
Scaling in Kubernetes depends on whether your application is stateful or stateless. Each comes with its own challenges and benefits:
- Stateless Applications: These are easier and faster to scale. They don’t rely on persistent storage or stable pod identities, making them ideal for workloads like web servers or APIs. Scaling happens in parallel, taking seconds, and helps reduce cloud costs by matching resources to demand.
- Stateful Applications: These require persistent storage and consistent pod identities (e.g., databases, Kafka). Scaling is slower since pods are created sequentially and involve storage attachment delays, which can take 10–60 seconds per pod. They prioritise data consistency over speed.
Key Differences
- Scaling Speed: Stateless apps scale quickly in parallel; stateful apps scale sequentially with delays.
- Resource Use: Stateless apps optimise resource usage; stateful apps may leave nodes underutilised during scaling.
- Cost Management: Stateless apps handle traffic spikes efficiently, while stateful apps risk over-provisioning due to slower scaling.
Takeaway: Use stateless scaling for flexibility and cost efficiency. For persistent data needs, stateful scaling is necessary but requires careful configuration to minimise delays and costs.
::: @figure 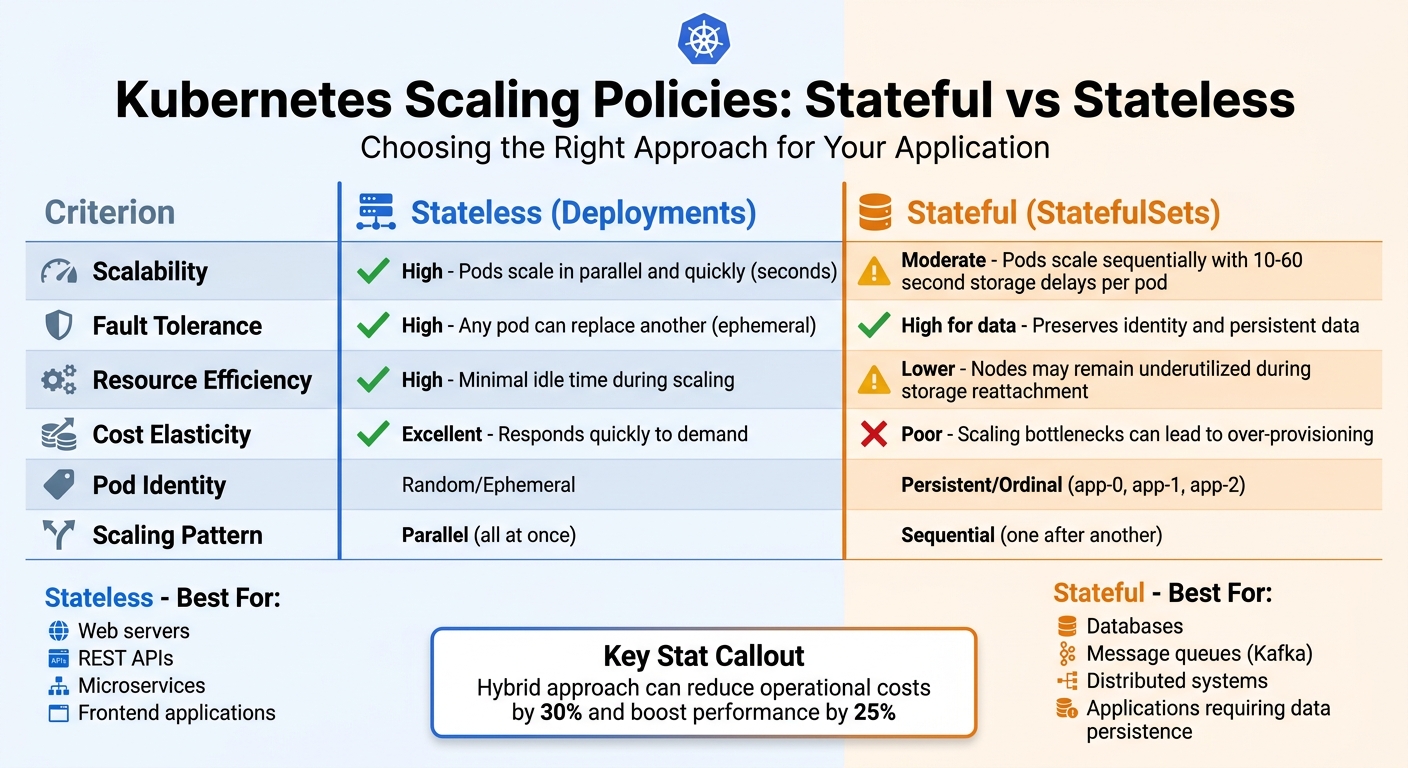 {Kubernetes Stateless vs Stateful Scaling: Key Differences Comparison}
:::
{Kubernetes Stateless vs Stateful Scaling: Key Differences Comparison}
:::
Stateless vs Stateful in Kubernetes: Key Differences Explained (Deployments vs StatefulSets)
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
1. Stateful Applications in Kubernetes
Stateful applications in Kubernetes rely on StatefulSets to maintain persistent storage and consistent pod identities. Unlike stateless applications, which don't retain data between sessions, stateful applications - like databases, message queues, and distributed systems - require their data to persist even after pod restarts. This makes their orchestration more complex, especially when scaling.
Scalability
StatefulSets scale in a specific order: each pod is created only after the previous one becomes operational [5][7]. While this ensures data consistency, it can slow down the scaling process, particularly during sudden traffic surges.
One common bottleneck is storage attachment delays, which can take anywhere from 10 to 60 seconds per pod. When scaling sequentially, these delays add up, reducing the system's ability to handle sudden increases in demand [1].
Another challenge comes from topology constraints. Persistent volumes are often tied to specific Availability Zones, which can lead to scheduling delays if a pod is placed in the wrong zone [1]. To address this, configure your storage classes with volumeBindingMode: WaitForFirstConsumer. This ensures that volumes are provisioned in the same zone as their pods, reducing scheduling conflicts [1]. These measures also play a role in maintaining fault tolerance during scale-down operations.
Fault Tolerance
When scaling down, Kubernetes follows a strict order: it only removes pods once all are healthy, and it terminates the highest-numbered pod first [4][5]. To maintain stability, use Pod Disruption Budgets and preStop lifecycle hooks. These tools allow the application to redistribute data across remaining pods before a pod is terminated, ensuring data consistency [4].
Resource Efficiency
The sequential nature of scaling can lead to underutilised nodes, particularly during the volume attachment process [1]. As Ilya Pisatzkov, Solution Architect at Zesty, explains:
Stateful workloads frequently become the largest bottleneck in cluster scaling, introducing delays that slow down the entire environment[1].
To avoid such inefficiencies, consider running stateful services on dedicated node pools. This separation allows you to fine-tune resources for stateful workloads without affecting the performance of stateless applications [1]. This strategy can help mitigate the challenges of scaling while maintaining resource efficiency.
Cost Elasticity
The slower scaling and placement constraints of stateful applications can result in excess replicas during periods of low demand. To manage costs, implement conservative HPA (Horizontal Pod Autoscaler) policies for StatefulSets. For instance, add only one pod at a time and use stabilisation windows of 300–900 seconds to allow data rebalancing [4]. While this approach may reduce immediate responsiveness, it prevents costly scaling fluctuations and ensures overall system stability.
2. Stateless Applications in Kubernetes
Stateless applications - like APIs, web servers, and microservices - operate differently from stateful ones. They don’t store data between sessions or rely on external dependencies such as persistent storage. This makes their pods fully interchangeable[8]. Kubernetes can effortlessly create or destroy these pods without worrying about which specific instance handles a request. This flexibility makes them perfect for dynamic scaling, which, in turn, helps reduce cloud costs by matching resources to demand.
Scalability
One of the standout benefits of stateless applications is how quickly they can scale. Unlike StatefulSets, which require pods to start sequentially (e.g., pod-0 must be ready before pod-1 starts), Deployments allow all replicas to launch simultaneously. This means scaling from 3 to 30 pods can happen in seconds instead of minutes, as there’s no waiting for volume attachments or data rebalancing[4].
The Horizontal Pod Autoscaler (HPA) plays a critical role here. By default, it checks metrics every 15 seconds and adjusts the number of replicas based on demand[9]. Kubernetes also includes a 10% tolerance to avoid unnecessary scaling actions. To ensure the HPA works effectively, always define CPU and memory requests - these serve as the baseline for utilisation calculations[9][2]. For services with longer startup times, like Java-based applications, use startupProbes to prevent the HPA from misinterpreting initial CPU spikes as genuine demand[9]. This ensures scaling is both quick and reliable, backed by fault tolerance for smooth scale-downs.
Fault Tolerance
Scaling down stateless applications is straightforward because their pods are identical and disposable[8]. The default 300-second stabilisation window prevents rapid fluctuations by avoiding unnecessary pod creation or deletion due to minor metric changes[9]. You can fine-tune this behaviour using the behavior field in the autoscaling/v2 API. For instance, you could set policies to limit pod removal to just 10% per minute[9]. This is much simpler than scaling down stateful applications, which often require careful handling to redistribute data.
Resource Efficiency
Pairing the HPA with the Vertical Pod Autoscaler (VPA) ensures efficient resource use. While the HPA handles traffic surges by adding pods, the VPA adjusts CPU and memory requests for individual pods based on historical usage data[10][2]. For pods running sidecars - like logging agents or service mesh proxies - it’s important to configure the HPA to monitor only the main container. This avoids unnecessary scaling triggered by sidecar resource usage[9]. Unlike stateful applications, which often require dedicated node pools, stateless workloads can share cluster resources more flexibly.
Cost Elasticity
Efficient resource allocation also supports cost savings. For workloads with predictable quiet periods, the rapid scaling capabilities of stateless applications allow for effective cost management. Instead of relying solely on CPU or memory metrics, you can use the custom.metrics.k8s.io API to scale based on meaningful signals like request latency or queue length. The HPA’s 30-second initial readiness delay ensures scaling decisions are based on actual application readiness, not temporary fluctuations during startup[9][4]. This method ensures that resources align with real demand, unlike the more cautious scaling policies needed for stateful workloads.
Advantages and Disadvantages
This section breaks down the main trade-offs between stateful persistence and stateless flexibility, highlighting the key points from the earlier discussion. The comparison below captures the advantages and limitations of each scaling policy.
When deciding between stateful and stateless scaling, it's all about weighing these trade-offs. Stateless applications are champions of elasticity - they can scale quickly and in parallel, often within seconds, as they don't rely on external dependencies[1]. This makes them perfect for unpredictable traffic spikes while keeping cloud costs in check. On the other hand, stateful applications prioritise data persistence, maintaining stable network identities and dedicated storage volumes even after restarts[6]. However, this focus on reliability means they face delays when scaling.
The main drawback of stateful scaling lies in its speed. Scaling stateful applications is slower because pods are created sequentially, and attaching storage volumes can take anywhere from 10 to 60 seconds per pod[1][4].
Resource efficiency is another area where these two approaches differ. Stateless pods enable aggressive bin-packing and quick scale-downs, reducing idle time[1]. In contrast, stateful workloads can leave nodes underutilised as they wait for storage volumes to detach from one node and reattach to another[1].
| Criterion | Stateless (Deployments) | Stateful (StatefulSets) |
|---|---|---|
| Scalability | High; pods scale in parallel and quickly[1] | Moderate; pods scale sequentially with storage delays[1][4] |
| Fault Tolerance | High; any pod can replace another[6] | High for data; preserves identity and persistent data[6][3] |
| Resource Efficiency | High; minimal idle time during scaling[1] | Lower; nodes may remain underutilised during storage reattachment[1] |
| Cost Elasticity | Excellent; responds quickly to demand[1] | Poor; scaling bottlenecks can lead to over-provisioning[1] |
| Pod Identity | Ephemeral/Random[6] | Persistent/Ordinal (e.g., app-0, app-1)[6][11]
|
Conclusion
The choice between stateful and stateless scaling lies at the heart of your Kubernetes strategy. Deciding which to use depends on your application's specific needs. If your app doesn’t rely on local state, stable network identities, or ordered startup sequences, Deployments are the way to go. They scale efficiently, handle traffic spikes well, and keep operational costs manageable. This makes them ideal for workloads like web frontends, REST APIs, or microservices that offload session data to caching services such as Redis [7].
On the other hand, StatefulSets are essential for applications that require persistent data, stable identities, and ordered pod startups. While they provide these critical features, scaling is slower due to the sequential pod creation process [7].
Operational strategies can also help balance these trade-offs. A hybrid approach often works best - run stateless Deployments for maximum scalability and use managed databases or carefully configured StatefulSets for data persistence. This combination can cut operational costs by 30% and boost performance by 25% [12]. Additionally, separating stateful and stateless workloads onto dedicated node pools can prevent storage-heavy tasks from slowing down rapid scaling.
For stateful workloads, implementing safeguards is crucial. Use PodDisruptionBudgets to prevent the Horizontal Pod Autoscaler from disrupting too many key data nodes at once. Configure PreStop hooks to allow data migration to complete before pod termination [4]. Also, use the WaitForFirstConsumer binding mode to ensure volumes are provisioned in the correct availability zone, avoiding unnecessary scheduling retries [1].
Finally, keep in mind that StatefulSets don’t automatically delete PersistentVolumeClaims when scaled down. Cleaning up these claims manually is necessary to avoid unnecessary storage costs [7]. The core principle remains: stateless workloads offer flexibility and scalability, while stateful applications focus on maintaining data integrity [1].
For more expert advice on fine-tuning your Kubernetes scaling, visit Hokstad Consulting.
FAQs
When should I use a StatefulSet instead of a Deployment?
StatefulSets are the go-to choice for running stateful applications that need consistent network identities and persistent storage. Unlike Deployments, which are designed for stateless workloads, StatefulSets ensure each pod gets a unique and stable identity along with a dedicated persistent volume.
This setup is perfect for use cases like databases, message queues, or any application that depends on data persistence and requires ordered scaling. It guarantees reliability, consistent behaviour during restarts, and smooth operation when scaling up or down.
How can I reduce StatefulSet scaling delays from volume attachments?
To minimise delays in scaling StatefulSets due to volume attachments, it's essential to streamline storage provisioning and orchestration. Using dynamic provisioning or pre-configured PersistentVolumes can significantly reduce the time it takes to attach storage. Additionally, opting for SSD-backed PersistentVolumes and fine-tuning storage classes can improve performance.
Although Kubernetes autoscaling tools efficiently handle node scaling, storage attachment continues to be a challenge. Prioritising efficient management of persistent storage processes is key to achieving smoother scalability.
Which metrics should I use for HPA on stateless services?
When setting up Horizontal Pod Autoscaler (HPA) for stateless services, it's best to rely on metrics such as CPU utilisation, memory utilisation, or even custom application metrics. These metrics act as triggers, defining when scaling should occur. By using these, you can ensure resources are allocated efficiently while keeping your application's performance consistent during scaling activities.