
Managing Kubernetes clusters efficiently can save UK businesses up to 60% in cloud costs. Many organisations waste resources due to over-provisioning, uneven utilisation, and governance gaps. For example, a mid-sized UK company running three clusters at 40% utilisation may lose £150,000–£300,000 annually.
To fix this, focus on:
- Workload rightsizing: Adjust CPU/memory requests and limits based on usage data.
- Node autoscaling: Use tools like Cluster Autoscaler or Karpenter for efficient scaling.
- Governance: Apply GitOps and Policy-as-Code to maintain consistency and security.
Rightsizing requires balancing cost savings with performance, while addressing challenges like resource waste, synchronisation issues, and compliance risks. Tools like ArgoCD, Kyverno, and AI-driven analytics can simplify these efforts, ensuring better utilisation and reduced spending.
Hokstad Consulting offers tailored solutions to optimise multi-cluster environments, helping businesses cut costs by 30–40% while improving reliability and compliance.
Common Challenges in Multi-Cluster Rightsizing
Over-Provisioning and Resource Waste
It's common for teams to allocate more resources than necessary due to a lack of clear insight into actual usage. This often results in clusters running at just 20–40% of their CPU capacity [5]. Each cluster has its own control plane, which includes API servers, schedulers, and controllers. These components consume CPU, memory, and storage regardless of how much workload the cluster is handling [2]. When this fixed overhead is multiplied across several clusters, the waste adds up quickly.
Another issue is the use of inconsistent node types, which complicates workload placement and forces teams to maintain extra capacity [4]. Even if a cluster has enough total resources, fragmented resource availability can prevent pods from being scheduled efficiently. This mismatch not only increases infrastructure costs but also leaves resources unused.
While over-provisioning leads to resource waste, uneven utilisation spreads the performance and cost burdens unevenly across clusters.
Inconsistent Utilisation Across Clusters
After tackling over-allocation, uneven resource usage emerges as another challenge. It's not unusual for one cluster to be running at full capacity while another remains mostly idle, yet both incur similar fixed costs. This imbalance often arises from workload distribution decisions that don't take into account the actual capabilities of each cluster or changing demand patterns. Additionally, network latency between geographically distributed clusters can cause synchronisation problems, resulting in inconsistent application performance [2].
Underutilised clusters drive up costs, while overloaded clusters face issues like latency and reduced reliability. Tools like ArgoCD or Flux, which are part of the GitOps approach, can help prevent configuration drift that contributes to these inconsistencies [1][3]. However, many organisations still rely on manual management of clusters, allowing variations to accumulate over time. Real-time monitoring plays a crucial role in balancing workloads effectively. Using proper rightsizing tools can lead to infrastructure savings of 25% to 60% [4].
Governance and Security Gaps
Managing policies across multiple clusters is no easy task. Basic controls such as Namespaces, RBAC, and ResourceQuotas provide only limited protection [6]. These measures are insufficient to prevent more sophisticated threats like pod-to-pod network attacks or kernel exploits, which become more dangerous as the number of clusters grows.
Misconfigured controllers or buggy operators can overwhelm the API server, potentially crippling the control plane [6]. Shared resources further magnify these vulnerabilities. For example, in March 2025, 43% of cloud environments were exposed to CVE-2025-1974 (IngressNightmare), highlighting how security gaps can rapidly affect multi-cluster deployments [6]. The retirement of the ingress-nginx project in March 2026 left organisations still relying on it vulnerable to unpatched issues [6].
The promotion of Kyverno to a CNCF top-level project in March 2026 underscores the growing importance of declarative policy enforcement for managing production-scale multi-cluster environments [6]. Without adopting consistent policy-as-code frameworks, organisations face increased compliance risks, more challenging audits, and a higher likelihood of security incidents.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Best Practices for Multi-Cluster Rightsizing
Implement Workload and Namespace Rightsizing
Did you know that most Kubernetes clusters operate at just 20–40% of their capacity? [8] This inefficiency can be addressed by fine-tuning CPU and memory requests and limits to align with actual usage. CPU requests determine pod scheduling, while limits cap runtime usage [7].
To get started, collect 14 days of usage data and focus on P95 or P99 metrics instead of averages [8]. For CPU, set requests at P95 usage with an added 20% buffer. For memory, use P95 usage with a 25% buffer to avoid out-of-memory errors [8]. This approach strikes a balance, preventing both over-provisioning (idle resources) and under-provisioning (throttling or crashes).
At the namespace level, tools like ResourceQuota and LimitRange come in handy. ResourceQuota caps overall resource consumption across CPU, memory, and pod counts, while LimitRange enforces default values and per-container constraints. Always apply LimitRange first to inject default values before ResourceQuota checks are performed [7]. For rolling updates, set namespace quotas 20–30% above steady-state usage to allow for the temporary overlap of old and new pods [7]. To stay ahead of potential issues, configure alerts to trigger when any quota dimension reaches 85% utilisation [7].
| Feature | LimitRange | ResourceQuota |
|---|---|---|
| Scope | Individual Pods/Containers | Aggregate Namespace Total |
| Enforcement | Injects defaults and sets ceilings | Rejects requests exceeding total cap |
| Primary Goal | Prevents oversized pods and sets defaults | Avoids resource starvation for other teams |
When workloads are properly sized, node scaling becomes far more efficient.
Integrate Node Autoscaling with Cluster Autoscaler and Karpenter
Node autoscalers play a key role in managing multi-cluster environments. They add nodes for unschedulable pods and remove underutilised ones, addressing the common challenge of balancing underutilisation and over-provisioning [9].
The Cluster Autoscaler works with existing node group configurations, while Karpenter uses cloud APIs to provision individual VMs directly, based on NodePool constraints [9][10]. Karpenter offers faster, more precise scaling and manages the full node lifecycle, including upgrades and refreshes [9].
- Use Cluster Autoscaler for broad multi-cloud support or when working with predefined node groups.
- Choose Karpenter for flexible, on-demand provisioning, especially on AWS or Azure [9].
Both tools perform best when paired with accurately rightsized workloads. Correct resource requests ensure that autoscalers allocate just the right amount of node capacity - neither too much nor too little.
Adopt GitOps and Policy-as-Code for Consistent Governance
Beyond optimising resources, maintaining configuration consistency across clusters is essential. GitOps ensures that cluster configurations are version-controlled and auditable by using Git repositories as the single source of truth. Tools like Argo CD and Flux continuously reconcile the desired state in Git with the actual cluster state, correcting manual changes that could lead to resource waste or instability. This approach has been shown to improve infrastructure reliability by 62% [12].
Configuration consistency at scale depends on treating cluster state as code and enforcing reconciliation continuously.– Hari Chandrasekhar, Content Writer, Sedai [11]
To streamline the process, automate pull requests with recommended CPU and memory values, creating a reviewable audit trail. Additionally, use admission controllers like OPA or Kyverno to ensure every deployment includes defined resource requests and limits before entering the cluster. Enforce consistent labelling (e.g., team, project, cost-centre) through Policy-as-Code to make it easier to attribute rightsizing data to specific budgets or teams.
Lessons Learned: Running Kubernetes Multi-Tenant, Multi-Cluster at... Michael Shelton & Allen Serhat
Comparison of Rightsizing Strategies
::: @figure 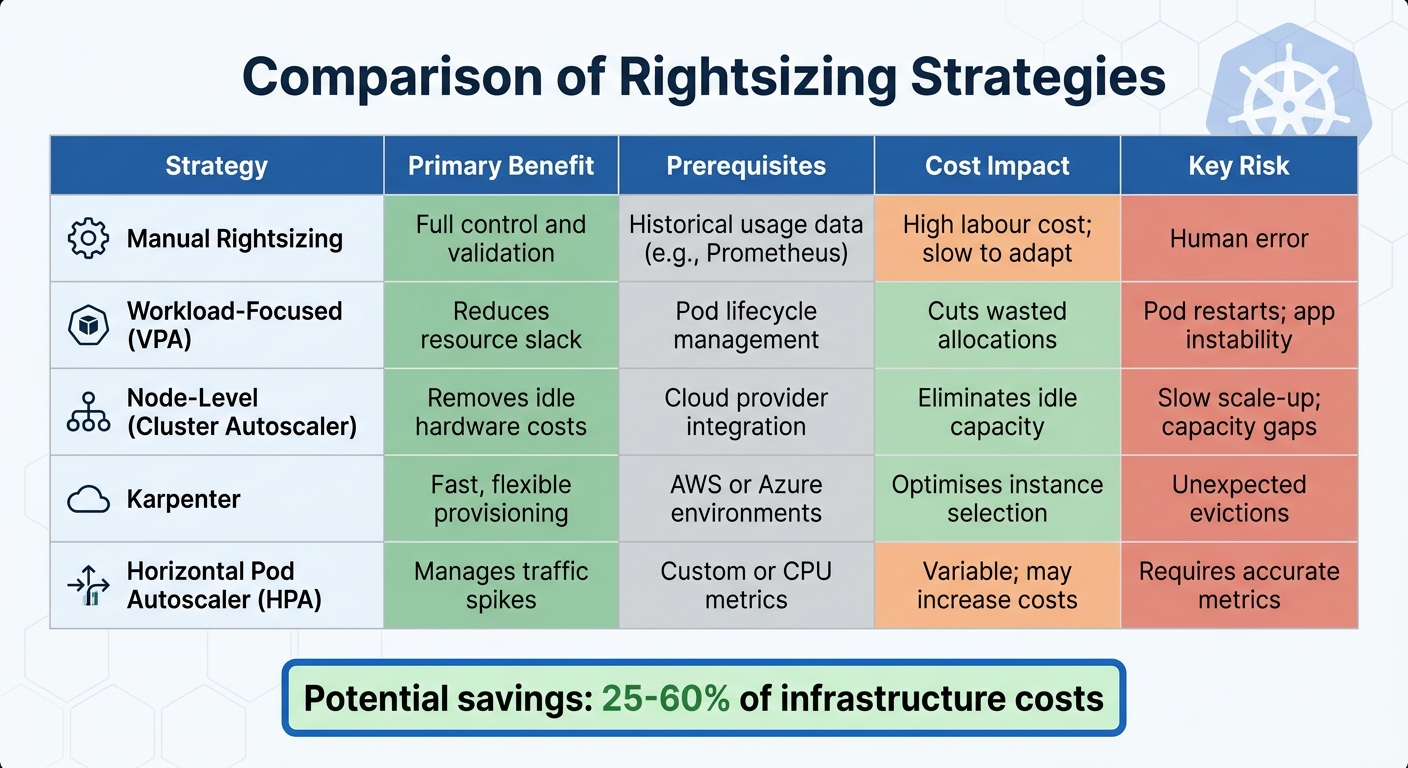 {Kubernetes Multi-Cluster Rightsizing Strategies Comparison}
:::
{Kubernetes Multi-Cluster Rightsizing Strategies Comparison}
:::
Building on the earlier best practices, comparing various rightsizing strategies can help you determine which approach works best for your multi-cluster setup. This kind of analysis ensures your chosen strategy aligns well with your team's goals and operational requirements.
The right strategy depends on factors like your team's capacity, the complexity of your clusters, and how much automation you're willing to adopt. For instance, workload-focused rightsizing adjusts CPU and memory settings at the pod level to cut down on slack. On the other hand, node-level strategies focus on adding or removing nodes to eliminate idle capacity. Both methods can lead to savings in the range of 25–60% [4].
However, the complexity of implementation differs. Workload rightsizing might cause pod restarts when changes are applied, potentially clashing with the Horizontal Pod Autoscaler (HPA). Node-level rightsizing, meanwhile, requires integration with cloud provider APIs and careful handling of Pod Disruption Budgets to ensure availability during scaling.
| Strategy | Primary Benefit | Prerequisites | Cost Impact | Key Risk |
|---|---|---|---|---|
| Manual Rightsizing | Offers full control and validation | Historical usage data (e.g., Prometheus) | High labour cost; slow to adapt | Human error |
| Workload-Focused (VPA) | Reduces resource slack | Requires pod lifecycle management | Cuts wasted allocations | Pod restarts; potential app instability |
| Node-Level (Cluster Autoscaler) | Removes idle hardware costs | Needs cloud provider integration | Eliminates idle capacity | Slow scale-up; potential capacity gaps |
| Karpenter | Enables fast, flexible provisioning | Works in AWS or Azure environments | Optimises instance selection | Risk of unexpected evictions |
| Horizontal Pod Autoscaler (HPA) | Manages traffic spikes effectively | Relies on custom or CPU metrics | Variable; may increase costs | Requires accurate metrics for efficiency |
When optimising nodes, it’s also essential to account for DaemonSets. These consume fixed resources and can impact capacity calculations [4].
This comparison provides a foundation for understanding how Hokstad Consulting can assist in simplifying multi-cluster rightsizing further.
How Hokstad Consulting Can Help with Multi-Cluster Rightsizing

Hokstad Consulting offers practical solutions to the challenges of multi-cluster rightsizing, focusing on tackling over-provisioning and uneven resource use. Their approach blends cloud cost engineering, DevOps transformation, and AI automation to address the specific needs of managing Kubernetes clusters. By starting with in-depth cluster assessments, they identify utilisation trends, workload distributions, and performance baselines across your Kubernetes environment. For organisations managing anywhere from 5 to over 20 clusters, this process can streamline operations by 30–40% and enhance cost predictability.
Their process combines automated tools with manual audits. Continuous monitoring of resource usage across all clusters is conducted using observability tools, complemented by AI-driven analytics. These tools identify idle or underutilised nodes and pods, allowing Hokstad Consulting to pinpoint inefficiencies in resource allocation. They then quantify these inefficiencies and present detailed remediation plans, complete with projected ROI figures in GBP.
AI plays a key role in their strategy. By analysing workload patterns, their AI agents predict future needs and recommend scaling policies tailored to your business goals. This approach typically achieves a 25–35% reduction in monthly cloud expenses, accelerates deployment cycles by 40–50%, and improves utilisation rates from 30–40% to 60–75%. Importantly, these gains are accomplished without compromising application performance or reliability.
To ensure long-term success, Hokstad Consulting implements robust governance frameworks using Policy-as-Code and GitOps principles. These frameworks ensure consistent and auditable infrastructure changes across all clusters. For UK organisations, this often includes adopting ITIL-aligned change management processes and setting up cost centres that reflect the company’s structure. Such measures help prevent a return to inefficient practices, ensuring that rightsizing efforts remain effective over time.
Their engagement process is structured into clear phases:
- Discovery: 2–3 weeks
- Planning: 1–2 weeks
- Implementation: 4–8 weeks
- Ongoing Optimisation
The total engagement spans 8–16 weeks, with detailed monthly cost reporting in GBP to keep stakeholders informed.
Conclusion
Managing resources effectively across multiple clusters requires a careful balance of workload optimisation, governance, and automated scaling. Over-provisioning and uneven resource use can inflate cloud expenses by as much as 30–50%. Tackling these inefficiencies with a structured strategy can lead to noticeable gains in both cost savings and operational effectiveness.
The starting point is implementing workload and namespace rightsizing alongside node autoscaling. But technical fixes alone won’t deliver lasting results. Strong governance practices, such as GitOps and Policy-as-Code, are critical for maintaining security and avoiding configuration drift. By storing configurations centrally and automating reconciliation with tools like ArgoCD or Flux, organisations can ensure compliance and maintain a clear audit trail for changes [1][3][13].
AI-driven analytics have further revolutionised rightsizing. These tools shift the process from manual adjustments to proactive resource management, offering precise scaling recommendations based on predicted workload demands. This not only improves resource efficiency but also ensures application reliability.
For organisations managing multiple Kubernetes clusters, expert consulting services can fast-track these improvements. Hokstad Consulting, for example, offers a methodical approach that covers discovery, planning, implementation, and continuous optimisation. Their focus on detailed monthly cost reporting in GBP and robust change management processes ensures that improvements are both measurable and sustainable.
FAQs
How do I choose safe CPU and memory requests for each workload?
To determine safe CPU and memory requests, rely on actual resource usage data. Use tools like Prometheus or Grafana to examine both real-time and historical metrics, helping you pinpoint typical consumption trends. A good starting point is setting requests slightly above the average usage - this keeps things stable without wasting resources. For ongoing adjustments, consider automated solutions like the Vertical Pod Autoscaler (VPA). Regularly monitor workloads to ensure resources remain optimally allocated.
When should I use Cluster Autoscaler vs Karpenter across multiple clusters?
In a multi-cluster Kubernetes setup, Cluster Autoscaler is a dependable choice for scaling nodes within individual clusters. It works best for workloads that are stable or relatively predictable. As a mature solution, it integrates seamlessly with Kubernetes, providing consistent performance.
On the other hand, opt for Karpenter if you're dealing with dynamic, multi-cluster environments or require faster scaling and more precise resource allocation. It's particularly effective in hybrid or multi-cloud setups, helping to cut costs and boost efficiency by offering fine-tuned resource provisioning and quick adaptation to workload fluctuations.
How can GitOps and Policy-as-Code stop rightsizing drift over time?
GitOps and Policy-as-Code work together to prevent rightsizing drift by automating resource management and enforcing policies. With GitOps workflows, such as those powered by Flux CD, resource adjustments are carefully reviewed and tracked, ensuring transparency and control. Meanwhile, Policy-as-Code establishes and validates the best resource allocations based on predefined rules. This combination creates a continuous feedback loop that monitors, updates, and applies changes, keeping rightsizing accurate and helping to manage costs effectively over time.