Event-driven CI/CD is transforming how software is deployed, especially in multi-cluster environments. Instead of relying on fixed schedules or manual triggers, this approach uses event buses like Kafka or AWS EventBridge to trigger workflows automatically based on specific events (e.g., code commits, failures). This method improves response times, reduces resource costs, and simplifies compliance in distributed setups.
Key Takeaways:
- Faster Response: Automates rollbacks or updates in under a second when issues arise.
- Multi-Cluster Management: Supports regional, blue-green, or multi-tenant clusters for resilience and compliance.
- Cost Savings: Cuts idle resource costs by 25–40% through event-triggered deployments.
- Security: Uses mTLS, service meshes (e.g., Istio), and RBAC to secure cross-cluster communication.
- Real-World Success: Companies like Netflix and Booking.com have drastically reduced deployment times and improved reliability using this approach.
Quick Overview:
- Architecture: Combines event buses, secure communication, and orchestration strategies (centralised or per-cluster).
- Use Cases: Includes progressive delivery, SaaS automation, and hybrid cloud deployments.
- Design Principles: Focus on reliability (e.g., Dead Letter Queues), security (e.g., encrypted payloads), and cost efficiency (e.g., serverless workflows).
This approach is particularly relevant for UK organisations managing GDPR compliance, regional redundancy, and cloud cost optimisation. For tailored solutions, companies like Hokstad Consulting offer expertise in event-driven workflows and governance.
::: @figure 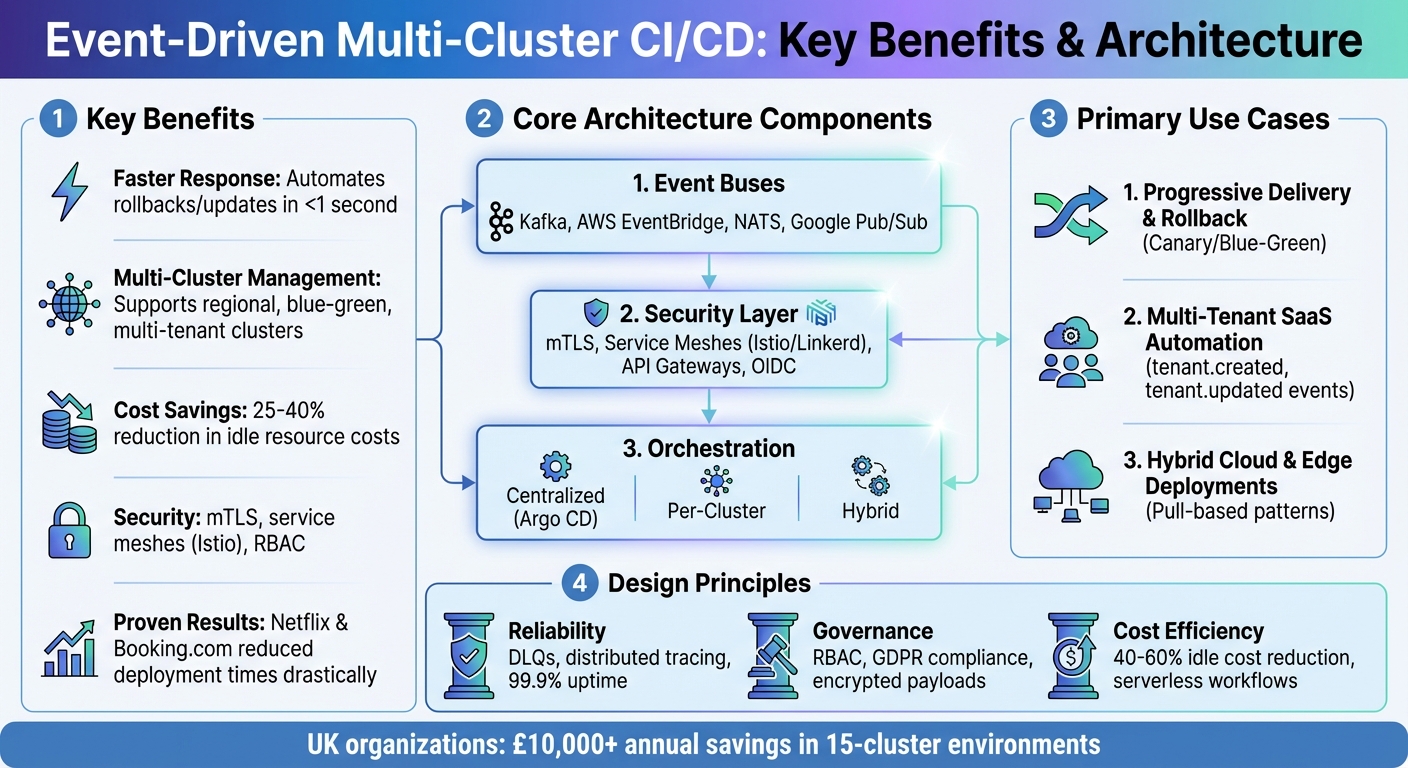 {Event-Driven Multi-Cluster CI/CD Architecture Components and Benefits}
:::
{Event-Driven Multi-Cluster CI/CD Architecture Components and Benefits}
:::
App Mod Series #5: Choreographing event-driven CI/CD for any Kubernetes on any cloud
Architecture Patterns for Event-Driven Multi-Cluster CI/CD
Building an event-driven multi-cluster CI/CD system requires careful planning and a solid architectural foundation. At its core, it relies on three essential components: event buses to handle communication between systems, secure mechanisms to protect data during transmission, and orchestration models to determine where deployment decisions are made. These choices set the stage for the efficient and responsive workflows discussed later.
Event Bus and Messaging Systems
Event buses play a critical role in decoupling event producers from consumers. For instance, Apache Kafka offers strong ordering guarantees and high throughput, making it suitable for complex workflows. However, it often demands more operational effort compared to lighter alternatives like NATS, which is designed for ultra-low latency and simplicity - perfect for transient CI/CD events where speed is key.
Managed services such as AWS EventBridge and Google Pub/Sub simplify operations by taking care of the infrastructure. A practical example of this is Alibaba Cloud, which integrated EventBridge with GitHub to route push events directly into Argo Workflows running on ACK One clusters [2]. While managed services reduce operational overhead, they can introduce challenges in hybrid or multi-cloud setups, such as higher egress costs and cross-region latency. To address these, many UK organisations adopt a hybrid approach: a global event bus for audit and governance paired with cluster-local messaging systems for regional or on-premise deployments.
Once event routing is in place, the next step is ensuring secure communication across clusters.
Secure Cross-Cluster Event Propagation
When dealing with distributed clusters, security must be prioritised at multiple levels. Mutual TLS (mTLS) is a key component, ensuring both parties in a communication session authenticate each other before exchanging data. Service meshes like Istio and Linkerd automate this process, handling certificate rotation and enforcing policies without requiring changes to application code. Additionally, API gateways act as secure entry points, terminating external TLS connections and managing authentication, authorisation, and rate limits before passing requests into the mesh as internal mTLS connections.
A popular approach for UK organisations with strict network controls is the agent-based pull model, where lightweight agents within each cluster initiate secure outbound connections to a central control plane. This avoids exposing public APIs directly, simplifying firewall configurations while maintaining a strong security stance [4]. Federated identity systems like OIDC or workload identity frameworks ensure every cross-cluster call is traceable to specific roles and teams, aiding governance and incident response efforts.
Centralised vs Per-Cluster Orchestration
With messaging and security in place, the final piece of the puzzle is the orchestration strategy. The choice between centralised and per-cluster orchestration has significant implications for reliability, latency, and governance.
A centralised orchestrator, such as a single Argo CD instance managing multiple clusters, offers unified governance and a single pane of glass
for policy enforcement, RBAC, and fleet-wide visibility [3][4]. This model is often preferred by UK enterprises for its compliance benefits, though it can introduce latency and risks tied to having a single point of failure.
On the other hand, per-cluster orchestration keeps control loops closer to workloads, reducing latency and isolating failures within specific regions. A hybrid approach is common: for example, Red Hat describes a setup where a multi-tenant central Argo CD handles global governance, while individual teams manage their own scoped Argo CD instances for localised control [3]. Many organisations adopt a hierarchical model, where global controllers define the desired state and guardrails, while regional or per-cluster controllers handle execution and reconciliation locally. This approach not only balances control and flexibility but also aligns well with efforts to manage cloud costs, deployment frequency, and data residency requirements.
Use Cases for Event-Driven Multi-Cluster CI/CD
Event-driven multi-cluster CI/CD isn't just a concept; it's a practical solution for many real-world challenges. By enabling fast, reliable, and compliant workflows, it addresses the needs of UK businesses - from financial firms ensuring regional redundancy to retailers managing geographically specific clusters [4][7]. Let’s explore how this approach solves common issues in multi-cluster environments.
Progressive Delivery and Rollback
Rolling out updates across clusters requires precision. Tools like Argo Rollouts and Flagger make this possible with canary or blue-green deployments, starting small and expanding only when performance metrics confirm success. For instance, a UK retailer might release a new checkout feature to just 5% of traffic in its London cluster. If error rates and latency meet the required thresholds, the update is then rolled out to an EU cluster [4][6]. If something goes wrong, the system can automatically roll back the change in the affected cluster.
Centralised orchestration provides unified governance but may introduce latency. On the other hand, localised control loops within each cluster reduce latency but decentralise control. Many UK teams combine these approaches, using a central controller to set the desired state and policies while regional controllers handle local execution. This hybrid model balances control with resilience [3][4].
One logistics platform, managing over 2,500 microservices across 15+ clusters, cut deployment times by 60% after adopting a GitOps-based multi-cluster CI/CD approach. By eliminating custom scripts and enabling quarterly disaster recovery tests, they streamlined operations and extended these efficiencies to automated SaaS processes [7].
Multi-Tenant SaaS Automation
For multi-tenant SaaS providers, automating tenant lifecycle operations - like provisioning, updates, and deprovisioning - across regional clusters is essential. Event-driven pipelines handle business events such as tenant.created, tenant.updated, or tenant.deleted triggered by billing or customer management systems [2].
When a tenant.created event occurs, workflows powered by Argo Workflows set up namespaces, databases, and ingress rules in the appropriate cluster based on the tenant's region and service tier. A follow-up tenant.provisioned event then triggers downstream processes [4][9]. For example, NHS data is routed to UK-only clusters, while European clients are assigned to EU clusters. This method ensures scalability, compliance, and auditability, with GitOps-based tools applying region-specific configurations and policies [3][5].
These principles extend beyond tenant operations, supporting hybrid deployments and ensuring that automation remains consistent and traceable.
Hybrid Cloud and Edge Deployments
Hybrid cloud and edge environments come with unique challenges, such as unstable connectivity, increased latency, and strict regulatory requirements. Event-driven pipelines address these issues using pull-based patterns. Agents on each cluster fetch updates from a central control plane when triggered by events like sync
or update available
, avoiding the need for inbound connections to edge locations [4][9].
In cases of poor connectivity, events are queued and processed once the connection is restored, with sync.completed or sync.failed events providing visibility. For example, retail point-of-sale systems can deploy to edge clusters in response to demand, while resource-heavy analytics workloads remain in the cloud.
Industries like financial services, healthcare, and the public sector benefit from this model by embedding governance into deployments. Updates are triggered only by signed Git commits, verified image registries, or approved ITSM change requests. Policy engines validate compliance requirements - like encryption, network policies, or namespace restrictions - before updates are applied. This ensures strict access controls and maintains detailed audit logs, all while automating deployments, rollbacks, and disaster recovery drills.
For organisations looking to optimise their multi-cluster setups, reduce cloud costs, and meet UK/EU compliance standards, Hokstad Consulting offers tailored event-driven solutions designed to streamline GitOps workflows and governance.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Design Considerations for Event-Driven CI/CD
Creating dependable event-driven workflows involves more than just connecting tools - it requires careful attention to principles like idempotency. This ensures operations yield the same outcome whether they run once or multiple times. A clear example can be seen in Devtron's multi-cluster pipelines, where Kubernetes rolling updates safely reapply during retries, avoiding duplicate resource creation across environments like Dev, Staging, and Prod [7]. These principles shape key design considerations around reliability, security, and cost efficiency.
Reliability and Observability
To maintain high uptime (e.g., 99.9%), configure Dead Letter Queues (DLQs) to isolate and handle failed events. Coupling this with distributed tracing tools such as Jaeger or OpenTelemetry allows teams to follow events as they pass through various services and clusters.
Structured logging is another essential practice. By formatting logs in JSON with consistent fields - like event ID, cluster ID, timestamp, and trace ID - teams can streamline debugging and querying using tools like the ELK Stack. These correlation IDs are particularly useful for tracing a deployment’s journey from a Git commit to a live workload [1].
Governance and Security
Governance in multi-cluster deployments relies on controlled environment promotions. Sequential flows from Dev to Staging to Prod, governed by Role-Based Access Control (RBAC) policies, ensure that only approved events trigger changes in production. For UK organisations, this approach supports GDPR compliance by routing events solely to UK-based clusters and maintaining immutable logs of all actions. Namespace isolation and single sign-on (SSO) in tools like Argo CD further strengthen security by requiring approvals before data crosses clusters, reducing risks of unauthorised data exposure [7].
Adopting security best practices is equally critical. Use mutual TLS and encrypt payloads to secure event propagation. Service meshes like Istio can enforce zero-trust policies, while Argo CD’s RBAC can limit event targeting in multi-tenant environments, preventing lateral movement between clusters. Additionally, integrating vulnerability scanning tools like Trivy into GitHub Actions ensures compromised images are blocked before they can propagate events [1].
This balance of security and operational discipline also plays a role in managing costs effectively.
Cost Management
Event-driven architectures are inherently resource-efficient, scaling components only when needed and avoiding the costs of constant polling. For instance, serverless Argo Workflows triggered by EventBridge can process CI events on demand, reducing idle costs by 40–60% compared to traditional pipelines. UK businesses managing 15-cluster environments on AWS or Azure can save over £10,000 annually by implementing strategies like 7-day event retention policies and metric-based autoscaling [7].
Other cost-saving measures include compressing event payloads and routing traffic through private links in hybrid setups to cut public internet charges. For example, Devtron’s GitOps approach reduced data transfer costs by 50% in disaster recovery clusters through manifest cloning [7].
For organisations aiming to cut cloud expenses while adhering to UK/EU compliance standards, Hokstad Consulting provides tailored solutions to streamline GitOps, governance, and cost management across clusters.
Conclusion and Next Steps
Event-driven multi-cluster CI/CD is reshaping how software is deployed across various environments. In 2023, Delhivery successfully transitioned from Jenkins to Devtron, enabling CI/CD for over 2,500 microservices across more than 15 clusters. This shift eliminated the need for scripting through GitOps-based promotions, introduced targeted RBAC for individual teams, and facilitated quarterly disaster recovery (DR) validations using cloned manifests [7].
To build on what we've discussed about architecture and design, here’s a quick guide to get started:
- Segregate environments by using separate clusters or namespaces for Development, Staging, Production, and DR.
- Implement RBAC and SSO to secure secrets and configurations.
- Adopt GitOps tools like Argo CD or Devtron to create reusable environments and map them to clusters without relying on scripting.
- Use rolling updates in development, canary deployments in staging, and blue-green deployments in production.
- Deploy consolidated dashboards for better visibility.
- Conduct quarterly DR validations and enforce approval policies alongside regular security scans, especially in production [7][4].
Following these steps can help streamline processes and unlock the full potential of event-driven CI/CD.
Summary
Event-driven architectures bring simplicity to deployments, bolster reliability, and enhance observability across clusters. Key design principles include:
- Reliability: Achieved through integrated monitoring tools.
- Governance: Enforced via per-environment RBAC, SSO, and regular security checks.
- Cost Efficiency: Eliminating scripting overhead through declarative configurations saves time and resources.
For UK organisations, this approach can lead to annual cost savings of over £10,000 in environments with 15 clusters, all while maintaining GDPR compliance through UK-based cluster routing [7].
How Hokstad Consulting Can Help

Hokstad Consulting specialises in delivering tailored solutions for event-driven workflows. They support DevOps transformations and custom automation with secure cross-cluster orchestration, helping businesses streamline operations. Their expertise in cloud cost engineering has enabled UK businesses to cut cloud expenses by 30–50%.
Hokstad also ensures seamless cloud migrations with zero downtime, whether transitioning to hybrid, private, or public cloud environments. They provide cloud cost audits formatted in GBP, compliance-focused security for UK data governance, and AI-driven DevOps agents to optimise event orchestration. With a pricing model that caps fees as a percentage of the savings achieved, they even offer a free assessment to uncover optimisation opportunities for multi-cluster deployments [8].
FAQs
How does event-driven CI/CD speed up deployments in multi-cluster environments?
Event-driven CI/CD streamlines deployment in multi-cluster environments by automating actions triggered by events like code updates or system changes. This removes the need for manual steps, enabling faster and more consistent rollouts.
With real-time workflows, these systems keep deployments synchronised across clusters, cutting down delays and boosting operational efficiency. This method not only speeds up deployment cycles but also improves reliability by reducing the chances of human error.
How is cross-cluster communication secured in event-driven CI/CD workflows?
Securing communication between clusters in event-driven CI/CD workflows demands a careful approach with multiple layers of protection. Encryption, such as TLS, plays a key role in keeping data safe while it's being transmitted. Alongside this, authentication mechanisms - like mutual TLS or tokens - confirm the identity of the parties involved in the communication.
On top of that, network segmentation helps to isolate clusters, reducing the risk of unnecessary exposure. Meanwhile, strict access controls ensure that only authorised users or systems can interact with the clusters, preserving both security and data integrity. Together, these practices create a strong defence to protect sensitive information and maintain secure operations across clusters.
How does event-driven CI/CD help optimise cloud costs?
Event-driven CI/CD takes cloud cost management to the next level by automating resource allocation and scaling in response to real-time triggers. This means resources are only active when genuinely required, cutting down on unnecessary usage and avoiding over-provisioning.
By making infrastructure more efficient and syncing resource usage with actual demand, businesses can noticeably reduce their cloud spending without compromising on performance. This method works hand in hand with strategies aimed at saving costs and simplifying operations, particularly in multi-cluster setups.