
Dynamic pod scheduling in Kubernetes is all about balancing cost efficiency with performance reliability. Misaligned resource requests often lead to over-provisioning, pushing cloud costs up by 30–60%. However, overly aggressive optimisation can cause latency issues and failures. Here's the crux:
- Cost-focused scheduling reduces expenses by rightsizing resources, improving node utilisation, and leveraging autoscaling tools like Cluster Autoscaler or Karpenter. This approach suits batch jobs and non-critical workloads but risks throttling under sudden traffic spikes.
- Performance-focused scheduling prioritises reliability by allocating extra resources and spreading workloads across zones. It’s ideal for critical services like APIs or payment systems but comes with higher cloud costs.
Key takeaway: Combining both approaches - cost-efficient policies for non-critical tasks and performance-focused settings for vital services - helps UK organisations manage cloud expenses while maintaining service quality.
Part 1: Pod Scheduling Policies: Introduction & Why It Matters
1. Cost-Optimised Dynamic Scheduling
Cost-optimised dynamic scheduling focuses on running workloads on fewer, more efficiently utilised nodes, directly cutting cloud expenses. For UK organisations paying cloud providers in US dollars while managing budgets in pounds sterling, this approach not only lowers monthly bills but also reduces the impact of exchange-rate fluctuations.
Resource Utilisation
At the heart of cost-optimised scheduling is fine-tuning pod resource specifications. Instead of relying on theoretical peak usage, it’s better to base pod resource requests on observed 95th-percentile usage. For instance, if a service typically consumes 200m CPU and 300Mi memory, a more efficient configuration might request 250m CPU and 400Mi memory, with limits set at 2–3 times the request. This avoids the common pitfall of over-provisioning, such as allocating a full vCPU and 1Gi memory unnecessarily, which blocks effective bin-packing and leaves nodes underutilised [2][3].
Take a simple example: a 4-core node running four pods, each requesting 1 core but only using 0.2 cores. Kubernetes sees this node as fully allocated, even though 68% of its capacity remains idle [2]. By aligning requests with actual usage, more pods can fit on each node, reducing the overall node count and, consequently, cloud costs.
Tools like Vertical Pod Autoscaler (VPA) can help by using production data to recommend optimal resource settings [2][4]. When combined with flexible scheduling policies - such as soft anti-affinity rules, well-defined Pod Topology Spread Constraints, and PriorityClasses for low-priority workloads - these adjustments allow Kubernetes to pack pods more efficiently while maintaining availability across zones [1][3]. For workloads in the UK, where traffic often follows diurnal patterns, this means nodes can be released during off-peak hours, further cutting hourly cloud charges.
By optimising resource requests, organisations not only improve utilisation but also lay the groundwork for significant reductions in cloud spend.
Cloud Spend
Once resource requests are properly aligned, further savings can be achieved through dynamic autoscaling. The biggest cost reductions come from three key strategies: rightsizing pod requests to enable better bin-packing, using tools like Cluster Autoscaler or Karpenter to terminate idle nodes and match capacity to demand, and incorporating spot or preemptible capacity for workloads that can tolerate interruptions [2][3][4]. These measures help reclaim wasted resources, with tools like Karpenter cutting compute costs by 10–20% compared to fixed node groups [2].
For organisations looking to optimise further, expert consultancies like Hokstad Consulting specialise in DevOps and cloud-cost engineering. They offer services such as cost audits, resource rightsizing, and tailored autoscaling policies, all designed to align with UK-specific business hours and traffic patterns. Their strategies have helped businesses save over £50,000 annually on infrastructure costs, all while maintaining reliable service levels.
2. Performance-Optimised Dynamic Scheduling
Performance-optimised dynamic scheduling prioritises low latency, high throughput, and strong reliability, even if it comes with higher operational costs. Instead of squeezing pods tightly together to cut expenses, this approach ensures that critical services have enough breathing room to handle sudden traffic surges without delays or throttling. For UK businesses, especially those in sectors like e-commerce during seasonal sales or financial services handling real-time transactions, the cost of underperformance can far outweigh the savings achieved through aggressive resource packing. This strategy stands in contrast to the cost-focused methods discussed earlier, highlighting the trade-offs between operational efficiency and expenditure.
Resource Utilisation
In performance-optimised environments, resource requests are deliberately set higher to create a buffer for unexpected demand. For instance, a critical microservice might request between 750m and 1 CPU, with limits closely aligned to these requests to ensure Guaranteed QoS. This setup prevents CPU throttling, a common cause of latency spikes in CPU-intensive services, and reserves ample capacity on each node [2][4].
These configurations often maintain lower average utilisation - typically around 40–60% - to ensure enough headroom for sudden traffic spikes. This trade-off in efficiency guarantees that services can handle unexpected loads without compromising performance [4][6].
Latency and Reliability
Minimising latency and ensuring reliability require strategic use of Kubernetes' topology-aware scheduling features. Pod anti-affinity and topology spread constraints distribute replicas across multiple nodes and availability zones. This setup ensures that a single node failure or even a zonal outage won't disrupt the entire service [1][3]. For UK-based deployments, spreading critical pods across two or three zones within a UK region helps mitigate zonal failures while maintaining predictable network latency.
PriorityClasses and preemption mechanisms are vital under heavy load. High-priority pods, such as customer-facing APIs or payment systems, are scheduled first and can evict lower-priority jobs if the cluster becomes overcrowded [3][8]. Additionally, PodDisruptionBudgets (PDBs) limit the number of replicas disrupted during maintenance or node upgrades. Together, these features ensure that critical services remain operational, even during planned downtime, laying the groundwork for proactive scaling as workloads grow.
Scalability and Resilience
Building on these reliability measures, performance-optimised autoscaling ensures services remain uninterrupted during peak activity. Horizontal Pod Autoscaler (HPA) thresholds are set more conservatively, scaling out at 50–60% CPU utilisation instead of the usual 70–80%. This allows the system to respond to custom metrics like request rates, queue depths, or p95 latency [2][4]. While this approach leads to more replicas and higher baseline capacity, it prevents performance bottlenecks during sudden traffic surges.
Cluster autoscaling tools, such as Karpenter, complement this strategy by quickly provisioning new nodes when pods can’t be scheduled, reducing queuing delays [2][3]. This setup is particularly useful for handling UK-specific spikes, such as retail booms during holidays or major sporting events, by maintaining a buffer that can absorb failover traffic in case an entire zone fails [6]. Consulting firms like Hokstad Consulting assist UK organisations in fine-tuning these autoscaling policies to balance technical performance with budget considerations.
Cloud Spend
While performance optimisation does lead to higher costs, careful planning can help manage expenses. For UK organisations, the challenge is compounded by paying cloud providers in US dollars, making currency fluctuations an additional factor during budget planning.
To address this, services are often segmented by tier: gold for revenue-critical paths, silver for important but less sensitive workloads, and bronze for batch jobs. This approach ensures that costly performance policies are applied only where they are most needed. Periodic rightsizing, guided by Vertical Pod Autoscaler (VPA) recommendations and observability data, further helps reduce resource waste while maintaining the necessary capacity buffers [2][4][7]. When executed thoughtfully, performance-optimised scheduling delivers the reliability and speed UK customers demand, without letting infrastructure costs spiral out of control.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Advantages and Disadvantages
::: @figure 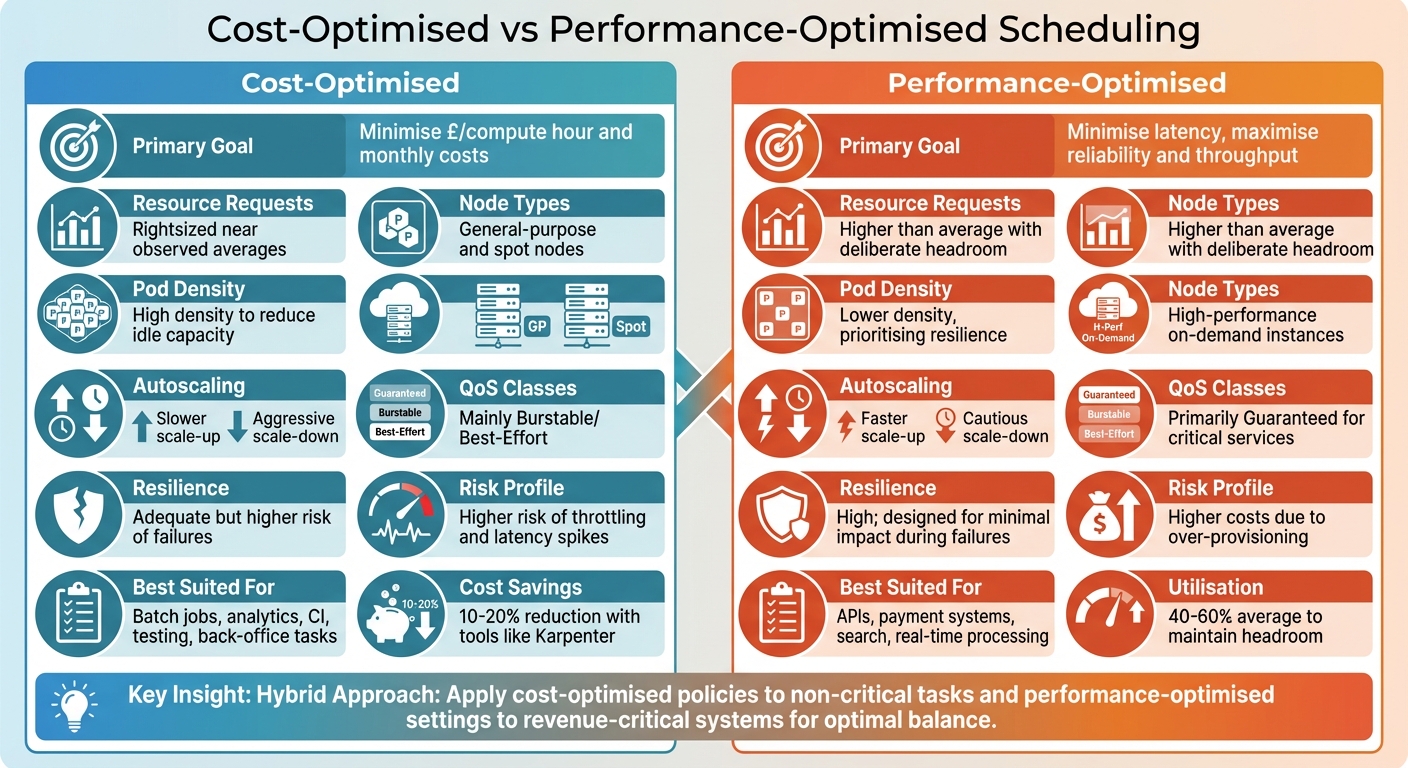 {Cost-Optimised vs Performance-Optimised Kubernetes Pod Scheduling Comparison}
:::
{Cost-Optimised vs Performance-Optimised Kubernetes Pod Scheduling Comparison}
:::
Let’s dive deeper into the trade-offs between cost-optimised and performance-optimised scheduling models. Each approach comes with its own pros and cons, so understanding these nuances is key to making informed decisions.
Cost-optimised scheduling focuses on cutting infrastructure costs while maximising resource efficiency. By fine-tuning CPU and memory usage, it reduces the number of nodes required, leading to noticeable savings [1] [2]. However, this approach isn't without its risks. Overpacking pods or underestimating resource needs can lead to CPU throttling, out-of-memory issues, and latency spikes - especially during sudden traffic surges [4] [5].
On the other hand, performance-optimised scheduling prioritises low latency, high throughput, and strong resilience. It achieves this by leaving resource headroom, spreading pods across nodes and availability zones, and using Guaranteed QoS classes for critical services [1] [3]. This ensures that crucial systems like customer-facing APIs or payment platforms remain reliable, even under heavy load. The downside? Higher cloud costs due to over-provisioning and lower average utilisation.
A hybrid approach combines the best of both worlds. Cost-optimised policies are applied to non-critical tasks, while performance-optimised settings are reserved for revenue-critical systems [1] [3]. This strategy ensures that resources are allocated where they matter most, balancing performance with budget constraints. Many organisations, including those supported by Hokstad Consulting, are adopting such tiered strategies, leveraging DevOps practices and cloud cost engineering to find the right balance.
| Criterion | Cost-Optimised | Performance-Optimised |
|---|---|---|
| Primary Goal | Minimise £/compute hour and monthly costs | Minimise latency, maximise reliability and throughput |
| Resource Requests | Rightsized near observed averages | Higher than average with deliberate headroom |
| Pod Density | High density to reduce idle capacity | Lower density, prioritising resilience |
| Node Types | General-purpose and spot nodes | High-performance on-demand instances |
| Autoscaling | Slower scale-up, aggressive scale-down | Faster scale-up, cautious scale-down |
| QoS Classes | Mainly Burstable/Best-Effort | Primarily Guaranteed for critical services |
| Resilience | Adequate but higher risk of failures | High; designed for minimal impact during failures |
| Risk Profile | Higher risk of throttling and latency spikes | Higher costs due to over-provisioning |
| Best Suited For | Batch jobs, analytics, CI, testing, back-office tasks | APIs, payment systems, search, real-time processing |
When fine-tuning scheduling policies, keep a close eye on both monthly costs and key performance metrics like p95 latency, error rates, and availability. Cost savings are important, but they should never come at the expense of meeting your service level objectives.
Conclusion
Dynamic pod scheduling in Kubernetes comes down to finding the right balance between cost and performance. On one hand, you can prioritise guaranteed performance, which may lead to higher cloud bills. On the other, you can optimise for leaner resource usage, accepting some trade-offs in latency and resilience. Often, organisations face a tough choice here - because improving bin-packing efficiency leaves less room for handling unexpected traffic spikes.
A practical way to approach this challenge is through workload classification. By categorising services based on their importance to the business, you can optimise resource allocation where it matters most. For instance, critical systems like customer-facing APIs, payment platforms, and revenue-driving services should have performance-focused configurations. This means generous resource requests, conservative autoscaling policies, and strict topology spread constraints. Meanwhile, non-critical tasks - such as batch jobs, CI pipelines, and analytics - can adopt cost-focused settings, with smaller resource requests, aggressive scale-down policies, and higher pod density. This method ensures you’re not overspending on resilience for less critical tasks while maintaining service-level objectives (SLOs) where it counts.
Start by establishing a baseline. Measure your current cloud spend, evaluate resource utilisation, and confirm that your SLOs are being met. Then, roll out changes gradually. For example, begin by rightsizing a single service, fine-tune its autoscaling thresholds, and monitor the results over a couple of weeks. If the trade-offs are acceptable, expand these changes to other services. Align these efforts with UK-specific seasonal peaks - like Black Friday, Boxing Day, or tax deadlines - and integrate cost metrics into regular FinOps or platform team discussions. This ensures scheduling decisions stay transparent and data-driven.
When internal efforts hit their limits, external expertise can help unlock further opportunities. For UK businesses, Hokstad Consulting offers tailored solutions in DevOps transformation and cloud cost management. Their team specialises in designing dynamic scheduling and autoscaling strategies that can reduce cloud costs by 30–50%, all while maintaining performance and compliance. By leveraging AI-driven automation and ongoing optimisation, they provide more than just a one-time fix - they help businesses achieve continuous improvement.
Ultimately, there’s no one-size-fits-all solution. The balance between cost and performance requires constant monitoring and adjustment as workloads and business priorities shift. Whether you choose to “pay for predictable performance” or “engineer for lean efficiency,” the key is to remain adaptable, informed, and ready to evolve your strategies.
FAQs
How can UK organisations optimise Kubernetes pod scheduling to balance cost and performance effectively?
Dynamic pod scheduling in Kubernetes helps organisations allocate resources effectively, but striking the right balance between cost and performance can be tricky. For UK businesses, this means carefully examining workload patterns, scaling needs, and prioritising key applications to avoid unnecessary expenses.
Some practical approaches include using auto-scaling to match resources with demand, setting resource limits to prevent over-provisioning, and opting for spot instances or reserved capacity to save on costs. Regularly monitoring and tweaking configurations is crucial to maintaining steady performance while managing budgets wisely.
For customised solutions, UK businesses can turn to experts like Hokstad Consulting. They specialise in fine-tuning cloud infrastructure and cutting hosting expenses, helping organisations achieve a smooth balance between performance and cost.
How can you reduce the risk of resource throttling when using cost-optimised pod scheduling?
To reduce the risk of resource throttling while keeping pod scheduling cost-efficient, it's crucial to find the right balance between saving money and ensuring enough resources are available. Start by setting resource requests and limits for your Kubernetes pods that match their actual workload needs. Allocating too much increases costs, while allocating too little can lead to throttling and poor performance.
Using horizontal pod autoscaling is a smart way to dynamically scale the number of pods based on demand. This ensures your applications can handle traffic surges without wasting resources during quieter times. Regularly monitoring and analysing resource usage is also key - this helps you spot trends and fine-tune your scheduling approach effectively.
If you're looking for expert advice on balancing cost and performance, Hokstad Consulting offers customised solutions to help you achieve your goals efficiently.
How does performance-focused scheduling maintain reliability during periods of high traffic?
Performance-focused scheduling in Kubernetes is all about dynamically adjusting resources to meet demand. It ensures that critical workloads get the capacity they need during peak traffic, while less urgent tasks are redistributed. This reduces bottlenecks and keeps performance steady.
Beyond maintaining reliability, this method helps manage costs effectively by scaling resources up or down depending on the workload. For businesses aiming to balance strong performance with cost control, this strategy proves particularly useful during periods of high demand.