
Network latency - the delay in data transfer - can significantly affect multi-cloud applications. When data moves between cloud providers, delays from public internet routing, congestion, and extended data paths add up, reducing performance and increasing costs. Here's why this matters and what can help:
- Latency Breakdown: Delays arise from propagation, processing, transmission, and queuing. Even 5ms latency can cut throughput by over 60% on high-speed connections.
- Multi-Cloud Challenges: Latency increases when data crosses global data centres. For example, inter-region setups can multiply delays by six times.
- Performance Impact: Real-time apps like gaming and video processing need under 50ms latency, while distributed databases face delays in maintaining consistency.
- Cost Factor: Transferring data between clouds incurs egress fees (£0.07/GB on average), adding financial strain.
Solutions include:
- Using private network underlays and edge computing to reduce latency by minimising hops and physical distance.
- Transitioning to efficient protocols like HTTP/3 and leveraging service mesh technologies for better routing.
- Employing latency-aware schedulers and tools like eBPF to optimise traffic.
Reducing latency isn't just about faster speeds; it's about smarter data routing and resource placement for better performance and cost control.
::: @figure 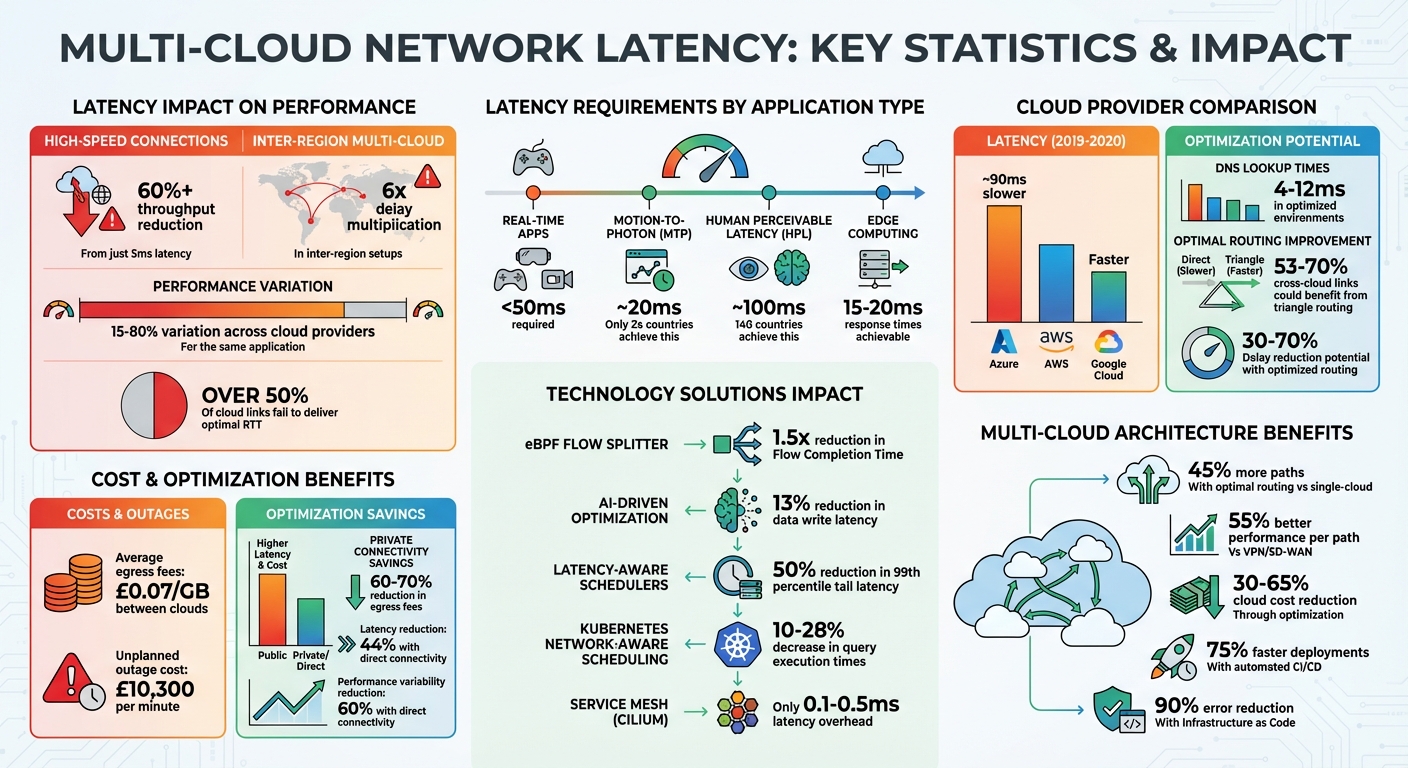 {Multi-Cloud Network Latency Impact: Key Statistics and Performance Metrics}
:::
{Multi-Cloud Network Latency Impact: Key Statistics and Performance Metrics}
:::
Research Findings on Latency Impact
Performance Loss Across Common Workloads
A study by the University of Cambridge highlights how even slight increases in latency can significantly affect performance. This not only drives up service costs but also impacts resource usage and energy efficiency [2]. Alarmingly, over half of all cloud links fail to deliver optimal Round-Trip Time (RTT) [3]. The problem becomes even more pronounced in multi-cloud setups, where applications must navigate across multiple provider networks. A comparison of major cloud providers from late 2019 to 2020 revealed that Microsoft Azure was consistently around 90ms slower than AWS and Google Cloud [8]. For workloads that are highly sensitive to latency, this kind of lag can be a dealbreaker.
DNS lookup times, which ideally should range between 4ms and 12ms in optimised environments [8], play a crucial role in determining the Time to First Byte for microservices and APIs. When combined with inefficient cross-cloud routing, these delays can snowball. Research suggests that triangle routing could enhance 53%-70% of cross-cloud links, reducing delays by 30%-70% [3]. These compounded delays highlight the complexity of ensuring top-notch performance in multi-cloud networks.
Such findings underscore why certain types of applications are especially vulnerable to latency issues, as explored in the following section.
Which Applications Are Most Affected by Latency
Distributed databases and geo-replicated systems are particularly latency-sensitive. Ensuring data consistency across multiple cloud providers requires coordination, which is directly influenced by network transmission times between data centres [5]. Some studies indicate that AI-driven adaptation techniques can cut data write latency in multi-cloud replicas by about 13%, even when network transmission times fluctuate [5].
Real-time interactive applications - such as cloud gaming, real-time video processing, and 5G ultra-reliable services - also rely heavily on low latency and minimal jitter to maintain quality [4]. For instance, only 24 countries worldwide consistently meet the Motion-to-Photon
(MTP) latency benchmark of roughly 20ms, crucial for applications like VR/AR and high-speed gaming [6]. By contrast, 140 countries achieve the Human Perceivable Latency
(HPL) threshold of around 100ms, which suffices for standard web services but falls short for more demanding tasks [6].
Payload size is another critical factor. Research from Technische Universität Braunschweig shows that while small payloads experience minimal latency overhead during inter-cluster communication, larger payloads (ranging from 100KB to 1MB) face much higher response times. This is due to TCP buffer limitations and encryption overhead [7]. Application performance can vary by 15% to 80% depending on the cloud service provider, even when users access the same application from different regions [9].
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Methods for Reducing Network Latency
New Technologies for Latency Reduction
Programmable data planes are making strides in reducing network latency. Tools like eBPF (extended Berkeley Packet Filter) and XDP (eXpress Data Path) enable organisations to manage traffic by flow. For example, a 2024 study using NextCloud and an eBPF-based flow splitter demonstrated a 1.5x reduction in Flow Completion Time for short flows. This was achieved by directing these flows into a dedicated short tunnel
within an SD-WAN fabric [12]. By separating latency-sensitive traffic - like remote procedure calls (RPCs) - from high-bandwidth transfers, congestion is minimised.
Modernising protocols also plays a key role. Transitioning from TCP to HTTP/3 (which uses QUIC over UDP) resolves head-of-line blocking issues. Meanwhile, gRPC with compression reduces payload sizes and transfer times compared to older protocols like HTTP/1.1 [10][11]. Additionally, service mesh technologies, such as Istio and Linkerd, enable real-time routing based on latency, ensuring the fastest multi-cloud paths are selected [11].
Private network underlays offer another solution by enabling direct cloud-to-cloud peering. This approach bypasses the instability of public internet routing, ensuring consistent throughput. It also significantly cuts public cloud egress fees by 60% to 70%, compared to standard internet-based egress [1]. On top of this, AI-driven tools like Latord
use machine learning to predict transmission fluctuations and dynamically adjust data write latency in geo-distributed replicas [5].
To complement these advancements, edge computing further reduces latency by bringing processing closer to end users.
How Edge Computing Reduces Latency
Edge computing reduces latency by processing data at the network edge, closer to users. This eliminates unnecessary network hops and shortens the physical distance data must travel, achieving response times as low as 15–20 milliseconds.
Latency-aware schedulers are particularly effective, reducing 99th percentile tail latency by up to 50% under heavy load. These schedulers work best when paired with core cloud infrastructure. Edge nodes manage latency-sensitive tasks - like AI inference or real-time monitoring - while central data centres handle large-scale storage and analysis. By clustering traffic within specific regions, edge computing avoids long-haul routes that increase round-trip times. For instance, Kubernetes clusters equipped with network-aware scheduling plugins have been shown to decrease query execution times by 10–28% compared to default schedulers.
However, edge sites come with limitations. They have fewer computational resources than central data centres, so inefficient scheduling can lead to queuing delays, negating latency benefits. Careful resource management is essential to maintain performance gains.
These approaches collectively improve multi-cloud application performance by ensuring data travels via the shortest and most efficient routes.
Simplify Secure Hybrid Multicloud Networking Architecture | Tech Talk Part 1
Hokstad Consulting's Recommendations for Multi-Cloud Optimisation

Hokstad Consulting has developed targeted strategies to address the challenges of latency in multi-cloud environments. By focusing on cost efficiency, DevOps improvements, and seamless cloud migrations, they help organisations optimise performance.
Latency-Aware Cloud Cost Engineering
The first step involves auditing infrastructure to identify latency bottlenecks and underutilised resources. This process often delivers substantial savings, with cloud costs reduced by 30% or more. In some cases, simply eliminating unused resources can result in savings of up to 65%.
Hokstad Consulting operates on a No Savings, No Fee
model, capping fees as a percentage of the savings achieved. This ensures their goals align with client outcomes. By adopting hybrid setups that combine private and public cloud resources, organisations can maintain low latency while maximising resource efficiency. Additionally, integrating FinOps practices can lead to cost reductions of up to 60% when fully implemented.
DevOps Optimisation with Low-Latency Pipelines
Automated CI/CD pipelines are a cornerstone of Hokstad Consulting's DevOps approach. Using Infrastructure as Code, these pipelines ensure consistent hybrid setups, boosting deployment speeds by as much as 75% and cutting errors by 90%.
To further enhance performance, parameters like TCP window size, congestion control mechanisms, and packet size are fine-tuned. For instance, using Cilium introduces only 0.1–0.5ms of latency, making it ideal for latency-sensitive pipelines. These optimisations not only improve performance but also streamline cloud migrations.
Cloud Migrations with Zero Downtime
Hokstad Consulting employs zero-downtime multipath routing via BGP or cloud load balancers to enable automatic failovers. Direct connectivity solutions like AWS Direct Connect or Azure ExpressRoute bypass the public internet, reducing latency by 44% and minimising performance variability by 60%. This approach effectively addresses inter-cloud routing challenges.
Given that unplanned outages can cost approximately £10,300 per minute, Hokstad Consulting ensures a phased migration process. This includes stabilisation during the migration and post-migration refactoring to prevent disruptions. AI-driven tools are used to map dependencies across IT systems, ensuring that moving one component does not inadvertently affect others. By implementing redundancy and high availability across multiple Availability Zones, organisations are safeguarded against localised failures.
Conclusion
Network latency plays a major role in the performance of multi-cloud applications, with differences ranging from 15% to 80% across cloud providers, even when running identical applications in various regions [9]. The type of workload also heavily influences how latency impacts performance. For instance, real-time applications like gaming or trading demand latency below 50 ms, whereas batch processing tasks can handle delays lasting several seconds. These findings are crucial for shaping strategies aimed at improving multi-cloud performance.
Research highlights that multi-cloud architectures can outperform single-cloud setups when configured effectively. They enable optimal routing on up to 45% more paths and deliver up to 55% better performance per path compared to VPN or SD-WAN solutions [9]. However, achieving these advantages requires meticulous planning and tuning.
Latency-aware infrastructure design is key to success. Private connectivity solutions, for example, not only enhance performance but also cut cloud egress fees by 60% to 70% [1]. Choosing the right service mesh is equally important; Cilium, with its eBPF-based technology, introduces minimal latency overhead, making it ideal for latency-sensitive tasks.
It's important to note that simply increasing bandwidth won't solve latency issues. Instead, strategies like optimising resource placement, leveraging edge computing, and using dedicated connectivity solutions can significantly reduce round-trip times by minimising network hops and shortening physical distances [1]. These approaches are essential for unlocking the full potential of multi-cloud environments.
FAQs
How do I measure latency between cloud providers?
To gauge latency between cloud providers, start with tools like ping and traceroute. These provide a basic look at round-trip time (RTT) and the network paths involved. For more in-depth metrics, such as RTT or Time to First Byte (TTFB), consider using advanced tools like Netperf, SockPerf, or OWAMP. Additionally, cloud-native platforms or tailored scripts can be valuable for tracking and benchmarking latency across different regions or providers efficiently.
When should I use private connectivity instead of the public internet?
Private connectivity is perfect when low latency, strong security, and consistent performance are crucial. It offers steady, low-latency connections, making it ideal for real-time tasks like video conferencing, IoT operations, or financial trading. This approach also meets strict security and compliance demands in sectors like healthcare and finance while bypassing the congestion of public internet traffic. In multi-cloud environments, private links streamline communication, minimise latency, and boost overall system dependability.
What’s the quickest way to cut multi-cloud egress costs?
The quickest way to cut down multi-cloud egress costs is by using smart caching strategies. For instance, you can place caches on cheaper managed hosting services to sit in front of pricier cloud storage solutions like AWS S3. Another effective approach is to reduce cross-region data transfers and make the most of content delivery networks (CDNs). These methods can help you save money while maintaining strong performance.