Multiple lease revocations | Potential Denial of Service (DoS) attack | Confirm if part of legitimate rotation; if not, initiate incident response [22] |
A formal incident response plan is non-negotiable. Teams should create and test credential rotation playbooks in advance, ensuring that secrets can be rotated across clusters automatically without disrupting services [8]. Proactive secret lifecycle management, as discussed earlier, is the best defence against turning a leaked credential into a full-blown crisis.
One practical step is configuring Kubernetes audit policies to log at the Metadata level for secret resources. This approach captures who accessed a secret and when, without exposing the actual secret values - keeping the audit trail clean and actionable [25][4].
Comparison Table
::: @figure 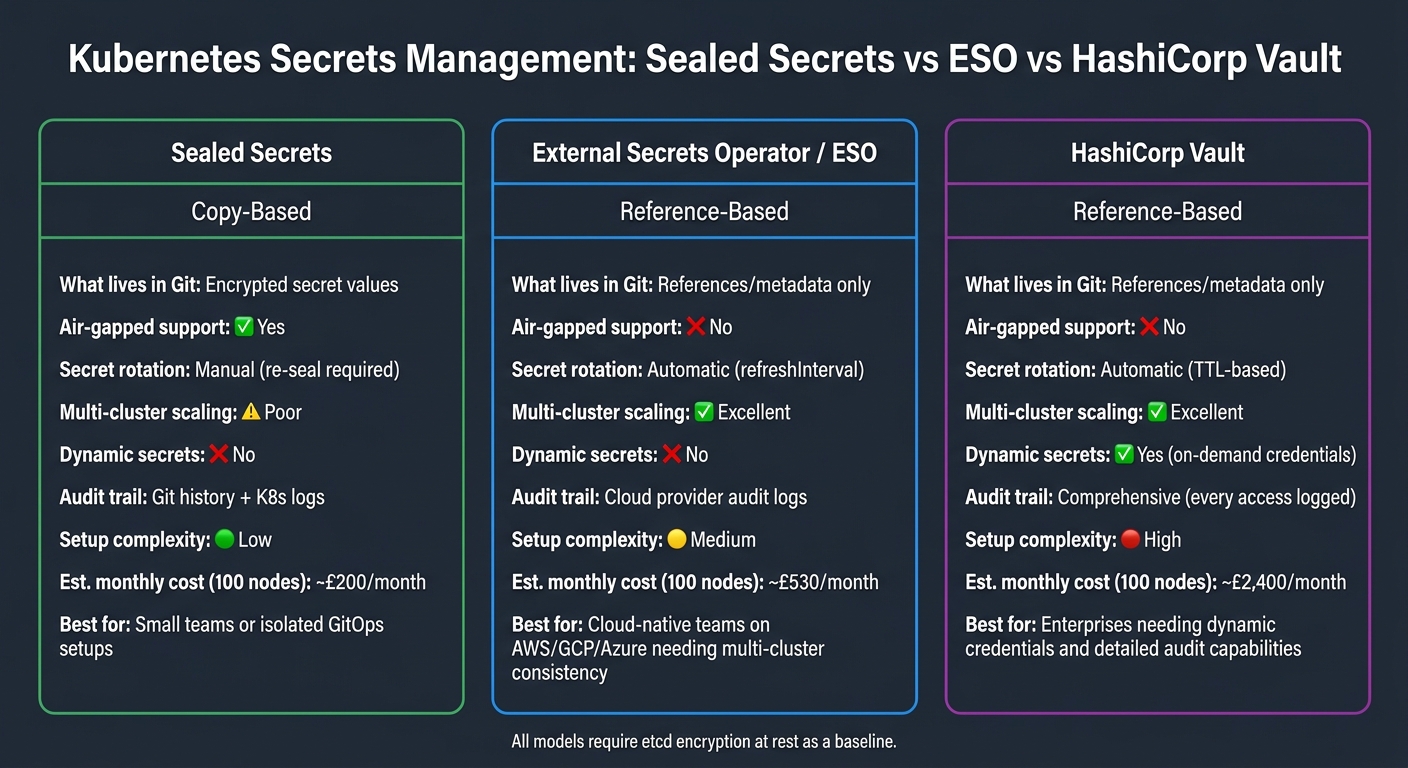 {Kubernetes Secrets Management: Sealed Secrets vs ESO vs HashiCorp Vault}
:::
{Kubernetes Secrets Management: Sealed Secrets vs ESO vs HashiCorp Vault}
:::
When choosing the right secrets management model for your environment, it's important to weigh risks like secret drift, weak encryption, and insufficient auditing. There are two primary approaches: copy-based and reference-based, each with its own pros and cons. Here's a breakdown of their differences.
A copy-based approach, such as Sealed Secrets, involves encrypting secret values and committing them directly to Git. Decryption is handled by a controller within each cluster. This method is self-contained, works well in air-gapped environments, and is relatively easy to implement. The estimated cost is around £200 per month for 100 nodes [27]. However, secret rotation requires manual re-sealing and new Git commits, and scaling across multiple clusters is limited due to the use of cluster-specific keys [27].
On the other hand, reference-based solutions, like External Secrets Operator (ESO) or HashiCorp Vault, store only metadata or paths in Git, retrieving the actual secret values at runtime from a centralised store. As Nawaz Dhandala explains:
Reference-based methods scale better as one central store can serve an unlimited number of clusters.[26]
This approach supports features like automatic secret rotation (refreshInterval for ESO and TTL-based for Vault), centralised audit logs, and better multi-cluster management. However, it comes with higher setup complexity and costs - ESO costs approximately £530 per month, while Vault costs around £2,400 per month for 100 nodes [27].
Here’s a detailed comparison:
| Feature | Sealed Secrets (Copy-based) | ESO (Reference-based) | HashiCorp Vault (Reference-based) |
|---|---|---|---|
| What lives in Git | Encrypted secret values | References/metadata only | References/metadata only |
| Air-gapped support | ✅ Fully supported | ❌ Not possible | ❌ Not possible |
| Secret rotation | Manual (re-seal required) | Automatic (refreshInterval) |
Automatic (TTL-based) |
| Multi-cluster scaling | Poor (cluster-specific keys) | Excellent (one central store) | Excellent (centralised Vault) |
| Dynamic secrets | ❌ No | ❌ No | ✅ Yes (on-demand credentials) |
| Audit trail | Git history + K8s logs | Cloud provider audit logs | Comprehensive (every access logged) |
| Setup complexity | Low | Medium | High |
| Est. monthly cost (100 nodes) | ~£200/month | ~£530/month | ~£2,400/month |
The best choice depends on your organisation's scale and needs. Sealed Secrets is ideal for small teams or isolated setups new to GitOps [27]. ESO works well for cloud-native teams already using AWS, GCP, or Azure secret managers, especially when multi-cluster consistency is a priority [27]. For enterprises requiring dynamic credentials and detailed audit capabilities, HashiCorp Vault is the go-to solution [27]. Regardless of the model, remember that enabling etcd encryption at rest is critical, as all models ultimately rely on Kubernetes Secrets stored in etcd [27].
Conclusion
These seven risks don’t just exist in isolation - they build on one another, creating a much larger vulnerability. Together, they underscore the pressing need for a well-rounded approach. As the KubeWright Blog aptly states:
If your team tried to rotate every credential today, something would break. Not because your engineers are careless. Because your secrets are everywhere.[1]
When unsafe rotation practices allow outdated credentials to linger for months - or even years - the risks multiply. Combine that with inconsistent access controls and a lack of proper auditing, and a single compromised credential can enable lateral movement long before anyone realises the extent of the damage.
The solution lies in a structured model: a centralised store, consistent synchronisation (using tools like External Secrets Operator), clear ownership, and automated rotation. As James Walker, Founder of Heron Web, points out, Secrets sprawl rarely appears in isolation... It tends to accompany broader workflow problems like poor environment management and hardcoded configuration values
[28]. It’s a reminder that tools alone can’t fix these issues - strong processes are just as critical.
A well-governed approach not only improves security but also scales effortlessly. With the right architecture, managing 200 clusters can require no more effort than managing two [2]. That’s the real-world advantage of getting this right - achieving both security and operational efficiency.
Addressing these interconnected risks with a clear strategy is essential for securing multi-cluster environments. Centralised management and automated rotation, as outlined earlier, can simplify security at scale. If you’re uncertain about your organisation’s current position, Hokstad Consulting offers expertise in optimising DevOps and cloud infrastructure, with a focus on multi-cluster secrets management.
FAQs
What’s the safest way to share secrets across multiple Kubernetes clusters?
Using a centralised external secret store, such as HashiCorp Vault or a managed cloud secret manager, alongside the External Secrets Operator (ESO), is the safest way to handle secrets. This setup allows clusters to fetch secrets dynamically, eliminating the need for manual synchronisation.
To implement this, deploy ESO to each cluster and configure it to reference the backend through ClusterSecretStore resources. This method offers several advantages, including:
- Automated secret rotation: Secrets are updated automatically without manual intervention.
- Robust audit trails: Maintain a clear record of secret access and changes.
- Enhanced security: Avoid hardcoding secrets or storing plaintext secrets in version control.
This approach ensures a secure and efficient way to manage secrets across your clusters.
How can I rotate secrets across clusters without causing downtime?
To ensure secrets are rotated without causing downtime, centralise them in a single, secure vault and rely on automation to handle distribution - this reduces the risk of human error. Tools like the External Secrets Operator (ESO) can help by synchronising secrets into Kubernetes and setting automated refresh intervals.
For sensitive credentials, consider a staged approach to rotation. Start by introducing updated versions of the credentials while keeping the old ones active. Allow both versions to be used temporarily, conduct canary testing to ensure everything works smoothly, and then fully transition to the new credentials before finally revoking the outdated keys.
What should I audit to detect secrets abuse in multi-cluster setups?
Auditing access permissions and usage patterns across all clusters is essential for maintaining security. Begin by reviewing Role-Based Access Control (RBAC) configurations. Look for service accounts with excessive permissions or cluster-wide secret access, as these can pose significant risks.
Leverage Kubernetes audit logs to track secret access in real-time. This helps identify unusual activity, such as unexpected reads, which could indicate a security issue. Additionally, verify that secrets are not being exposed through insecure methods, like environment variables, which can inadvertently compromise sensitive data.
For environments with greater complexity, it might be worth seeking expert advice. Centralising auditing processes and securing credentials can streamline oversight and reduce vulnerabilities effectively.