
Managing CI/CD pipelines across AWS, Azure, and GCP isn’t just about tools - it’s about teamwork, processes, and avoiding common pitfalls like silos and inefficiencies. Here’s a quick breakdown of how to improve collaboration in multi-cloud CI/CD environments:
- Standardisation: Use shared tools, templates, and workflows to reduce complexity and errors.
- Clear Ownership: Define roles for technical and business responsibilities to streamline decision-making.
- Automation: Implement reusable Infrastructure as Code (IaC) modules, secure artefact handling, and dynamic credential management.
- Unified Visibility: Centralise monitoring and tagging to improve incident response and cost tracking.
- Governance: Integrate Policy as Code and compliance checks directly into pipelines.
These practices help teams work together effectively, reduce bottlenecks, and deliver faster, more secure deployments across multiple cloud platforms.
Learning Live with AWS & HashiCorp - Ep.7 Collaboration and CI/CD on Amazon ECS with Terraform
What Multi-Cloud CI/CD Collaboration Actually Requires
Successful multi-cloud CI/CD collaboration isn't just about picking the right tools - it hinges on well-defined processes that guide teams effectively. Without a solid framework, even the most advanced tools can lead to inefficiencies and friction. Hokstad Consulting advocates for clear, inclusive processes that empower teams to work cohesively. Let’s dive into how collaboration models can simplify multi-cloud workflows.
Defining Collaboration Models Across Clouds
The shift from provider-specific tools to a platform-centric approach is key [1]. This involves creating a platform engineering team tasked with building reusable resources. These might include environment templates, automated deployment workflows, or standardised pipeline structures, all designed to work across multiple clouds. The goal? To provide application teams with tools that simplify their work, no matter the cloud provider.
One cornerstone of this approach is the Golden Path
. This refers to a secure-by-default CI/CD pipeline and Infrastructure as Code (IaC) template that developers can follow without needing to navigate the complexities of infrastructure decisions [1][2]. It ensures pre-approved, secure defaults while still allowing flexibility and compliance.
For governance, adopting a federated model has proven effective. In this setup, security and compliance teams define the guardrails - often using Policy as Code tools like Open Policy Agent (OPA) or HashiCorp Sentinel - while application teams retain the autonomy to operate within these boundaries [1][2]. This balance avoids the delays of centralised approval processes while maintaining robust oversight.
Core Shared Responsibilities in Multi-Cloud CI/CD
Regardless of the collaboration model, teams need to align on shared responsibilities. The following table highlights key focus areas and commonly used tools:
| Responsibility Area | Shared Focus | Common Tools |
|---|---|---|
| Infrastructure | Standardised provisioning with IaC | Terraform, OpenTofu, Pulumi [2][6] |
| Security | Centralised secrets and identity management | HashiCorp Vault, OIDC federation [2][5] |
| Deployment | Portable container orchestration | Kubernetes, Helm [3][5] |
| Governance | Automated compliance enforcement | OPA, Sentinel [2][5] |
| Observability | Unified monitoring and alerting | Prometheus, Grafana, ELK [3] |
To minimise errors and divergence, consolidate all application code, IaC scripts, and configurations in a single repository. Separate repositories maintained by cloud-specific teams can lead to inconsistent codebases, making cross-team collaboration and handoffs more challenging [3].
Lastly, avoid the risk of an 'onboarding cliff' by removing dependencies on individual expertise. Use versioned templates or self-service forms to ensure new team members can contribute without relying on tribal knowledge. This approach creates a scalable, sustainable collaboration model that doesn’t hinge on a single engineer’s know-how [4].
Pipeline Ownership and Workflow Handoffs
::: @figure 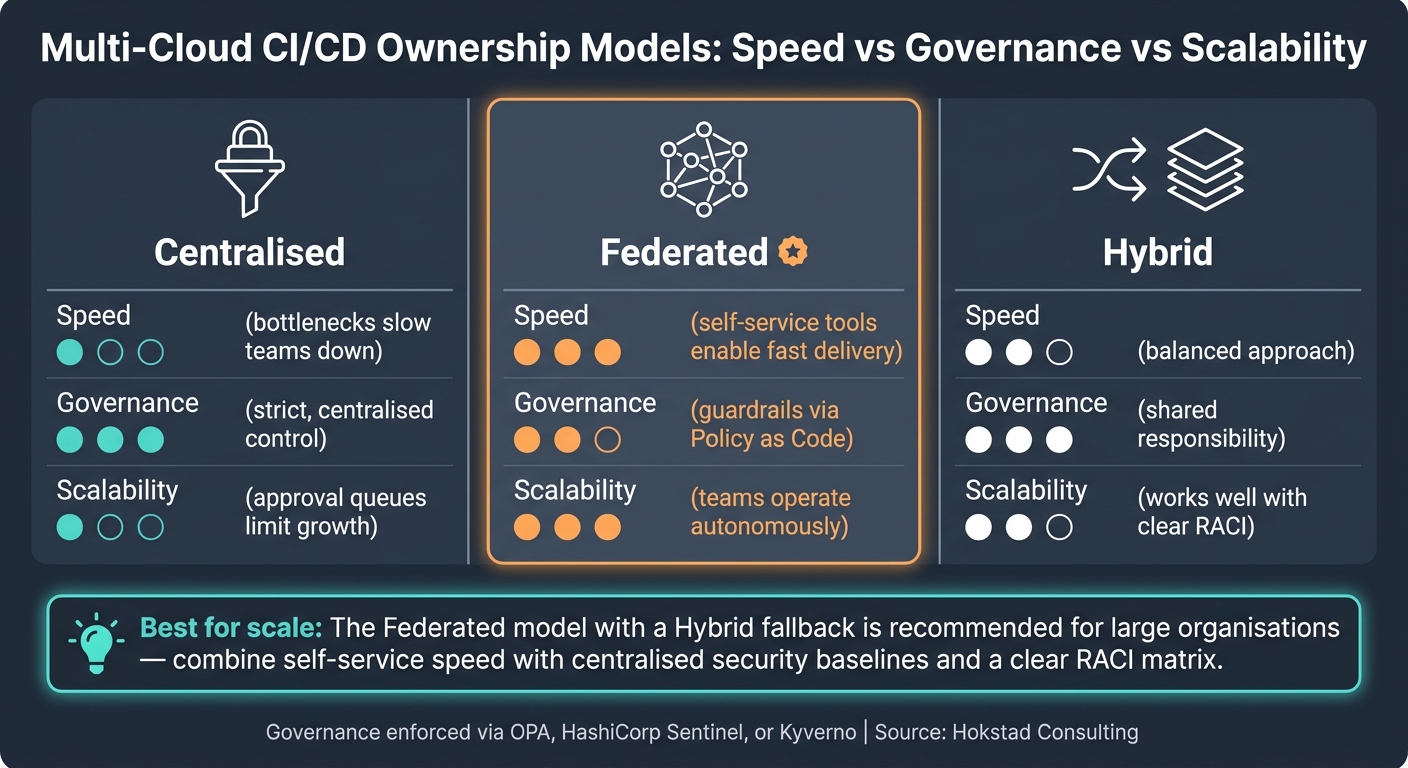 {Multi-Cloud CI/CD Ownership Models: Speed vs Governance vs Scalability}
:::
{Multi-Cloud CI/CD Ownership Models: Speed vs Governance vs Scalability}
:::
When it comes to multi-cloud CI/CD operations, having clear pipeline ownership and well-defined handoffs is essential. Without these, even the best intentions can lead to confusion, delays, and finger-pointing. A structured approach ensures smooth workflows and quicker resolutions.
Dividing Responsibilities Among Teams
Every part of a pipeline needs both a technical and a business owner. For instance, a platform engineer might handle the technical setup of a cloud environment, while a development manager oversees its strategic use and budgetary aspects [8]. This dual ownership becomes especially important during incidents, where both technical fixes and business decisions need to happen quickly.
To formalise these roles, organisations can use a platform contract. This document sets boundaries for what teams can manage themselves - like namespaces or non-sensitive configurations - and what needs central approval, such as access to secrets or production-level changes [9]. Without these guidelines, teams either overstep or get bogged down waiting for approvals.
Resource tagging is another way to maintain accountability. By tagging resources with a standardised taxonomy (e.g., application name, environment, owner, business unit, cost centre) right from the start, organisations can ensure traceability [10]. Automated policies that block untagged resources during deployment help keep things organised [10][11].
A state file that spans more than one team's resources is a shared blast radius.- Olivier De Turkeim, Platform Engineer, Cycloid [4]
To avoid such risks, splitting Terraform state files by team is a smart move. For example, the networking team might handle the VPC state, while the application team manages compute resources. This division reduces the risk of conflicts and limits the impact of changes [4].
Once ownership is sorted, setting up standard workflow rules can further simplify cross-cloud operations.
Setting Standard Workflow Rules
Clear ownership is just the beginning. Consistent workflow rules ensure teams know exactly how to operate, reducing mistakes and keeping processes smooth. Agreements should cover where configurations are stored, how pull requests are reviewed, and how changes move between environments - no matter which cloud provider is in use [5].
Here are a few practices that can help:
- Pin module versions: Use exact commit SHAs or version tags, rather than floating references like
?ref=main. This ensures consistent builds across teams and over time [4]. - Automate downstream triggers: For example, provisioning a Kubernetes cluster in one cloud should automatically trigger the next step in another [5].
- Consolidate PR comments: Combine plan summaries and cross-cloud cost estimates into a single view to give reviewers all the information they need at a glance [7].
Also, ordering pipelines logically - such as Networking → VPN/Connectivity → Compute - ensures resources are referenced correctly across clouds [7].
Comparing Ownership Models
The ownership model you choose directly impacts how fast teams can work and how much oversight the organisation can maintain. Here’s a quick comparison of the common models:
| Ownership Model | Speed | Governance | Scalability |
|---|---|---|---|
| Centralised | Low (bottlenecks) | High (strict) | Low |
| Federated | High (self-service) | Medium (guardrails) | High |
| Hybrid | Medium | High (shared) | Medium |
Centralised models offer strong control but can slow things down as teams wait for approvals [2]. Federated models allow teams to move faster with self-service tools, but they require solid Policy as Code to avoid governance gaps [4]. A hybrid approach strikes a balance, with centralised teams managing baseline security and networking, while application teams have autonomy over their workloads [2].
The platform team builds the foundation. The stream-aligned teams build on top of it.- Arief Warazuhudien, DevOps Practitioner [12]
For organisations operating at scale, a hybrid model often works best. It provides flexibility while avoiding confusion, as long as a clear RACI (Responsible, Accountable, Consulted, Informed) matrix is in place to prevent misunderstandings or reliance on informal knowledge [2][13].
Shared Automation and Infrastructure Standards
Once pipeline ownership is clearly defined, shared automation standards become essential to avoid repetitive tasks across different clouds. By leveraging reusable templates and consistent tools, multi-cloud pipelines can steer clear of unique configurations that often become unmanageable at scale.
Infrastructure as Code and Reusable Templates
Creating cloud-specific Infrastructure as Code (IaC) modules ensures consistency across platforms like AWS, Azure, and Google Cloud. For instance, you could develop one module for an AWS VPC and another for an Azure VNet, all sharing a common variable interface [6][14]. While tempting, a universal abstraction layer rarely works well due to the inherent differences in each cloud provider's services.
Reusable pipeline templates also play a critical role in preventing snowflake
pipelines - those manually configured and unique to specific services. Instead, referencing a centralised, versioned template allows updates to be applied across all dependent pipelines. A great example of this is Morningstar, which reduced its pipeline management load from 36,000 individual pipelines to just 50 reusable templates - a staggering 99.8% reduction. Similarly, United Airlines cut deployment times for 3,000 engineers from 22 minutes to just 5 minutes by adopting reusable templates [17].
Tools like Terragrunt can support multi-cloud configurations while adhering to the DRY (Don't Repeat Yourself) principle. This is achieved by managing remote state and environment-specific inputs with minimal repetitive code [6][14].
Once infrastructure code is standardised, the next step is to secure artefacts and credentials.
Artefact Handling and Secrets Management
Static credentials present a significant security risk in multi-cloud CI/CD environments. For example, 54% of IaC templates in production are found to have at least one misconfiguration, and in 2024, 40% of GitHub Actions workflows were vulnerable to script injection attacks that could expose secrets [15]. To mitigate these risks, organisations can replace static credentials with OIDC federation. This approach allows CI/CD runners to request short-lived, scoped tokens (usually valid for 15 minutes) from cloud providers, reducing the chances of key exposure [15][4].
For artefact handling, best practices include using image digests (SHA256 hashes) instead of mutable tags in deployment manifests. This ensures that the exact build produced by the pipeline is deployed. Additionally, signing container images with tools like Cosign (part of the Sigstore project) ties each artefact's signature to a specific CI workflow and commit SHA, creating a verifiable chain of trust from build to production [15][16]. Kubernetes admission controllers, such as Kyverno or OPA Gatekeeper, can enforce these measures by rejecting any pod attempting to run an unsigned image [15].
Comparing Automation Practices
These automation practices combine to form a cohesive strategy that ensures consistency in provisioning, deployment, and governance across various cloud environments. Each approach serves a specific purpose, and together, they create an efficient multi-cloud CI/CD system.
| Approach | Primary Tooling | Best Fit | Key Benefit |
|---|---|---|---|
| Infrastructure as Code (IaC) | Terraform, Pulumi, OpenTofu | Provisioning foundational resources | Ensures consistent workflows across cloud APIs [5][6] |
| GitOps | Argo CD, Flux | Application delivery and drift detection | Uses Git as the single source of truth [2][4] |
| Policy as Code | OPA, Kyverno, Sentinel | Governance and compliance enforcement | Embeds automated guardrails into the pipeline [15][17] |
For organisations aiming to refine their multi-cloud CI/CD processes, expert guidance can make a significant difference. Hokstad Consulting offers tailored solutions to optimise DevOps pipelines and ensure automation standards are effectively implemented.
Improving Visibility Across Teams and Clouds
Once you've established standardised automation and shared responsibilities, the next hurdle is ensuring that every team has clear visibility across all cloud environments. Without this, problems in one cloud can go unnoticed by teams working in another, leading to expensive delays. Research highlights the stakes: infrastructure outages cost over £800,000 per hour, with high-impact incidents averaging a staggering £1.6 million per hour [19].
Centralising Monitoring and Metrics
One of the biggest challenges with multi-cloud monitoring is that native tools - like AWS CloudWatch, Azure Monitor, and Google Cloud Operations - work well within their own ecosystems but don't interact with each other. This forces engineers to manually piece together data from various consoles during cross-cloud incidents [18].
A practical way to address this is by using a hub-and-spoke architecture, where monitoring data from different accounts is funnelled into a centralised monitoring account. For instance, AWS CloudWatch offers cross-account observability, allowing teams to query metrics and logs from multiple accounts and regions on a single dashboard. Even better, there’s no extra charge for sharing data. Standard CloudWatch dashboards cost just $3 (around £2.40) per dashboard per month, making it an affordable option to start with [21].
However, for these dashboards to be effective, consistency in tagging is key. A shared tagging system - using tags like environment, team, application, and cost centre - ensures that alerts are routed correctly and costs are allocated accurately [18]. It’s a good idea to agree on these tags before adding new cloud accounts. Automating this process with tools like CloudFormation StackSets ensures that all new accounts are configured correctly from the start [21].
For teams juggling multiple CI/CD tools, the CDEvents specification provides a standardised language for pipeline events (e.g., pipelineRun.finished). This allows a single monitoring system to process data from tools like Jenkins, GitHub Actions, and GitLab CI, eliminating the need for separate integrations for each [20].
By consolidating monitoring, teams can establish a clearer picture of their systems and assign responsibilities more effectively during incidents.
Mapping Ownership for Incident Response
While dashboards provide visibility, they’re not enough on their own - clear ownership is essential for turning insights into fast, effective responses.
In a multi-cloud incident, the bottleneck isn't the tooling - it's finding someone who understands both AWS networking and Azure load balancing at 3 AM. AI agents that understand all clouds eliminate that dependency.- Noah Casarotto-Dinning, CEO at Arvo AI [25]
The table below links common signal types to their primary owners and outlines the steps they should take, creating a shared playbook for incident response.
| Signal Type | Primary Owner | Response Action |
|---|---|---|
| Cloud Control Plane Anomalies | Platform / Cloud Team | Audit IAM policy edits and network changes [24] |
| Pipeline Security Gate Failures | DevSecOps Lead | Triage vulnerabilities and enforce security gates [22] |
| Latency Spikes / Error Rates | SRE / Platform Team | Correlate signals across providers using distributed tracing [18][21] |
| K8s Workload / Pod Restarts | SRE / Platform Team | Review audit events and RBAC changes [24] |
| Secrets Manager Access Spikes | Security Team | Audit secret reads and rotate compromised keys [24] |
| Cost Anomalies | FinOps / Finance | Identify idle or oversized resources and apply right-sizing [18][26] |
Structured incident playbooks can make a big difference in reducing recovery times. For example, platform-level playbooks have been shown to cut Mean Time to Recovery (MTTR) from 38 minutes to just 12 minutes [23]. Additionally, assigning three key roles within the first five minutes of an incident - an Incident Commander to oversee the process, a Subject Matter Expert to handle the technical issue, and a Communications Lead to keep stakeholders informed - helps avoid the chaos of fragmented war rooms
[23][24].
Security, Compliance, and Change Control Rules
Once visibility and incident ownership are handled, the next step is ensuring that security and compliance controls remain consistent across all cloud environments. In multi-cloud setups, the real challenge often isn't a sophisticated attack - it’s inconsistent policy enforcement caused by slight configuration differences between clouds.
Shared Security Policies and Credential Handling
To ensure policies remain consistent, store them in Git as the single source of truth. Use OPA (Open Policy Agent) with Rego modules and apply cloud-specific renderers for provider configurations [27]. This ensures that any changes to your security rules are applied across all providers, not just within a single console.
Credential handling can be improved by avoiding static, long-term access keys. Instead, configure CI/CD runners to use OIDC federation to assume short-lived, narrowly scoped cloud roles rather than relying on static keys [32]. Pair this with a secrets manager that issues dynamic, time-limited credentials, so any exposed credentials expire quickly [29]. Also, use ephemeral CI/CD runners that are destroyed after each job to eliminate the risk of credential reuse [32].
A global financial services company operating in 50 countries implemented this by adopting a Terraform-based IaC strategy across AWS and Azure, integrating OPA and HashiCorp Vault. The result? A 65% reduction in time-to-deploy infrastructure and full compliance coverage for tagging and encryption enforcement [30].
These practices establish a strong foundation for embedding continuous compliance directly into your development pipeline.
Applying Governance Checkpoints
Building on secure credential practices, compliance can be integrated directly into pipelines rather than relying on post-release checks [31].
A practical framework divides controls into Gates and Warnings. Gates block deployments entirely - such as when a critical vulnerability is found or an artefact lacks a signature. Warnings, on the other hand, highlight issues that need attention but don't halt the pipeline [31]. This approach balances release speed with risk management, ensuring high-priority risks are addressed before reaching production. The table below outlines where these controls fit within the delivery pipeline:
| Stage | Control / Check | Evidence Artefact |
|---|---|---|
| Code / PR | Protected branch + approvals | PR approvals + review timeline |
| CI | Security scans (SAST/SCA) | Scan reports + policy decision |
| Build | Reproducible build | Build metadata + lockfiles |
| Artefact | Signing + provenance | Artefact digest + signature |
| Deploy | Environment policy + approvals | Deployment record + approval event |
| Access | RBAC changes tracked | IAM audit log entries |
Source: [31]
For teams managing multiple cloud accounts, centralised guardrail
factories can be a game-changer. These are automated project or folder factories that enforce organisational policies and IAM roles whenever a new team or project is onboarded [28]. When combined with IaC-based provisioning, this approach has been shown to reduce configuration drift incidents by 90% over six months [30]. This directly leads to fewer compliance issues and more predictable deployments.
Conclusion: Key Takeaways for Multi-Cloud CI/CD Collaboration
Building effective multi-cloud CI/CD collaboration hinges on consistent practices that focus on standardisation, automation, visibility, and governance. Research highlights the benefits: teams that collaborate effectively can achieve daily or on-demand deployments, while siloed teams often lag behind with monthly releases. Additionally, change failure rates drop significantly - from 60% to as low as 15% - when cloud-agnostic tools replace provider-specific silos [2].
To unlock these advantages, having a clear and reusable CI/CD process is crucial. A Golden Path
- which includes standardised pipelines, Infrastructure as Code (IaC) templates, and ephemeral environments - minimises context switching, simplifies onboarding, and ensures consistency across different cloud providers [1][33]. Organisations can strengthen these practices by establishing a dedicated platform team or a Cloud Centre of Excellence (CCoE) [2].
Governance plays a pivotal role too. Centralising identity management through a single provider and codifying compliance rules as Policy as Code - with tools like OPA or Kyverno - turns governance into a strategic enabler rather than a roadblock [34]. These measures not only streamline workflows but also help turn organisational challenges into competitive strengths.
Ultimately, the gap between struggling and thriving teams lies in organisational discipline, not technical hurdles. By defining shared standards, automating compliance, and making the optimal path the easiest to follow, organisations can achieve faster deployments and stronger security - cornerstones of successful multi-cloud CI/CD collaboration.
For further guidance on improving multi-cloud CI/CD collaboration, check out Hokstad Consulting.
FAQs
How do we create a “Golden Path” that still allows team flexibility?
To strike a balance between guiding teams and allowing flexibility, design the golden path as a recommended, optional route rather than a strict rule. Make it the simplest and most efficient option by providing pre-tested templates, secure defaults, and automated pipelines to cut down on manual work. Teams are free to take alternative approaches, but they'll need to handle their own support and security challenges if they do. Maintain a shared catalogue to document exceptions and use this feedback to improve and adjust the golden path over time.
What’s the simplest way to replace static cloud keys with short-lived CI/CD credentials?
The easiest approach is to implement workload identity federation using OpenID Connect (OIDC). This method swaps out long-term keys for short-lived, scoped credentials. During a pipeline run, your CI/CD platform creates a cryptographically signed JSON Web Token (JWT). The cloud provider then verifies the JWT and issues temporary credentials that are valid solely for that specific job. This not only reduces the need for frequent secret rotations but also helps minimise the risk of credential leaks.
How can we get one view of incidents and costs across AWS, Azure and GCP?
To manage incidents and costs effectively across AWS, Azure, and GCP, start by centralising both observability and financial data.
For cost management, implement a consistent tagging strategy based on five key dimensions: environment, owner, service, cost centre, and workload type. Once tagged, aggregate this information into a reporting layer or standardise it using the FinOps Open Cost and Usage Specification (FOCUS) framework for better consistency.
When handling incidents, bring all logs and metrics together on a unified platform like Grafana or Datadog. This approach ensures seamless monitoring and troubleshooting across multiple cloud providers.